




前言
MySql是大部分开发中离不开的存储工具,但是我们是否理解MySql的工作原理和组成结构呢?怎么使用现在网上已经有大把文章可以去学习,笔者这里就不再重新叙述。我们现在就解析下MySql的存储引擎和事务实现和锁实现这3个维度去思考。
存储引擎InnoDb
这篇文章我们以最常用的InnoDb去聊,因为笔者当前公司出了一个MySql规范。
「如无特殊情况,MySQL必须使用InnoDB引擎,更换引擎需要与DBA讨论。」
MySql记录存储
「页头」
记录了当前页面的控制信息,包括左右兄弟页的页面指针(B+树的左右指针)和页面使用情况等。「虚记录」
以聚簇索引为例:保存了页面的最大虚记录(比页内存的主键还大)和最小虚记录(比页内存的主键还小),方便查询(也是B+树的结构)「记录堆」
行记录存储区块(包括已经存储和已经删除的记录),这些记录堆都在叶子节点,非叶子节点不存储数据只存储索引(这也是B+树的好处)「自由空间链表」
已经删除的记录组成的链表「未分配空间」
没有使用到的空间「Slot区」
页面通过头部左右两个指针链接其它页的信息,所以就会有很多链表,那么怎么从这么多链表找到需要的记录呢,就是通过slot区内存的指针信息指向某一个页面,就例如二分法,分成很多块每个slot指向对应的一块,这也涉及到了MySql在业内查询的时候使用遍历和二分法「页尾」
只要是存储页的校验信息
MySql如何维护页内记录
顺序保证
顺序保证有两种
例如:1 3 4插入一个2:1指向3变成1指向2,然后2指向1(类似链表) 例如:1 3 4插入一个2:把3和4拉到后面(严重拖慢物理性能类似List) 物理有序
逻辑有序(MySql的选择)
插入策略
笔者上面说了Page里面有未分配空间和自由空间链表 业内查询
刚刚笔者页已经说了使用遍历和二分查找(使用Slot区)
InnoDb内存管理
内存池(Buffer Pool)
为什么要内存池,首先一个常识,内存如果在一块区域读取肯定就是比不是一块的快,所以InnoDb会先申请一块连续的内存给读取的数据进行磁盘和内存的交互 内存页面管理
首先,没有数据交互时,有「1.空闲空间」,其次当数据变更的时候(也就是内存里不是最新的数据)有「2.脏数据空间」,最后磁盘数据和内存数据如何一一对应呢?
「总结以上」
有3个链表去管理内存的数据和硬盘映射关系
1.空闲list(保存空闲内存的指针信息)
2.脏list(保存脏数据的指针信息)
3.页面Hash List(保存硬盘数据和内存数据对应关系的指针信息)
内存数据淘汰
当查询的数据到内存,内存容量不够怎么办?
数据淘汰顺序:
空闲List>LRU淘汰>LRU FLUSH MySql使用的是LRU一种算法
当有空闲内存的时候,MySql会从空闲List获取空闲页出来,然后就会把这个已经使用的指针记录移动到保存页面的Hash的List, 然后内存不够了就会通过LRU淘汰那些已经过期的数据,最后LUR页不淘汰了,会从LRU尾部开始遍历,找到脏数据把这脏页刷盘,然后再去把刷盘完的区域移动到LRU尾巴,再去使用这些区域(到底是放尾巴还是放Free List呢?)根据网上文章在MySql5的时候,会放到尾巴,之后是放到FreeList
LUR是有缺陷的!
如下是我们数据在LRU链表的使用情况
A:. . . . . . . . . . . . . . . .
B:. . . . . . . . . .
C:. . . . . . .(数据量更大)
(如何避免热数据淘汰)当LRU内存不够的时候它会直接舍弃后面的数据,那么A数据我们访问频率更高,我们当然不想舍弃,那应该怎么办。
(思路):
1.访问时间+频率
2.两个LRU表(实现冷热分离)
LRU_OLD和NEW区如何进行数据交互呢。

从OLD到NEW
场景1(仅使用频率):当数据读到lru_old表,访问频率很高,那么会添加到lru_new,以此类推,那么lur_new会存满数据,解决不了冷热分离的现象。
「解决」:那么我们就要加上存活时间
「那么我们要思考什么时候要把old数据弄到new呢?」
MySql有个叫做innodb_old_blocks_time(old区存活时间) 当大于iobt,就进入new区
场景2(仅存活时间):当iobt=1s当一个数据进来存活了1s已经到old_tail按道理是要转到new,但是下一秒就会被刷出去了,这样的情况我们肯定不能够把这种数据放到new区。那么如何解决呢?
「解决」:当该数据重新被访问,重新到head那并且已经超过了iobt时间那么才可以到new区域
从NEW到OLD
场景3.当OLD到NEW移动的时候那么NEW区就会慢慢变大,而且会造成new比old不满足5/8,那么怎么使NEW到OLD,应该怎么移动呢?
看以上的结果其实只要把NEW的TAIL移动到OLD的HEAD就行,但是MySql使用更简单的方法,只要移动MID_POINT就可以了(但是我们什么时候区移动MID_POINT呢?)
「MySql」:直接移动MidPoint去保证5/8
LRU_new操作
LRU_NEW就是某个节点往表头移动,链表操作效率很高,就仅仅内存指针偏移。
但是MySql并没有直接把某个节点移动到表头。「为什么呢?」
「因为」:移动的时候要加锁,加锁意味着线程休眠,阻塞其他线程,会有额外的开销。
「MySql的解决方案」:MySql解决不了加锁问题那么只好减少移动次数,那么就会减少其他性能的开销。「两个重要参数参考」:
freed_page_clock:Buffer Pool淘汰页数
LRU_new长度的1/4
当前访问Page时记录当前freed_page_clock和当前页上次移动到Header时相减跟>LRU长度的1/4
「例子」: 当前Page的freed_page_clock为1000,而当前Page一定在Haader待过且当时freed_page_clock为8000,那么1000-8000如果大于LRU_new长度的1/4那么就再次移动到Header,为什么选择1/4这个刚好的值呢?因为太早移动就会频繁,太晚热数据就被淘汰掉。
两个重要参数
1.freed_page_clock(buffer pool淘汰页数)
当前淘汰页数与上一次这个位置淘汰的页数
2.lru_new长度的1/4
当mid_point
MySql事务实现原理解析##
事务基本概念
事务特性
A(Atomicity原子性):全部成功或者全部失败 I(Isolation隔离性):并发事务之间互不干扰 D(Durability持久性):事务提交后,永久生效 C(Consistency一致性):通过AID保证
并发问题
「脏读(Dirty Read)」:读取到未提交的事务 「不可重复度(Non-repeatable read)」:同一个事务中两次读取结果不同 「幻读(Phantom Read)」: select操作得到的结果所表征的数据状态无法支撑后续的业务操作
隔离级别
「Read Uncommitted(读未提交内容)」:最低的隔离级别,会读取到其他事务未提交的数据,产生脏读 「Read Committed(读已提交内容)」:事务过程可以读取到其他事务已提交的数据,产生不可重复读 「Repeatable Read(可重复度)」:每次读相同结果集,不关其他事务是否提交,产生幻读(也解决了幻读「前提」是两个当前读,而不是快照读) 「Serializable(串行化)」:事务排队,隔离级别最高,性能最差
事务实现原理
MVCC
MVCC叫做多版本并发控制(Multi-Version Concurrency Control) 干什么用的呢?MVCC解决读-写冲突问题 怎么实现的呢?使用隐藏列去实现 MVCC有又了「当前读(读事务最新版本)和快照读(读之前的版本)」

RR级别下的可重复度怎么搞定的 快照读 活跃事务列表 列表中最小事务ID 列表中最大事务ID 读取当前活跃事务列表进行排序例如[10,50,80,81,100] 创建快照这一刻,还未提交的事务(看不见) 创建快照后创建的事务(看不见) 可见性判断 Read View
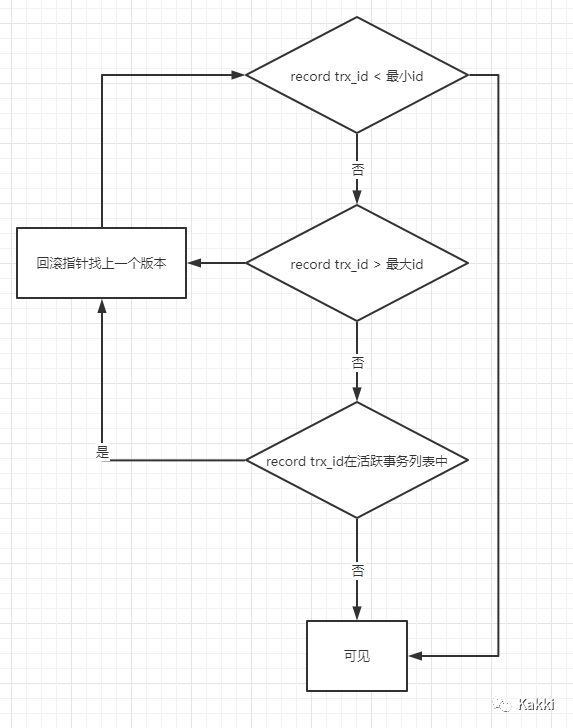
分析可见性
select时会有一个事务id,当前事务id小于活跃列表最小的ID,说明在创建快照的时候事务已经提交了,因为他已经不在活跃列表里面(可见) select时会有一个事务id,当前事务id大于活跃列表最大的ID,说明当前修改在创建快照之后创建的事务(不可见)(回滚指针找上一个版本直至可见) select时会有一个事务id,当前事务在活跃列表里,说明创建快照这一刻,事务还未提交(不可见)(回滚指针找上个版本直至可见)
undo log
undo log叫做回滚日志 作用:保证事务原子性 做了什么:实现数据多版本 两种undo log 如何清理undo log:可以根据系统活跃最小事务ID去删除 delete undo log:用于回滚,提交就清理 update undo log:用户回滚,同时实现快照读,不能随便删除
InnoDb count(*) 为什么这么慢
这个大家可以思考下。
redo log
作用:实现事务持久性 记录修改的数据 用于异常恢复 循环写文件
MySql锁实现原理解析
锁粒度
行级锁(顾名思义锁行) 间隙锁(顾名思义锁间隙) 表锁(顾名思义锁表) 类型
写锁,只能被一个事务获取,获取了锁才能修改数据 读锁,可以同时被多个事务获取,不允许其他事务对记录修改 S锁和X锁的思想有点想juc包的读写锁 共享锁(S) 排他锁(X) 重点分析排他锁,也就是写锁
作用在索引上 聚簇索引和非聚簇索引上 所有的当前读都要加入排它锁例如():select for update、update、delete 行级锁
