




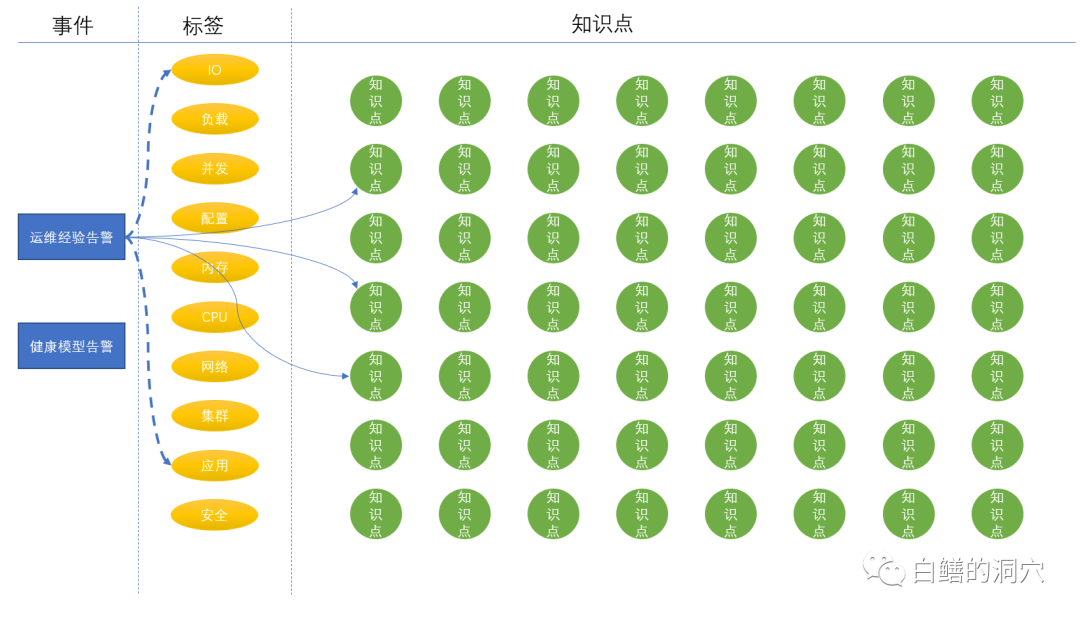

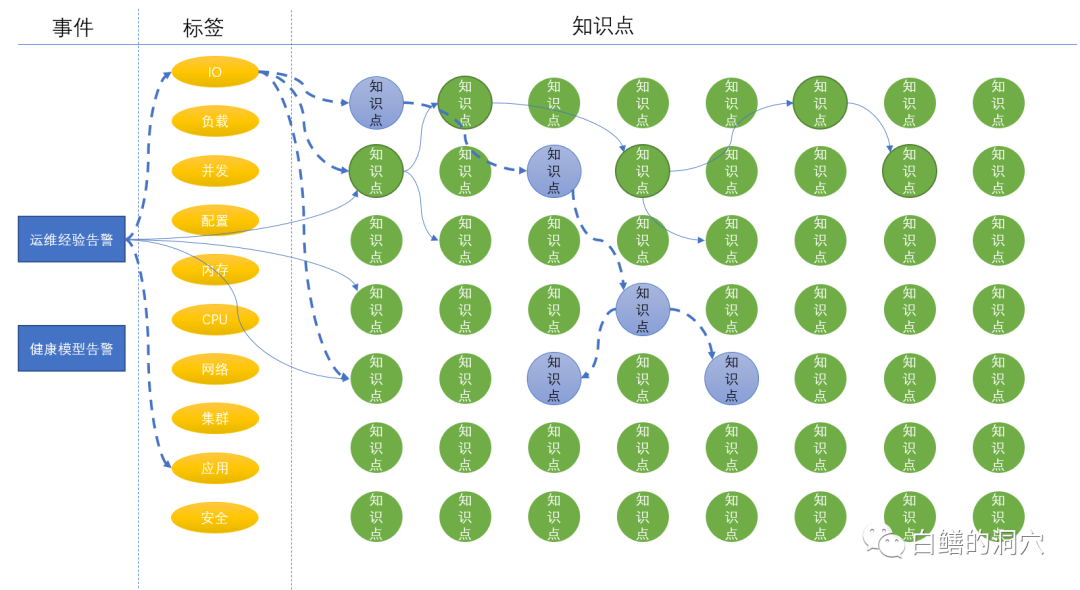
从标签关联的知识点我们可以重新出发,去处置更为复杂的问题,通过智能标签我们可能会发现一条新的诊断路径,最终通过新的诊断路径去找到问题。
一切似乎都十分美好,不过我们面临的实际情况可能会十分复杂。标签的关联关系是弱关联关系,因此知识点之间的关联关系十分复杂,会形成一种网状的结构。从一个网状的环境中发现有效诊断路径的计算量以及对基础数据的需求量都十分大,如果我们要在这个网状关系中去做问题发现,可能我们的诊断工具从生产系统中采集数据就会变成一个巨大的问题源。因此我们需要通过一些高级的算法来对分析进行降维。通过构建节点嵌入学习模型,学习网络图的节点特征向量,达到数据降维和特征选择的目的;该流程得到的特征向量为下一阶段的路径预测模型的构建做有效的数据准备。主要任务是利用采集数据集构建网络结构图,基于Biased random walk策略和skip-gram的词向量构建节点嵌入学习模型,经过不断的训练和迭代后保存至指定路径下。
构建模型所需要的训练需要大量的数据,而我们的实际生产案例中一般无法获得到足够的由专家标注的数据,因此这种深度学习也受到了很大的限制。受启发于周志华先生的半监督学习理论,我们采取了一种基于少量专家标注数据与通过专家模型算法构建的“状态巡检”产生的问题发现共同作为监督数据,用于模型训练。这样我们就获得了比通过专家诊断点击标注多数百倍的标注数据,让模型训练成为了可能。
对于最后一部分的基于智能标签的自动化诊断,我们也仅仅刚刚处于起步阶段,目前所获得的进展也只是初步的。随着IT健康管理工作的不断深入,我相信这方面出现突破性进展的日子也不会很久了。
最后修改时间:2020-04-10 07:46:48
文章转载自 白鳝的洞穴,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
