




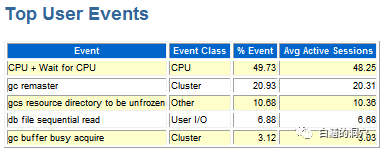
总体Load达90%,大批进程使用CPU为100%,等待队列达80-100个,如下所示
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 11636 oracle 25 0 200g 2.2g 2.2g R 100.0 0.4 13:18.11 oracle 12250 oracle 25 0 200g 1.1g 1.1g R 100.0 0.2 6:53.40 oracle 27197 oracle 19 0 200g 723m 712m R 100.0 0.1 3:47.95 oracle 11416 oracle 25 0 200g 2.2g 2.2g R 100.0 0.4 6:30.82 oracle 12470 oracle 25 0 200g 4.0g 4.0g R 100.0 0.8 48:27.03 oracle ...... |
因为数据库负载太高,Weblogic在无法正常连接数据库后,反应到最终客户端就成了系统无法连接上,不能正常使用。由于EMSPDA数据采集系统已经连续多日出现性能问题,影响业务运作,以及临近双11快递业务高峰期,因此客户希望尽快能够解决问题。

错误的将OPERATION_TIME字段放在了第一位,由于该表是按OPERATION_TIME做时间分区的,MAIL_CODE的选择性很高,使用OPERATION_TIME过滤后还是一整天的数据,作为第一个索引字段效果不好,而MAIL_CODE是一个邮件的编码,字段选择性十分好,大了的SQL的WHERE条件里仅针对MAIL_CODE进行过滤,并没有OPERATION_TIME这个过滤条件。此类问题在数据库中大量存在,是引发性能问题的重要原因之一。
Thu Aug 29 21:42:20 2013 Reconfiguration started (old inc 190, new inc 192) List of instances: 1 2 (myinst: 1) Global Resource Directory frozen Communication channels reestablished Master broadcasted resource hash value bitmaps Non-local Process blocks cleaned out Thu Aug 29 21:42:20 2013 LMS 4: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Aug 29 21:42:20 2013 LMS 3: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Aug 29 21:42:20 2013 LMS 1: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Aug 29 21:42:20 2013 LMS 5: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Aug 29 21:42:20 2013 LMS 0: 1 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Aug 29 21:42:20 2013 LMS 2: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Set master node info Submitted all remote-enqueue requests Dwn-cvts replayed, VALBLKs dubious All grantable enqueues granted Thu Aug 29 21:42:40 2013 Submitted all GCS remote-cache requests Fix write in gcs resources Thu Aug 29 21:42:50 2013 Reconfiguration complete Thu Aug 29 21:45:07 2013 Reconfiguration started (old inc 192, new inc 194) List of instances: 1 2 (myinst: 1) Global Resource Directory frozen Communication channels reestablished Master broadcasted resource hash value bitmaps Non-local Process blocks cleaned out Thu Aug 29 21:45:07 2013 LMS 4: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Aug 29 21:45:07 2013 LMS 3: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Aug 29 21:45:07 2013 LMS 2: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Aug 29 21:45:07 2013 LMS 0: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Aug 29 21:45:07 2013 LMS 5: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Thu Aug 29 21:45:07 2013 LMS 1: 0 GCS shadows cancelled, 0 closed, 0 Xw survived Set master node info Submitted all remote-enqueue requests Dwn-cvts replayed, VALBLKs dubious All grantable enqueues granted Thu Aug 29 21:45:29 2013 Submitted all GCS remote-cache requests Fix write in gcs resources Thu Aug 29 21:45:40 2013 Reconfiguration complete |
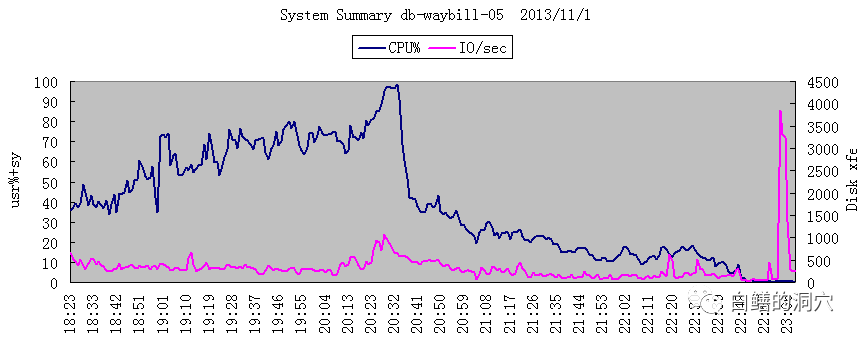
11月1日优化前的CPU使用情况
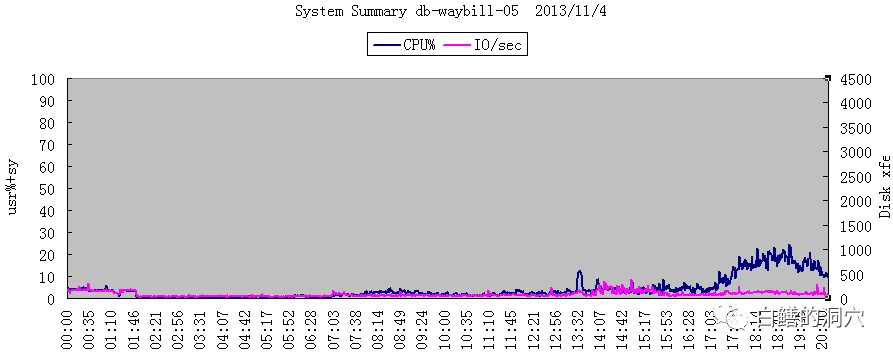
11月4日优化后的情况
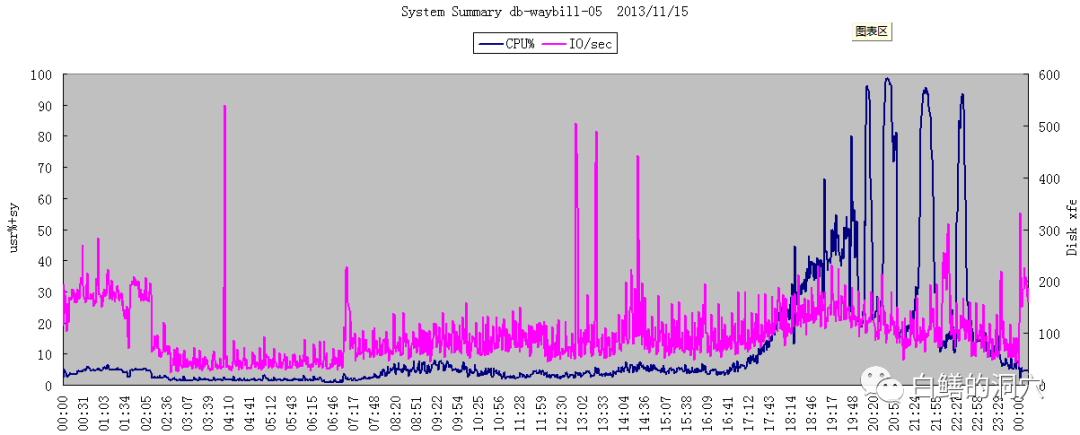
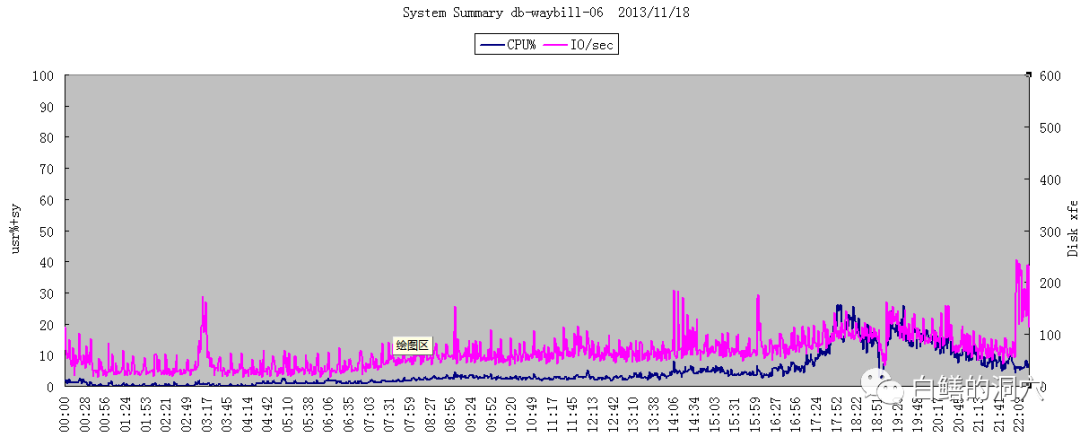
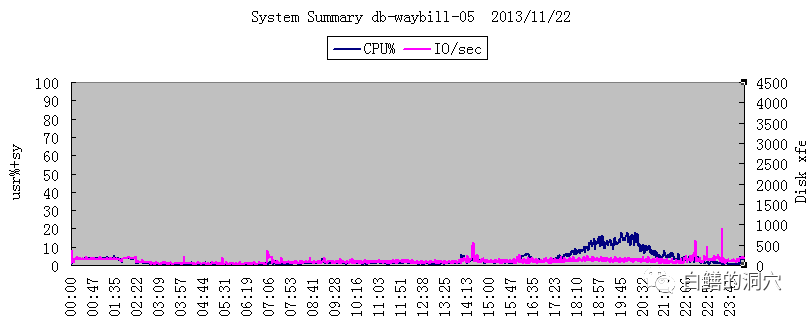
在CPU负载从接近100%下降到15%左右后,系统的事务处理能力还得到了3.18倍的提升
指标名称 | 优化前 | 优化后 | 提升倍数 |
2013/10/31 19:00-20:00 | 2013/11/22 19:00-20:00 | ||
Transactions S | 13.1 | 41.4 | 3.18倍 |
