




说明:本系列内容来自拉钩教育【即学即用的Spark实战44讲】课程,本人学习总结,课程链接如下:
https://kaiwu.lagou.com/course/courseInfo.htm?courseId=71
本篇文章是【即学即用的Spark实战系列】的开篇文章,将大体介绍讲师简历、Spark起源,课程结构等内容。
Spark和Superset的Contributor
《Spark 海量数据处理》的作者
《Hadoop 海量数据处理》的作者
诞生于 2009 年的 Apache Spark,目前已成为全球范围内最流行、功能最全面、社区最活跃的大数据处理技术。在所有大数据处理技术中排名第一,在Github开源项目上面获得关注25.7k个star,共有1486位贡献者的参与(数据统计至20200415)。
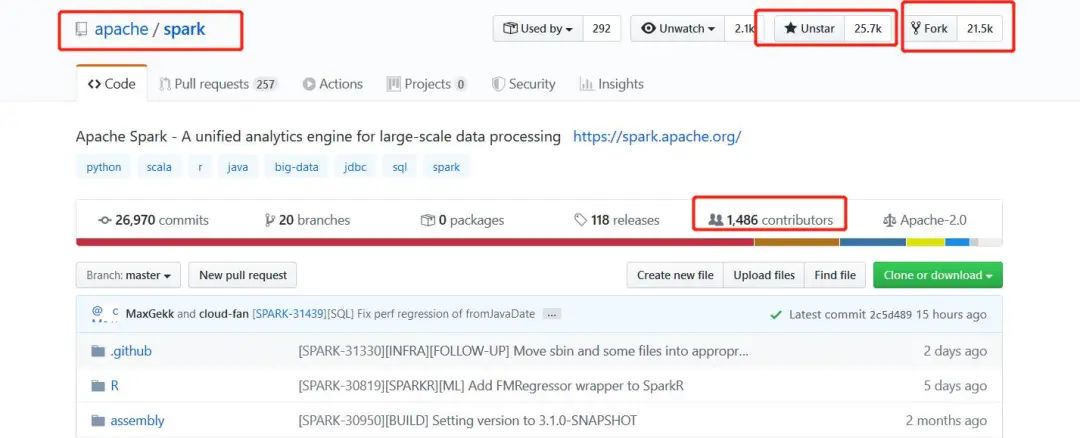
此外,Spark在资本市场也得到了极高的认可,其背后的商业化公司得到了62亿美元的估值。目前,绝大多数公司和组织都是基于Spark生态搭建大数据平台,构建支持业务的数据管道。可以说,提到大数据处理,Spark是一个无法避免的话题。
另外,Spark也很适合数据科学家与数据分析师进行中小规模数据处理,多语言接口与SQL支持让它赢得了很多分析师用户,而且这部分用户中Spark使用者的占比也越来越大,俨然成为了数据工程与数据科学的通用方案。
无论你是数据分析师、大数据工程师、大数据架构师,总之接触到海量数据的同学都可以尝试Spark,面对各种应用场景,看看能否提高效率、满足需求。
本课程共有7个模块,是一个从0到1的过程。如下图,(图片来自于课程)。

本人觉得这个课程干货满满,将逐步学习并实践,如果有同学对这项课程感兴趣,欢迎和我一起学习,可以通过这个公众号或者是加我微信好友(关注后菜单栏有微信二维码),随时交流。

文章转载自AI自然语言处理与知识图谱,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
