




导读:
大数据平台的运维保障一直是业界尤为关心的话题。今天就由hiker同学为大家带来网易有数平台运维保障建设心得,从数据平台应用现状出发,展示EasyOps平台优质的功能特性。
背景
早期的网易有数平台通过ambari作为大数据底层管理平台,基于ambari做了很多定制化开发,比如通过ambari集成其他服务组件。但随着hdp跟cdh合并后并且收费,ambari社区也停止维护了。ambari管控平台在同时管理几百上千台服务器,会存在很多性能层面的问题,例如页面响应慢,集群监控指标比较大,导致监控经常看不到数据,ambari相对于中台服务之间集成,运维,以及升级难度比较大,因此内部开始自研大数据管控平台。
运维痛点
集成服务太多,平台运维人员无法掌握相关服务的运维操作命令;
组件频繁配置变更,如果说修改hdfs参数,下游依赖的大数据组件,中台组件相应参数变更;
集群监控指标不全,运维人员无法通过指标排查集群问题;
数据链路比较长,运维无法定位相关故障点;
集群组件升级频繁,小版本升级,大版本升级。
EasyOps管控平台
EasyOps是网易有数旗下一个含括部署、监控、报警、运维为一体的自动化运维管理平台。目前管理着网易有数所有服务,并为其提供准确、实时的监控报警。
3.1 功能阐述
(1)解决部署工具无法适配复杂架构的问题,譬如多集群管理、服务实例混合部署等
easyops支持管控多个集群,比如说一个easyops同时管控离线集群,实时集群,hbase集群等,另外像支持双集群部署,比如数据沙箱集群同时访问生成数据,并且一套集群中支持部署多个组件,例如集群中部署依赖kerberos的zookeeper跟不依赖kerberos的zookeeper集群,这一点是当前主流管控平台不支持。
(2)提供集群部署、监控、升级等自动化运维操作,提升运维效率
当前easyops已经完成对每个大数据组件页面化部署,对服务组件的启停,修改配置,组件跨版本升级,以及支持配置集群多配置组功能,对一些组件比如impala,yarn,datanode实现滚动重启。另外集成部署的每个组件指标进行采集,汇总,计算,最终形成dashboard展示到前端。
(3)产品化的底层数据接口,服务数据中台
像一些主流的组件hdfs/yarn/hive/impala等常用组件,其他比如kerberos/ldap/ranger等全套大数据权限管控框架,还有knox/nginx/redis/kong这些大数据周边组件都已经完全集成,另外针对大数据上层服务,比如数据地图,数据传输,数据资产等配套组件。
(4)支持原地升级HDP集群到Easyops
目前像网易有数早期通过amabari部署的集群,支持将该集群原地升级到easyops集群中,这样省去了用户去重新部署集群,迁移数据,迁移任务等操作。
3.2 详细介绍
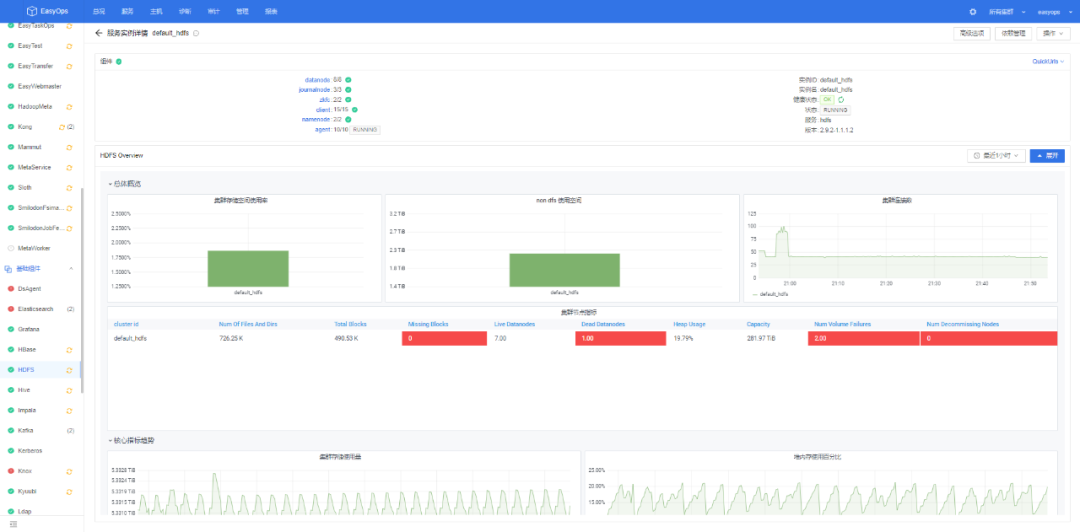
左边主要分3部分:
中台组件:azkaban/Mammut/EasyMetahub/EasyTransfer等30个组件;
基础组件:hdfs/yarn/hive/redis/nginx/kyuubi等20多个组件;
监控组件:主要对每个服务监控采集agent。
右边主要是组件的详情,健康状态,每个组件子服务部署详细拓扑结构,jvm,rpc等常规指标,能够通过这个页面直观的反映组件的健康状态。
3.3 配置变更

支持多配置组
对于datanode/nodemanager/impalad这些组件,由于当前节点磁盘,内存差异或者批量节点单独配置,例如将impalad节点做coodinator跟executor分离,因此需求按照分组管理当前节点。
保留配置变更记录,支持配置快速回滚操作
支持配置透传
配置页面目前支持常规参数变更,但是对于不常用的配置可以通过添加高级选项方式传入配置中。
滚动重启
对于一些组件如果datanode,nodemanager这些组件实现滚动重启,以及节点服务一键拉起服务。
3.4 组件自动化升级
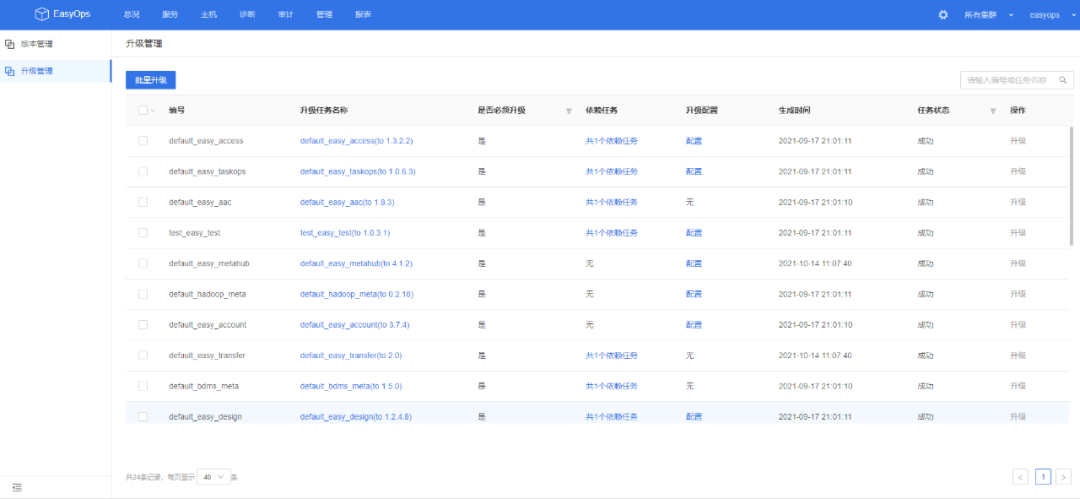
单一组件升级
目前支持添加特定服务版本,点击组件变更,页面直接对相关组件做滚动升级操作;
中台服务组件批量升级
对于网易内部中台服务存在服务比较多,服务版本相互依赖,版本迭代频繁导致组件升级困难,针对这种情况,内部做了批量升级操作,通过页面快速实现大版本升级,以及update(多个组件)升级,节省了运维误操作的风险,以及时间。
EasyOps总体设计架构
4.1 管控Docker编排、部署和管理服务
目前easyops都是通过docker化部署:并且集成prometheus/grafana监控组件。
easyops-gateway
easyops-frontend
easyops-alarm
easyops-manager
easyops-manual
easyops-grafana
easyops-ansible
easyops-prometheus
easyops-db
4.2 支持模板化部署
4.3 设计架构
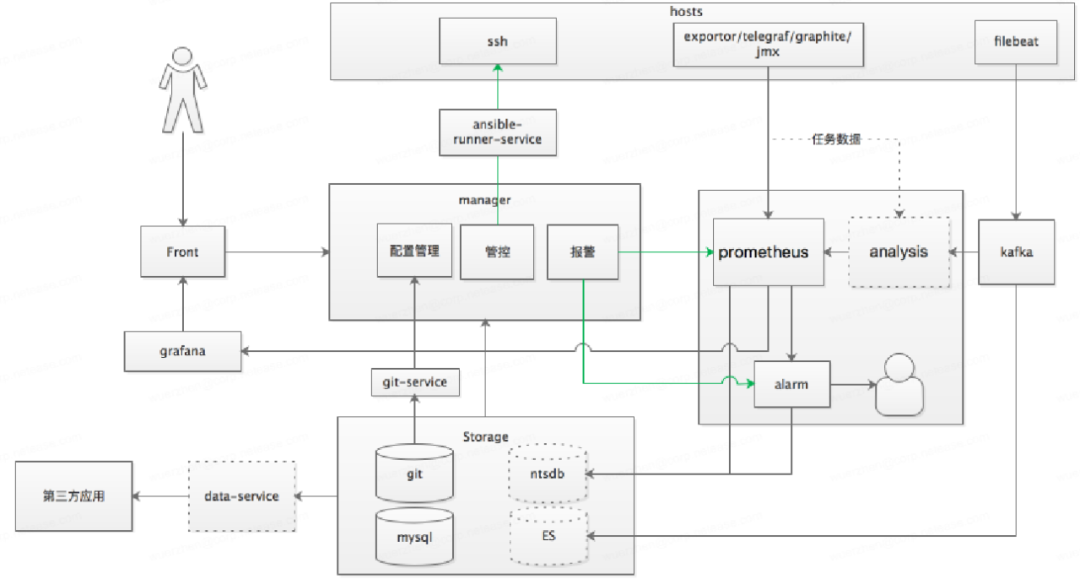
ansible:运维配置管理工具
ansible-runner :基于ansible封装后的自动化工具
ansible-runner-service:提供基于ansible-runner的REST API访问接口
4.4 Easyops后端集成代码块
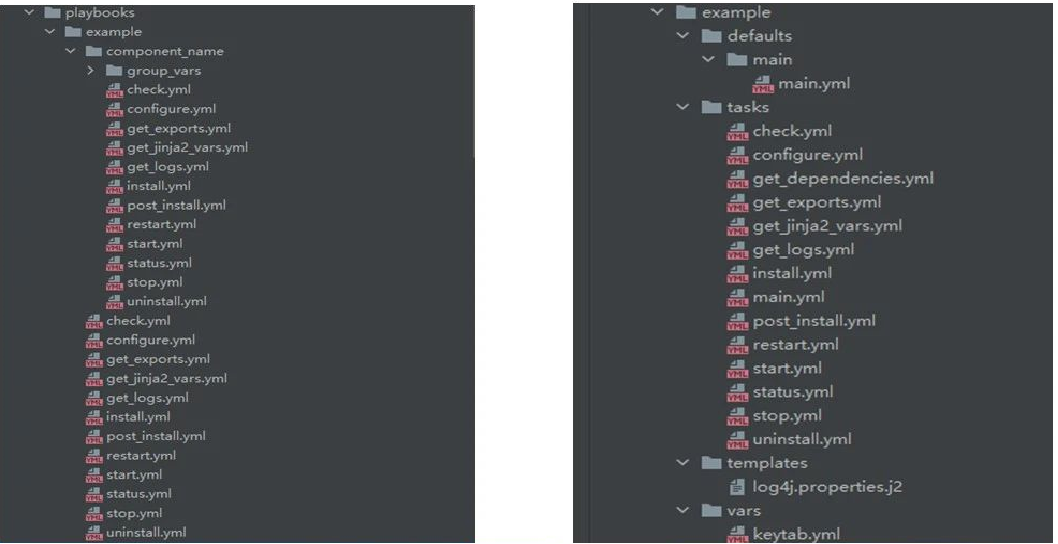
roles下以服务名创建目录,目录下创建defaults,tasks,templates,vars目录;
defaults:用于存放默认的变量值,必须创建main.yml文件,调用role时会自动加载;
tasks: 所有的任务脚本存放的目录,必须创建main.yml,当调用role时,会调用main.yml;
templates: 用于存放templates模板,生成配置文件;
vars: 用于存放动态的变量值,需要include对应的变量文件才会加载。
4.5 easyops管理集群难点
问题一:大批量节点操作时引发ansible-runner-service瞬时高负载,而拒绝超载请求
例如:当有100个datanode需要重启,或者50个nodemanager需要扩容,会提交对应数量的ansible-runner调用,瞬间系统负载升高,同时超过默认events数的请求被拒绝。
优化方案:
资源充足前提下,提高event_threads 对应地调大ansible容器资源reservations
将1个操作请求封装到1个ansible调用,即操作集简化与合并;
服务个数是有限的,服务的组件实例数是无限的,批量的组件操作请求以服务为单位封装;
将多个component操作合为一个,重写genInventory。
问题二:EasyOps操作最终是调ansible playbook,为playbook生成运行时的inventory,当前inventory内容过多,尤其在服务与组件实例过多的情况下inventory变得很大,其创建、分发、查询都受影响。
内容量不可控部分:
(1)dependency_service 集:随依赖服务变多而变大;
(2)hosts 集:随集群规模增大而变大;
(3)jinja2_vars 集:随hosts集增大而变大;
(4)exports 集:导出文件不多、内容不大也还好;
优化方案:
(1)操作哪些组件实例生成哪些实例inventory
hosts下面只生成我们操作的那些组件实例的inventory,不是全打上去,比如只操作其中1个dn,那hosts下面只有该dn和本机上依赖服务的inventory内容
(2)按操作类型使用不同生成策略
主要对于控制类操作(服务的启动、停止、重启,组件的启动、停止、重启),不加入dependency_service段,不加入jinja2_vars段(考虑也使用start_all批量操作)
(3)同一组件抽出公共inventory
同一组件类型的各实例(如HRegionServer)inventory大多内容一样,仅带有instance_id部分不同,以及个性化配置项
优化办法是从hosts下所有组件实例的内容段中抽出一个公共段vars 与hosts同级,集群规模越大 能减少越多相同行(基于1个配置组提取公共vars)
4.6 告警采集模块
EasyOps针对所管理的服务监控,根据服务的类型,会使用不同的指标采集方式以达到监控、报警的目的。
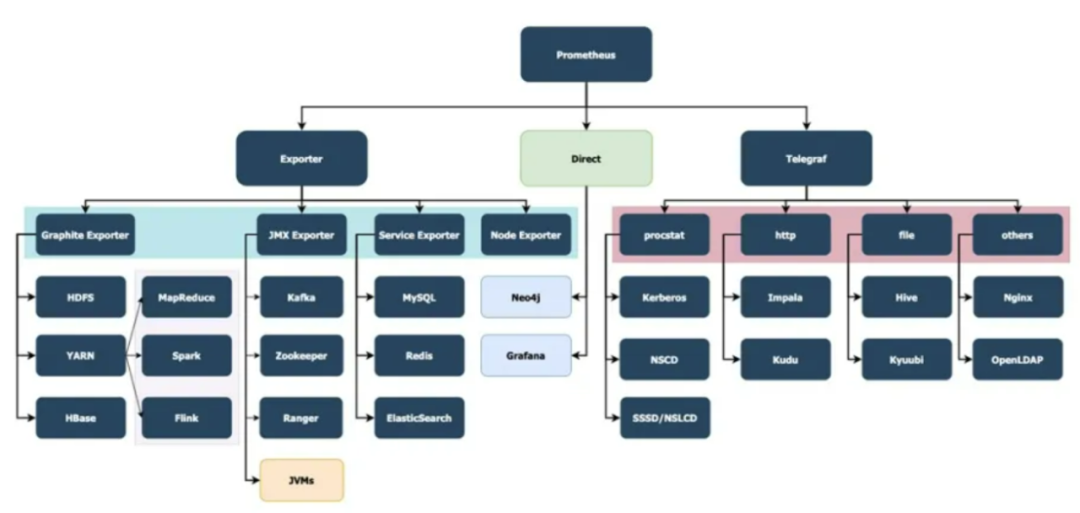
按照采集器类型进行相关介绍主要有Exporter采集,Telegraf采集,Javaagent采集;
Exporter采集
使用此类采集方式的服务主要如下:
HDFS
Yarn
Hbase
Redis
Spark2-task
ElasticSearch
MySQL
Node
万象
此类采集主要使用社区的开源方案,并在各类exporter上进行相关定制化开发。
exporter主要功能是将服务的指标数据按照配置规则解析成对应的数据格式,以供prometheus进行数据存储。
Telegraf采集
使用此类采集方式的服务如下:
Hive(metastore以及hiveserver2)
Ldap
Kerberos
Nginx
Kyuubi
Impala
Telegraf采集主要是根据服务的指标数据文件(需要更改相对应的服务配置文件,进行指标数据的输出)、暴露的指标接口等,对数据按照配置规则解析成对应的数据格式,以供prometheus进行数据的存储。
JavaAgent采集
使用此类采集方式的服务如下:
Zookeeper
BDMS_Meta
Meta_Service
Hadoop_Meta
Hadoop_Meta
Mammut
MapReduce2_historyServer
Spark2_historyServer
JavaAgent采集主要是针对java的一些web项目。JavaAgent不能作为一个独立的进程启动,需要将对应的jar以及解析文件所在路径写在上述服务运行的启动脚本中。此类采集方式获取的数据较少,均是jmx数据,无业务相关指标数据。
4.7 告警存储模块
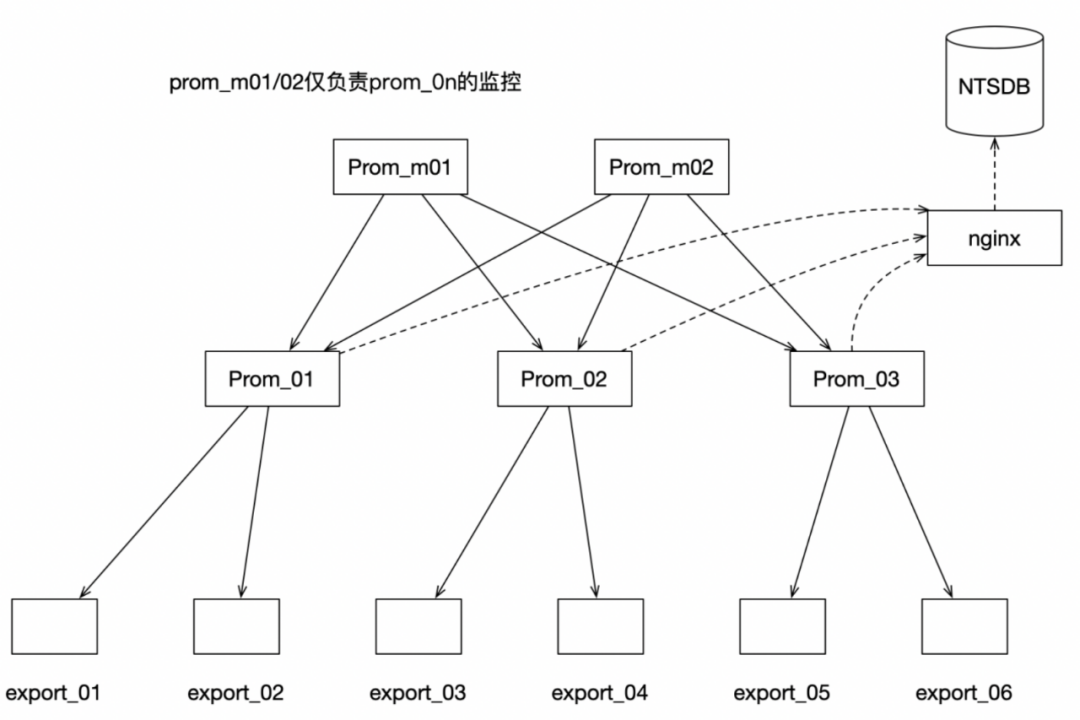
Prom_m01/02:仅监控prom_0n的状态数据,不拉取各个prom_0n所存储的监控数据。如果监控的prometheus子服务挂掉,会触发生成相同配置的子服务逻辑,保证其子服务的高可用
Prom_0n:按照实例功能进行分区,采集对应实例的监控数据
nginx:由于prometheus写入远程数据源时,仅能连接存储节点。内部NTSDB已实现高可用,一个实例有多个存储节点,使用nginx做转发和负载均衡
NTSDB:所有prom_0n均使用远程数据源,写入NTSDB
以上架构解决了如下问题:
增强了扩展性:目前采集按照实例划分,不同的prometheus子服务负责不同的采集实例,可以横向扩展
数据统一存储,不重复
数据的高可用
解决单点问题:目前数据的查询直接从NTSDB端进行
数据降维:利用NTSDB的CQ功能,实现了数据的降维处理
不需引入、维护其他组件:不需要引入对象存储服务以及维护Gossip
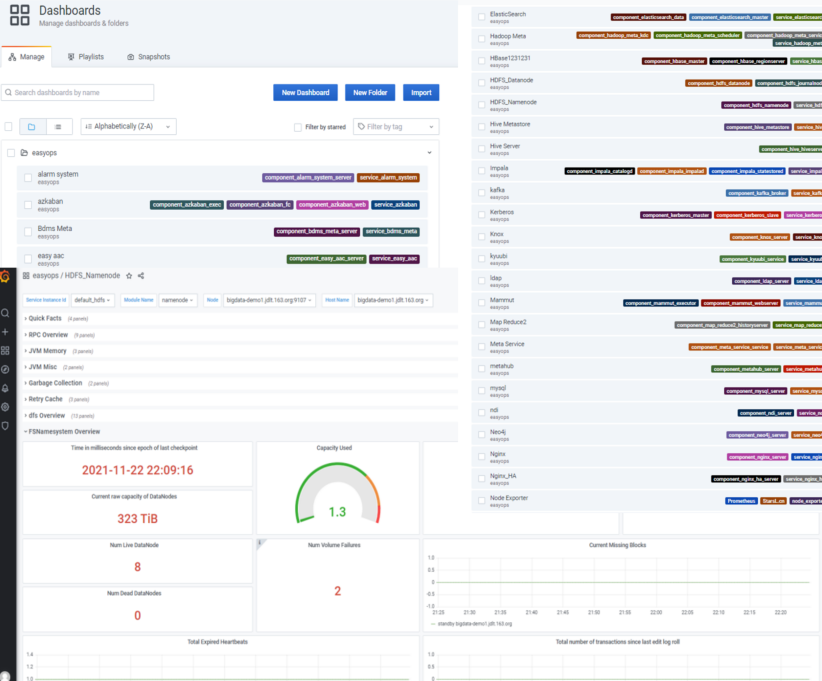
4.8 告警指标展示模块
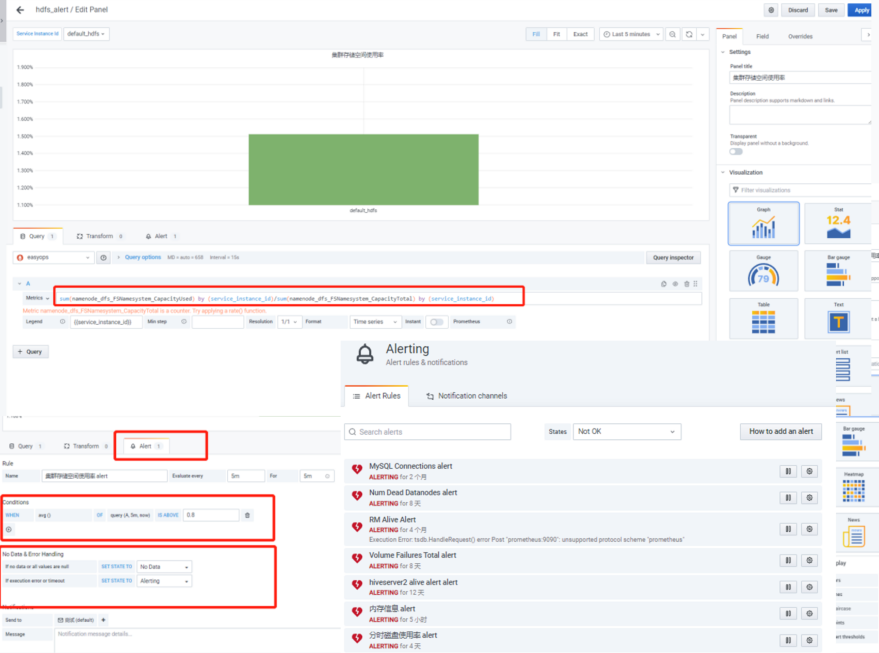
目前通过grafana上配置dashboard展示每个组件的相关指标;
4.9 告警推送模块
grafana页面自定义的alert模块,方便对集群通用性指标加监控
告警推送渠道:Dingding,webhook,Email...
操作简单,易用,方便移植
总结
目前Easyops在整个大数据运维平台上功能已经满足日常需要,后期还需要细化一些指标告警模块:
(1)支持CDH相关版本接管升级;
(2)集成业界主流组件,形成一站式管理运维工具;
(3)适配主流的云存储方案,包括s3/obs/oss等;
(4)集成spark/flink/MR任务分析,以及HDFS读写延迟,YARN调度延迟等异常诊断和异常告警。
以上就是本期分享的全部内容了,谢谢大家。
hiker,网易数帆大数据运维工程师,网易商业化对外大数据集群运维保障,主要负责外部客户集群容量评估、故障排查、集群变更等。

