自动化诊断一直是我们做运维自动化系统的高级目标,不过要想做好难度不小。大多数自动化诊断工具都是单一目标导向的,比较适合于针对某些已知的,特定的问题进行分析。其诊断目标,诊断路径,算法基本上都是预先确定的,已知的。比如面向某个特定系统的特定的问题的分析诊断工具,做起来还是相对比较容易的,当然如果要做的好,需要下大功夫。如果是面对非特定问题,或者面对复杂的不完全明了的场景做自动化诊断该如何做呢?能不能做呢?今天老白和大家一起来探讨一下通用型的,模糊场景的自动化诊断该如何入手。
要做自动化诊断,第一步就要谈到自动化问题发现。如果一个系统已经宕机了,或者用户无法访问了,这样我们很轻松就能发现系统出问题了,但是如果系统整体运行还是正常的,我们如何发现其中的潜在隐患呢?最简单的方法是通过对某些指标进行监控,如果发现指标偏离基线则认为其存在问题,不过这种方法太过于简单粗暴,只能够用于对特别明显的问题进行定位,更为复杂的需要通过引入复杂的表达式或者模型来进行分析。我们可以根据某些指标建立一个经验模型,当该模型的综合指标出现严重偏差的时候,就认为系统可能存在某种风险。这种被我们称为“运维经验”,如果要面向完全通用的场景去总结运维经验,那我们将面临无限的可能性,其成本是相当高的,而且这些运维经验必然是具有普适性的,而如果我们把目标从普适性的通用的运维经验转向我们所面对的系统,那么确定性就增加了不少。经过数年的运维,我们应该对我们的运维对象有了十分清晰的了解,我们就可以从中获得系统常见问题的运维经验,将这些运维经验总结起来,就可以用于我们日常的问题发现了。
在Oracle官方的Mysql企业管理器中,Oracle提供了一系列的检查项,这些检查项实际上也是通过一些表达式的计算,发现系统中存在的问题,这些就是官方提供的运维经验,下面是一些举例:

以innodb日志等待可能是性能瓶颈这条运维经验来看,这条运维经验的触发条件是通过对表达式100*(innodb_log_waits/(innodb_log_writes+1))的计算,如果等待比例超过50%,则触发该运维经验报警。当然50%可以作为参数,不同的用户,不同的应用环境其取值可以是不同的。D-SMART中也采取了类似的方式来建立问题发现的模型体系,这个模型体系包含三种类型的触发条件。第一种是指标,当某个指标的阈值超过的时候就会触发某个运维经验报警;第二种是高级表达式,类似于上面举的那个例子,不是简单的通过某个指标的阈值来进行判断,而是根据多个指标的计算来判断是否触发某个运维经验;第三种是模型,通过一组指标经过特定的评分体系计算出来的一个分值来作为预警的手段。
可能有朋友会疑惑了,第一种不就是基线预警吗,某个指标的基线被突破了报警,是运维自动化系统中最常用的报警方法。实际上,成为运维经验的指标,已经不是简单的指标了。作为基线预警,我们只需要确定某个指标的基线范围就可以了,突破范围就报警。而作为运维经验的指标报警,还必须有一个明确的靶向,就是说已经明确了这个指标超出基线可能意味着某种故障或者某种隐患已经存在。比如:
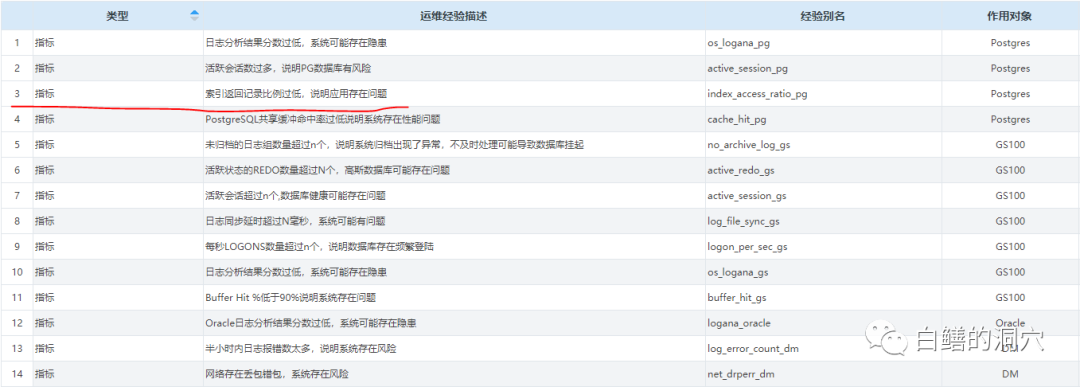
索引返回记录比例过低,则说明应用可能存在问题,这里实际上是对指标“索引返回记录比例”设置了阈值,如果超过阈值,则进行报警,不过该报警已经明确了问题的可能性“应用可能存在问题”。这样,当该报警被捕获的时候,我们就有了明确的分析方向,针对应用进行分析。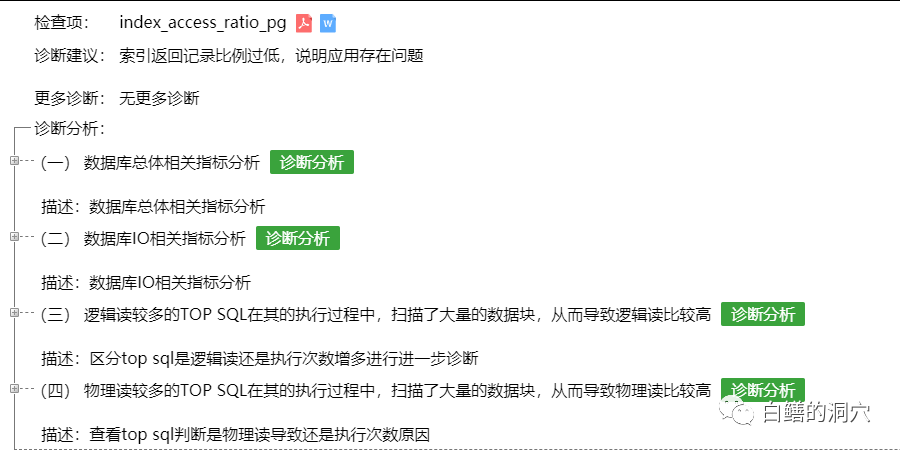
这样我们就可以在该问题被发现的时候采用合理的诊断方式去进行诊断。这是运维经验预警与基线预警的最主要的差别。高级表达式是通过多个指标的数学计算或者逻辑计算获得一个真假的值,如果符合“真”则进行报警: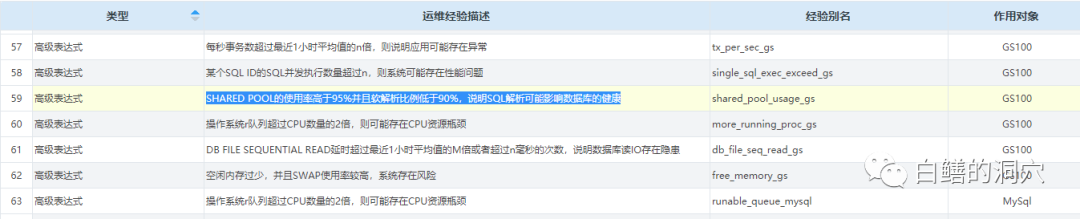
比如有一条运维经验:“SHARED POOL的使用率高于95%并且软解析比例低于90%,说明SQL解析可能影响数据库的健康”,是通过两个指标的综合情况来判定触发报警的条件,这样报警就会更为精准,解决基线报警不准确的问题。
第三种是通过模型报警,比如:

“负载健康分数过低,系统会存在隐患”就是根据负载模型的指标进行预警,当负载模型的指标超出了预警值后,就会产生报警。
采用这么多的手段来预警,最终的目标有两个:第一个是减少误报的比例,让报警更为精准,第二个目的是让报警有靶向性。针对无靶向的报警可以通过“总体健康模型”来预警,这个预警是针对总体风险的,这个暂时不在我们的讨论范围。而除了整体报警外,所有的报警应该面向已知场景或者大体已知的场景,这样后续我们才能够对这些报警进行自动化的诊断。
今天我们就先讨论到这里,明天老白再和大家一起讨论发现了这些报警后如何做自动化的诊断。
最后修改时间:2020-04-08 09:22:48
文章转载自
白鳝的洞穴,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





