




前言
学习TiDB的时候,我发现它的生态工具挺多的。个人感觉很多源自于日常工作和学习的一些小创意,然后在把这些创意开发出来。因为是开源软件,所以相当于是让普通人也一起参与了创新。就像今天和明天举办的hackathon
大赛,我身边的两个小伙伴已经报名参加了,

hackathon
最后一个赛道的符号特别好,是古希腊哲学家亚里士多德提出的无穷大
。意味着创意不受任何限制,任何Cool idea
都可以参与。
我身边两个小伙伴,他们做的图形化巡检工具,其实也有我的一点小idea在里面。也希望他们能获得一个好成绩。
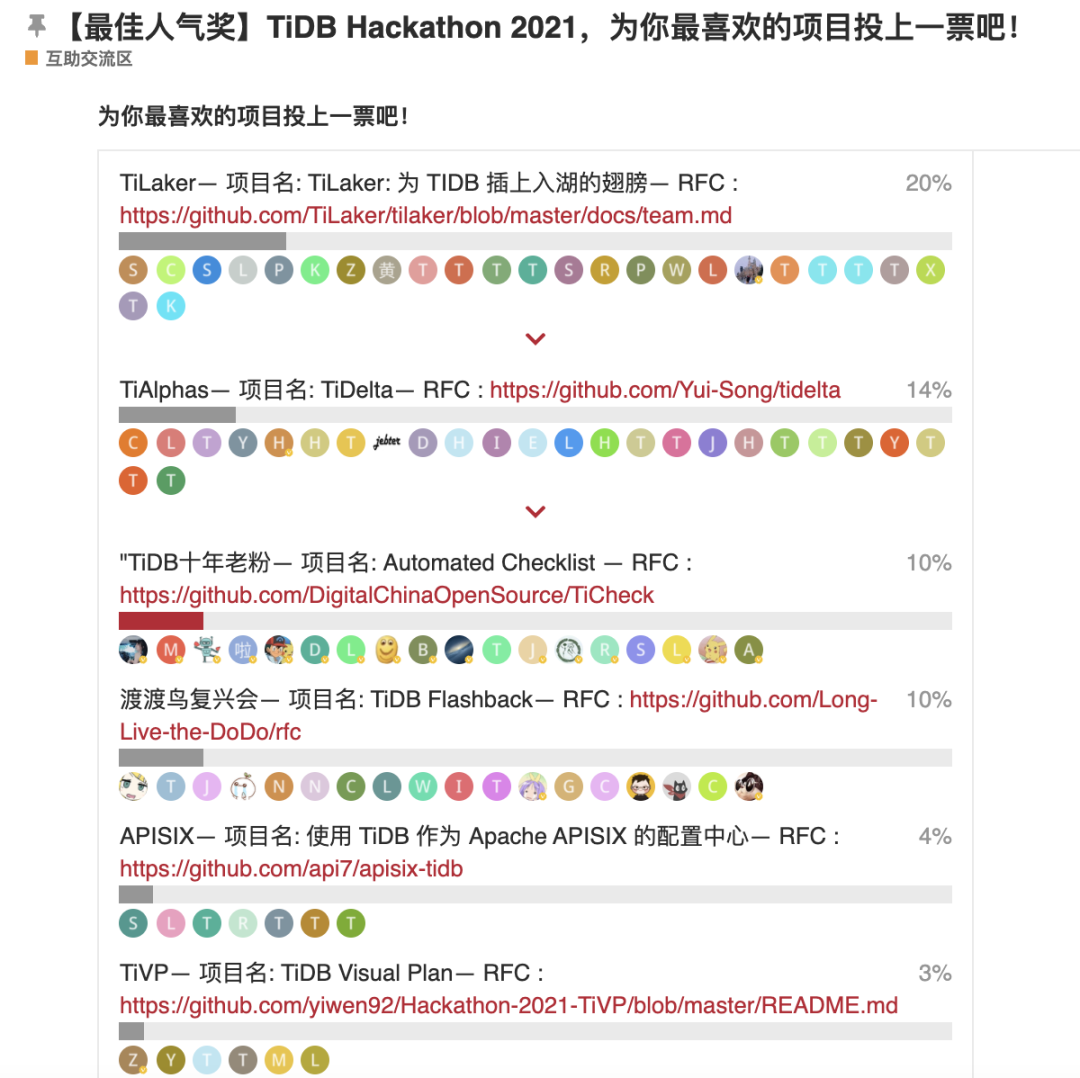
看看榜一的项目,觉得还是挺有想法的。

正是由于hackathon
这样的比赛和选手在TiDB上的创新,才得以你在使用TiDB的时候,有各种各样得心应手的工具。
正如华东师范大学周傲英教授说的那句话:“以前是教授创新,后面发现是万众创新”

生态工具
今天我们主要介绍的还是官方文档中出现的生态工具。
TiUP
这个工具是我们日常使用最多的工具,也是整个集群的管理工具。因为TiDB是分布式数据库,所以在安装、配置、管理的时候,如果你不用TiUP
,你需要登陆到每台机器上去维护,可想而知是有多么的麻烦。
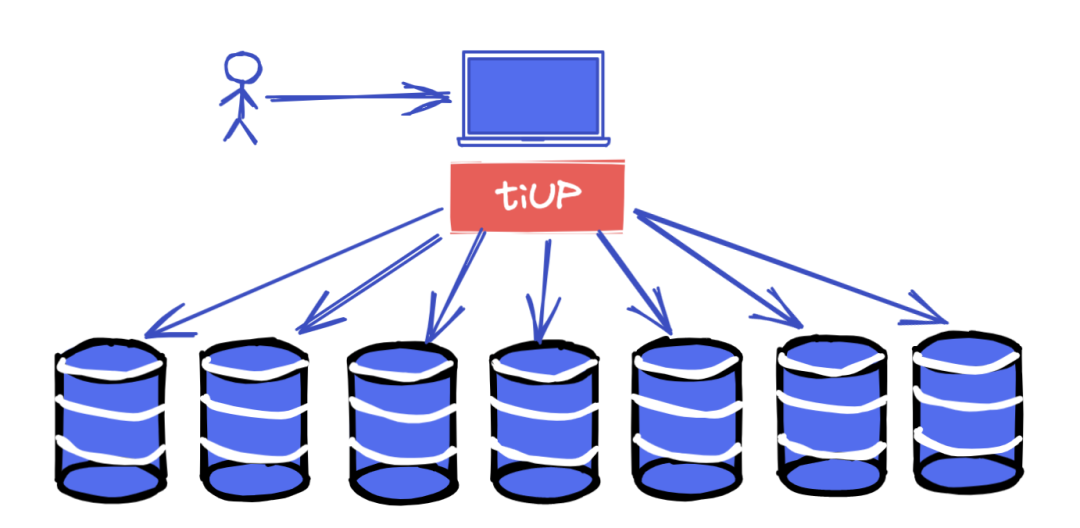
在4.0版本之前,集群的管理和维护使用的是Ansible
来实现的。而在4.0之后都转到TiUP上来了。
[root@copy-of-vm-ee-centos76-v1 ~]# tiup -help
TiUP is a command-line component management tool that can help to download and install
TiDB platform components to the local system. You can run a specific version of a component via
"tiup <component>[:version]". If no version number is specified, the latest version installed
locally will be used. If the specified component does not have any version installed locally,
the latest stable version will be downloaded from the repository.
Usage:
tiup [flags] <command> [args...]
tiup [flags] <component> [args...]
Available Commands:
install Install a specific version of a component
list List the available TiDB components or versions
uninstall Uninstall components or versions of a component
update Update tiup components to the latest version
status List the status of instantiated components
clean Clean the data of instantiated components
mirror Manage a repository mirror for TiUP components
telemetry Controls things about telemetry
env Show the list of system environment variable that related to TiUP
help Help about any command or component
completion generate the autocompletion script for the specified shell
Components Manifest:
use "tiup list" to fetch the latest components manifest
Flags:
-B, --binary <component>[:version] Print binary path of a specific version of a component <component>[:version]
and the latest version installed will be selected if no version specified
--binpath string Specify the binary path of component instance
--help Help for this command
--skip-version-check Skip the strict version check, by default a version must be a valid SemVer string
-T, --tag string [Deprecated] Specify a tag for component instance
-v, --version Print the version of tiup
Component instances with the same "tag" will share a data directory ($TIUP_HOME/data/$tag):
$ tiup --tag mycluster playground
Examples:
$ tiup playground # Quick start
$ tiup playground nightly # Start a playground with the latest nightly version
$ tiup install <component>[:version] # Install a component of specific version
$ tiup update --all # Update all installed components to the latest version
$ tiup update --nightly # Update all installed components to the nightly version
$ tiup update --self # Update the "tiup" to the latest version
$ tiup list # Fetch the latest supported components list
$ tiup status # Display all running/terminated instances
$ tiup clean <name> # Clean the data of running/terminated instance (Kill process if it's running)
$ tiup clean --all # Clean the data of all running/terminated instances
Use "tiup [command] --help" for more information about a command.
当然TiUP
还支持安装各种组件,通过安装这些对应的组件,从而集成更多的命令。
[root@copy-of-vm-ee-centos76-v1 ~]# tiup list
Available components:
Name Owner Description
---- ----- -----------
PCC community A tool used to capture plan changes among different versions of TiDB
bench pingcap Benchmark database with different workloads
br pingcap TiDB/TiKV cluster backup restore tool
cdc pingcap CDC is a change data capture tool for TiDB
client pingcap Client to connect playground
cluster pingcap Deploy a TiDB cluster for production
ctl pingcap TiDB controller suite
dm pingcap Data Migration Platform manager
dmctl pingcap dmctl component of Data Migration Platform
errdoc pingcap Document about TiDB errors
pd-recover pingcap PD Recover is a disaster recovery tool of PD, used to recover the PD cluster which cannot start or provide services normally
playground pingcap Bootstrap a local TiDB cluster for fun
tidb pingcap TiDB is an open source distributed HTAP database compatible with the MySQL protocol
tidb-lightning pingcap TiDB Lightning is a tool used for fast full import of large amounts of data into a TiDB cluster
tiup pingcap TiUP is a command-line component management tool that can help to download and install TiDB platform components to the local system
TiDB Operator
TiDB Operator 是 Kubernetes 上的 TiDB 集群自动运维系统,它可以自动执行与操作 TiDB 集群相关的任务。
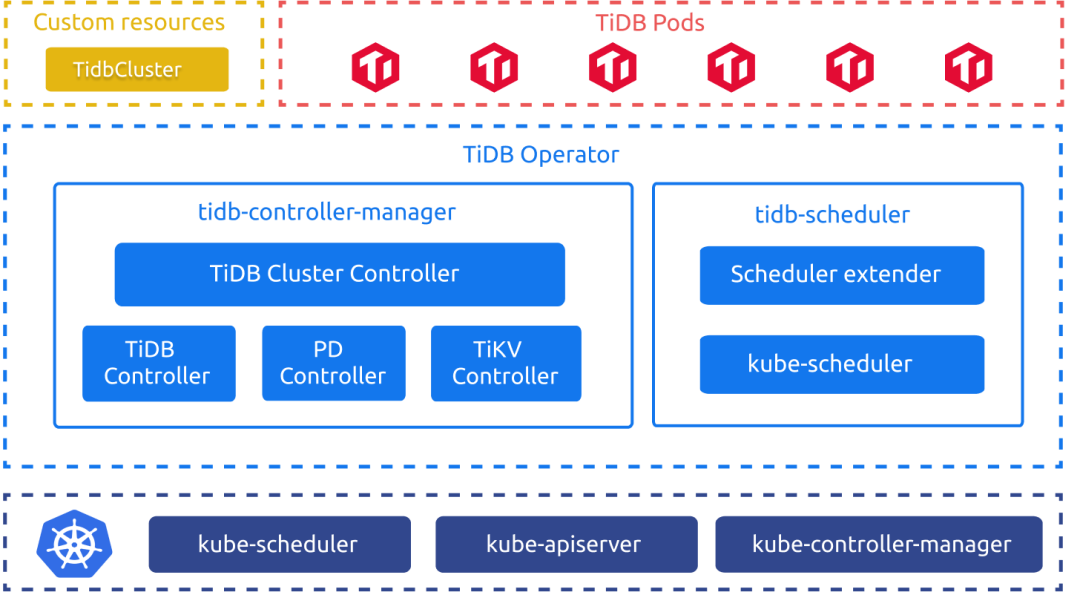
目前我尚未接触这种环境,有机会还是要玩一下。
Dumpling
这个工具必须强烈安利
给大家,它不仅仅能导出TiDB数据,它还能导出MySQL。它可以导出成SQL或者是CSV格式。因为可以导成CSV格式,它非常适合导出MySQL然后加载到一些列存的数据库,例如Clickhouse、GreenPlum。Dumpling 也支持将数据导出到 Amazon S3 中。有一次我有一个朋友用mysqldump导出一个数据量很大几十亿的MySQL库,运行一段时间会崩溃中断。我推荐它试了一下Dumpling
,竟然很快就能导出来。据说速度大概能达到280MB/S
。
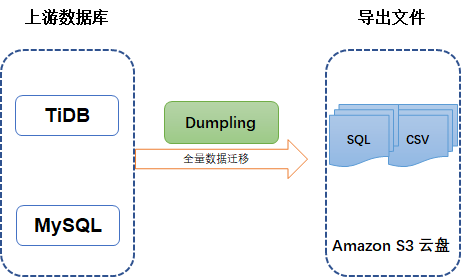
Dumpling
在日常最重要的功能就是做逻辑备份,当数据量不是特别大的时候,选择使用Dumpling
是最佳选择。Dumpling加上Binlog也可以进行基于时间点(PiTR)的恢复。而不是像Oracle这类数据库非要使用物理备份才可以。
Lightning
TiDB Lightning
是一个将全量数据高速导入到 TiDB 集群的工具。
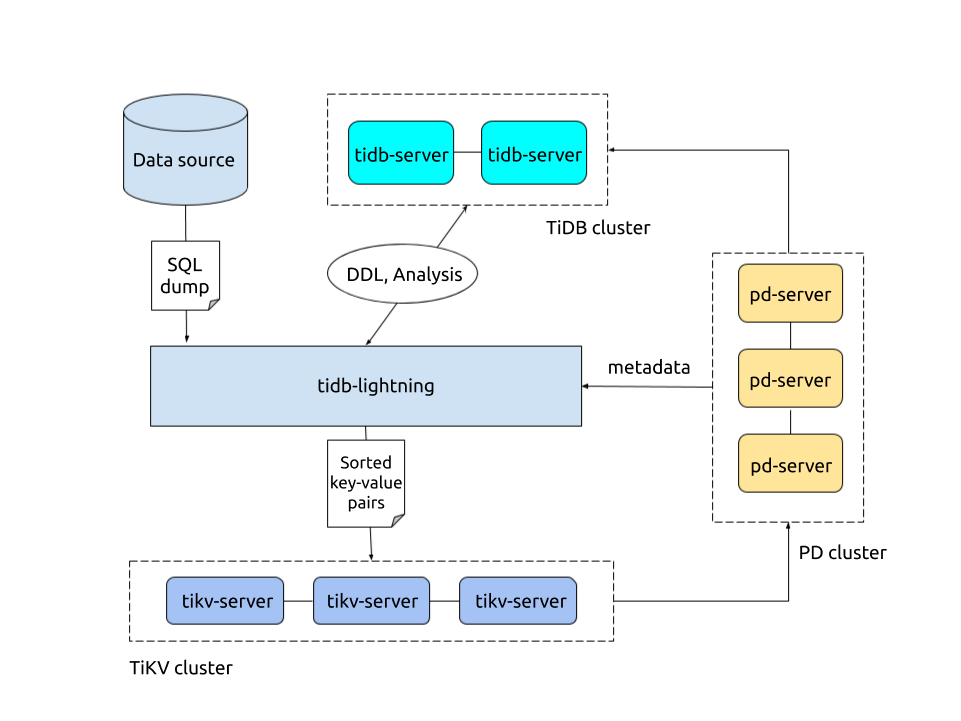
对应PostgreSQL中的pg_bulkload或者是Oracle中的impdp。它可以选择物理方式进行导入,也可以选择逻辑方式进行导入。因为TiKV底层存储的SST文件,物理方式的原理是将数据编码成键值对并排序,接着存储在本地临时目录,然后将这些键值对以 SST 文件的形式上传到各个 TiKV 节点,最后由 TiKV 将这些 SST 文件 Ingest 到集群中,这样做的好处是速度特别快,但是缺点是占用资源高、目标表必须为空、还不支持ACID,最最重要的是它影响TiDB对外提供服务。而逻辑方式直接以SQL进行导入,这样就必须经过SQL解析层,因此它是最慢的,但是它的优势是消耗资源低、且可以让目标表不为空、同时还支持ACID、不影响TiDB对外提供服务。所以我们可以按照实际需求来选择导入模式。

TiDB Data Migration
DM
是一款便捷的数据迁移工具,支持从与 MySQL 协议兼容的数据库(MySQL、MariaDB、Aurora MySQL)到 TiDB 的数据迁移。
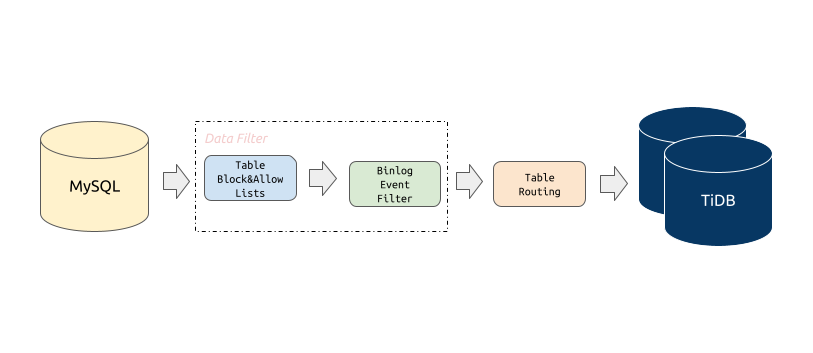
DM
可以进行黑白名单过滤(过滤指定的数据库和表)、操作类型过滤(过滤Truncate、Insert等操作)、合并路由(MySQL多个表合并)。DM
工具极大的减少了运维复杂度。
BR
BR是备份和恢复工具,如果你的数据量较大,推荐采用BR工具进行备份。
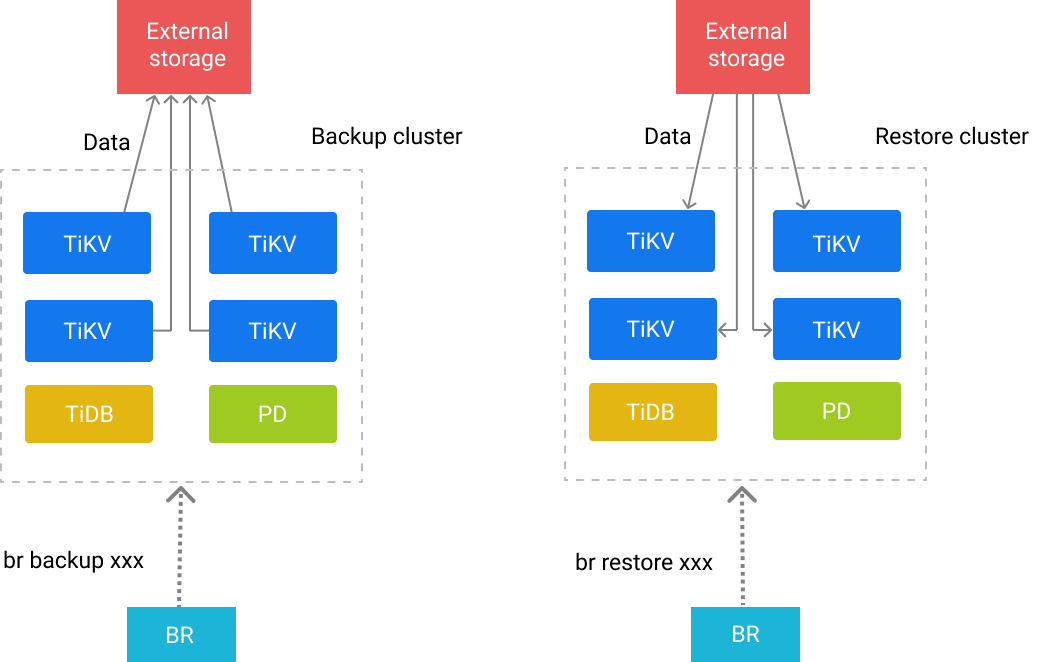
BR工具的原理,就是将备份和恢复的任务下推到TiKV
执行,然后每个TiKV上面进行简单粗暴的MVCC Scan
,然后保存成SST文件。这样备份速度就很快,你有多少个TiKV节点,这些节点就可以同时进行工作。官方有一篇博客介绍了备份和恢复速度的:如何做到 10T 集群数据安全备份,1GB/s 快速恢复?每个节点大概备份速度是700-800MB/s,这样有5个节点,基本上能达到4GB/S,而恢复速度会慢一些,大概是250MB/S,5个节点,也能达到1GB/S。
不过有一点很值得吐槽的,就是恢复的时候,每个节点都需要全部的备份数据。所以一般最好找个共享NFS来进行备份,或者是直接备份到S3这样的存储上。
TiDB Binlog
TiDB Binlog
我最开始以为和MySQL的 Binlog
一样,只是一个归档日志。但是看了一下架构,竟然多出了Pump
和Drainr
这两个组件。
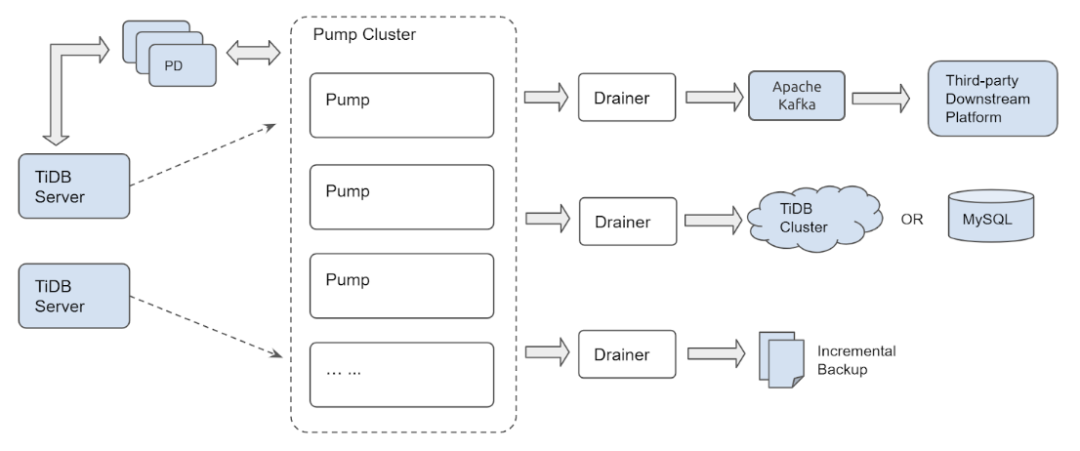
为什么需要有Pump
和Drainer
, 我的理解是因为TiDB是计算和存储层分离的架构。而存储层面主要执行的是kv操作,所以它不可能产生像MySQL一样insert、Update、Delete还有DDL的日志格式的日志。它只有kv那种put/set的操作日志。所以我们需要从计算层面入手,因此pump
组件应运而生。而TiDB节点可能有多个,这个时候我们就需要有一个组件Drainer
,把多个pump
采集的binlog
日志按照顺序进行合并,然后同步到MySQL或者是TiDB,也可以生成文件,或者投递到下游的Kafka都行。
使用Binlog
,配合dumpling
和br
就可以玩基于时间点的恢复。
TiCDC
TiCDC 是一款通过拉取 TiKV 变更日志实现的 TiDB 增量数据同步工具,它其实有点像GoldenGate
。
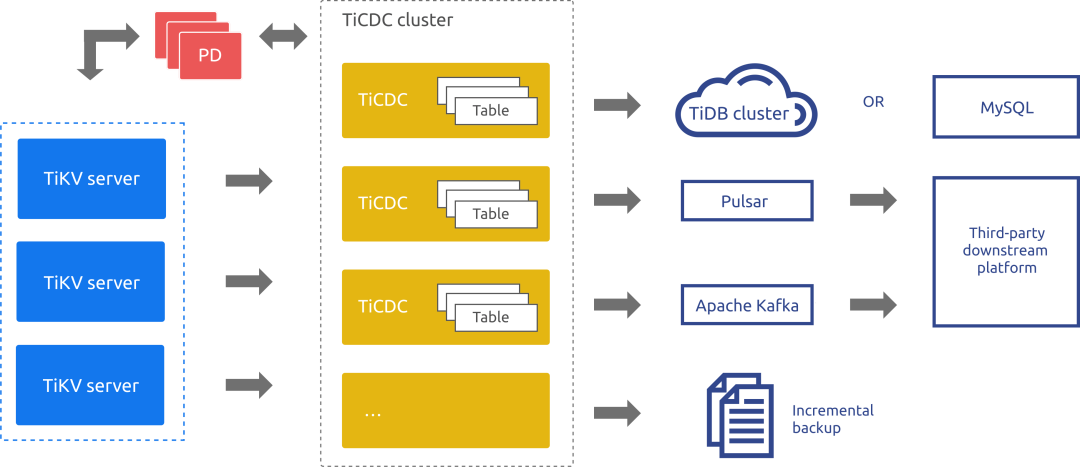
上面写Binlog的时候也说了,TiDB是存储和计算分离的架构,存储层是K/V的日志。TiCDC就是把K/V 的日志解析成SQL语句,然后在同步给下游的TiDB、MySQL或者是Kafka。个人感觉这个工具和ogg一样,有时候需要大量的人肉运维,主要是需要处理各种链路崩掉的情况。
sync-diff-inspector
这个工具主要是用于校验MySQL/TiDB 中两份数据是否一致的工具。这个工具在割接的场景中可能会用的比较多。
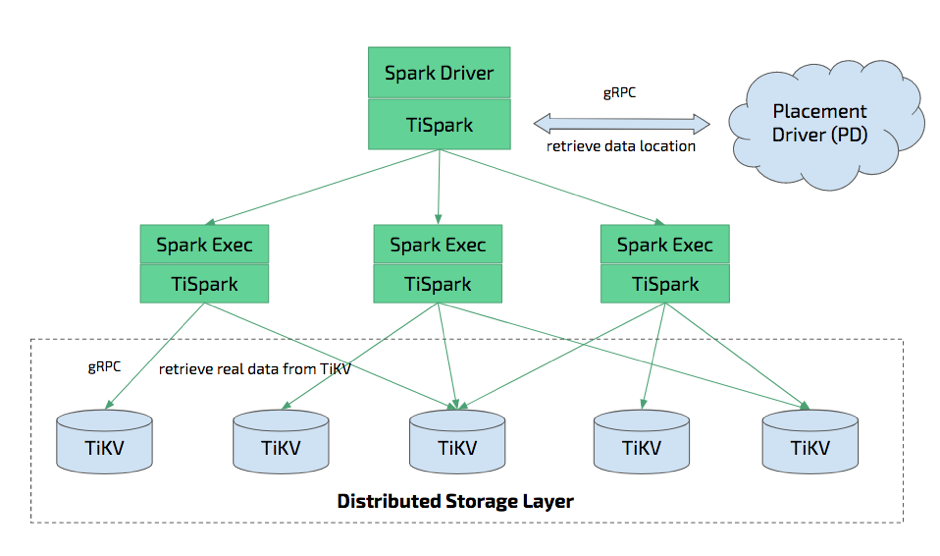
TiSpark
TiSpark 是将 Spark SQL 直接运行在 TiDB 存储引擎 TiKV 上的 OLAP 解决方案。不过现在感觉用的人已经不多了,因为很多客户都偏向使用TiFlash
了。
总结
每个数据库都有自己的工具,TiDB 也不例外。这篇文章,我们主要是科普了一下官方文档中介绍的形形色色的工具,当然还有一些是hackathon
中的工具,我们并没有更近一步介绍。这个需要你自行下去研究,就像研究PostgreSQL插件一样。
Reference
https://docs.pingcap.com/zh/tidb/stable/ecosystem-tool-user-guide
https://pingcap.com/zh/blog/tidb-binlog-open-source
https://pingcap.com/zh/blog/cluster-data-security-backup
https://asktug.com/t/topic/303958/6Optima-Reg
