






一、设计模式原则
二、设计模式分类
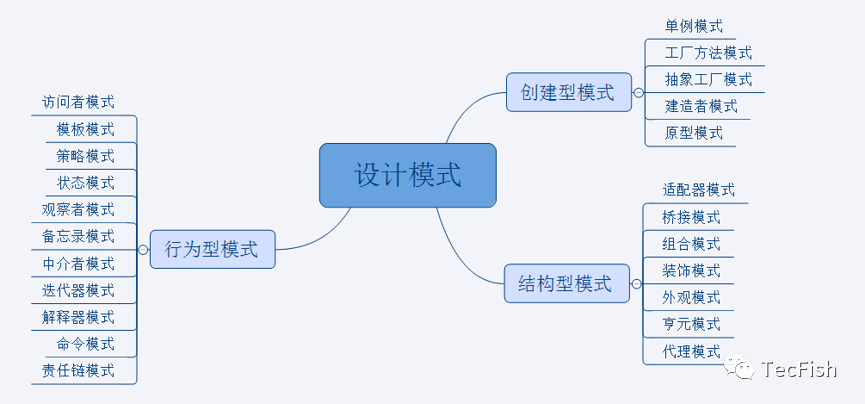
设计模式可以分为三大类,分别为:创建型模式、结构型模式和行为型模式。如下图:
三、单例模式
单例模式(Singleton)是一种常用的设计模式。在Java应用中,单例对象能保证在一个JVM中,该对象只有一个实例存在。比如:任务管理器、日历、回收站、配置文件网站计数器等。
这样做有几个好处:
①、某些类创建比较频繁,对于一些大型的对象,这是一笔很大的系统开销。
②、省去了new操作符,降低了系统内存的使用频率,减轻GC压力。
③、有些类如交易所的核心交易引擎,控制着交易流程,如果该类可以创建多个的话,系统完全乱了。(比如一个军队出现了多个司令员同时指挥,肯定会乱成一团),所以只有使用单例模式,才能保证核心交易服务器独立控制整个流程。
我相信很多人在一开始接触Java的时候就开始写单例了,有懒汉式、饿汉式,不过他们都有各自的不足,在这里就不做过多赘述了,下面推荐一些比较合理的单例模式。
1、双重检验锁
在Spring中比较明显使用单例模式的地方有在获取Bean的时候。源码实现:AbstractBeanFactory的getBean方法中。调用的方法如下:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {Object singletonObject = this.singletonObjects.get(beanName);if(singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {Map var4 = this.singletonObjects;synchronized(this.singletonObjects){singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null && allowEarlyReference) {ObjectFactory<?>singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);if(singletonFactory !=null) {singletonObject = singletonFactory.getObject();this.earlySingletonObjects.put(beanName, singletonObject);this.singletonFactories.remove(beanName);}}}}}
其中singletonObject是ConcurrentHashMap类型的,是通过volatile修饰的,有兴趣的朋友可以追一下ConcurrentHashMap的源码。
简化一下上面代码,总结一下双重检验锁如下:
private DoubleCheckSingleton(){}private static volatile DoubleCheckSingleton doubleCheckSingleton = null;public DoubleCheckSingleton getInstance(){if (doubleCheckSingleton == null){synchronized (DoubleCheckSingleton.class){if (doubleCheckSingleton == null) {doubleCheckSingleton = new DoubleCheckSingleton();}}}return doubleCheckSingleton;}
在这里一定要注意volatile关键字,volatile关键字的一个重要作用是禁止指令重排序。
如果没有会出现什么情况呢?
首先看一下类初始化大概的流程:
①、分配内存空间
②、初始化对象
③、设置INSTANCE指向分配的内存地址
但是在类初始化的过程中上面②和③的顺序是不确定稍微,也就是说有可能出现①③②的顺序,这样就会出现问题,如下图:

这就会出现B线程获取的INSTANCE不正确的问题。
2、静态内部类
内部类的特点是只有在被调用的时候才会加载,可以利用这个特点对单例模式进行改进,这种方式兼顾了饿汉式的内存占用和懒汉式的sychronized效率问题。代码如下:
public class InnerClassSingleton {}private InnerClassSingleton() {}public static final InnerClassSingleton getInstance() {return InnerHolder.INSTANCE;}public static class InnerHolder{private static final InnerClassSingleton INSTANCE = new InnerClassSingleton();}
但是这里涉及到一个反射入侵的问题,可以通过反射获取构造方法。
Class<?> clazz = InnerClassSingleton.class;try {Constructor constructor = clazz.getDeclaredConstructor(null);constructor.setAccessible(true);Object object1 = constructor.newInstance();Object object2 = constructor.newInstance();System.out.println(object1 == object2);} catch (Exception e) {e.printStackTrace();}
如果是单例的话,输出应该是true,但是实现输出结果是false。这就是反射入侵,如何防止呢?修改代码如下:
private static Boolean initialized = false;private InnerClassSingleton() {synchronized (InnerClassSingleton.class) {if (initialized == false){initialized = !initialized;}else {throw new RuntimeException("单例被侵犯");}}}public static final InnerClassSingleton getInstance(){return InnerHolder.INSTANCE;}public static class InnerHolder{private static final InnerClassSingleton INSTANCE = new InnerClassSingleton();}
再次用反射进行调用则会出现下面的结果

这样就保证了单例的唯一性,防止了反射入侵。
3、枚举
枚举对象的实例都是预定义的,也就是在类加载的时候都是定义好了的,不会给其它调用去创建实例的机会。

这是在cmd中编译的枚举类,可以看到,枚举本质上是通过普通的类来实现的,只是编译器为我们进行了处理。每个枚举类型都继承自java.lang.Enum,而每个枚举常量是一个静态常量字段,这样保证了每个枚举类型及枚举常量都是不可变的。可以利用枚举的这两个特性来实现线程安全的单例。如下:
INSTANCE;private Person person = null;EnumSingleton() {person = new Person();}public Person getPerson() {return person;}
通过INSTANCE来获取实例,类似于内部类的形式。
4、序列化与反序列化
在这里,很有必要的得说一下序列化和反序列化,因为反序列化的时候会重新创建对象,这会对单例造成破坏。
Java序列化是指把Java对象转换为字节序列的过程,可以把对象永久保存下来(磁盘、网络IO);
Java反序列化是指把字节序列恢复为Java对象的过程,通过IO流把读取的内容转换为java对象。
看一下下面的例子(此处用的Java序列化):
首先写一个单例,继承Serializable接口:
public class Seriable implements Serializable {private static final Seriable seriable = new Seriable();private Seriable(){};public static Seriable getSeriable() {return seriable;}}
下面是测试方法:
Seriable seriable = Seriable.getSeriable();ObjectOutputStream objectOutputStream = new ObjectOutoutStream(new FileOutputStream("D:\\aa.txt"));objectOutputStream.writeObject(seriable);ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("D:\\aa.txt"));Seriable seriable1 = (Seriable) objectInputStream.readObject();System.out.println(seriable == seriable1);
运行结果为false,说明到单例被破坏,如何避免呢?做法如下:
public class Seriable implements Serializable {private static final Seriable seriable = new Seriable();private Seriable(){};public static Seriable getSeriable() {return seriable;}private Object readResolve(){return seriable;}}
加readResolve()方法,在这个方法中返回了原来的实例,这个方法在反序列化时被反射调用,如果定义了这个方法,就返回这个方法的值,如果没有定义,则返回新new出来的对象。这就能预防反序列化对单例的破坏了。
对于枚举来说,每一个枚举类型及其定义的枚举变量在JVM中都是唯一的,因此在序列化的时候Java仅仅是将枚举对象的name属性输出到结果中,反序列化的时候则是通过 java.lang.Enum 的 valueOf() 方法来根据名字查找枚举对象,也就是说,在序列化的时候只将 INSTANCE这个名称输出,反序列化的时候再通过这个名称,查找对于的枚举类型,因此反序列化后的实例也会和之前被序列化的对象实例相同,所以枚举不会受序列化影响。
四、工厂模式
在游戏中,我们去商城购买英雄,不管英雄是怎么设计的,只需交付每个英雄所需的钱,购买英雄即可。也就是商城根据我的条件创建实例对象。我就可以从商城(也就是工厂)获取我想要的英雄。
说到Spring框架,大家一般首先想到的是依赖注入,控制反转,面向切面这些东西。其实Spring的本质是一个bean工厂(beanFactory)或者说bean容器,它按照我们的要求,生产我们需要的各种各样的bean,提供给我们使用。只是在生产bean的过程中,需要解决bean之间的依赖问题,才引入了依赖注入(DI)这种技术。也就是说依赖注入是beanFactory生产bean时为了解决bean之间的依赖的一种技术而已。
工厂模式有三种,分别是简单工厂模式、工厂方法模式和抽象方法模式。类似于从小作坊到标准化工厂再到流水线的工作模式。
1、简单工厂模式
以买咖啡为例,比如我去楼下瑞幸买咖啡,这里有四个角色:1、咖啡接口,2、美式咖啡继承咖啡接口,3、瑞幸咖啡工厂类,4、顾客(主方法获取咖啡)。
工厂类和主方法如下:
public class Luckin {public Coffee getCoffee(String name){String americano = "美式";if (americano.equals(name)){return new Americano();}return null;}}
public class Customer {public static void main(String[] args) {Luckin luckin = new Luckin();log.info(luckin.getCoffee("美式").getName());}}
可以看到顾客必须知道商品的具体名称才可以获取到咖啡。而且如果业务增多,会导致Luckin这个简单工厂类很庞大臃肿、耦合性高,而且增加、删除某个子类对象的创建都需要对这个简单工厂类来进行修改代码,违反了开-闭原则。
2、工厂方法模式
刚才简单工厂模式可以看到所有咖啡的具体业务代码都在同一个工厂类中,在这时就可以把每个业务分离开来,这就是工厂方法模式。就是说拿铁有拿铁的部门,摩卡有摩卡的部门,顾客到拿铁部门直接点咖啡就可以了,不用知道名称。
从代码层面说,增加了一个工厂接口,每个分部门的具体业务在自己的类中实现,代码结构及客户获取咖啡方法见下图:
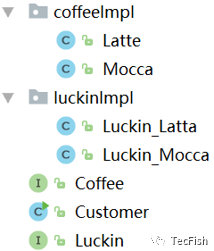
public class Customer {public static void main(String[] args) {Luckin luckin = new Luckin_Latta();log.info(luckin.getCoffee().getName());}}
如果增加功能,在简单工厂模式中需要修改工厂类,但是在工厂方法模式中只需要增加接口(Luckin)的实现类就可以了,这也是工厂方法模式对简单工厂模式解耦的一个体现。
但工厂方法模式的缺点是每增加一个产品类,就需要增加一个对应的工厂类,增加了额外的开发量。最主要的问题是只能横向扩展,无法纵向扩展。
3、抽象方法模式
在上面工厂方法模式,由于我已经new到了拿铁的这一个分部(Luckin_Latta),所以我获取的所有物品都是这个分部的,这就限制了我的纵向发展,假设每个分部都有咖啡和饼干,两者我都想要,但是我想要拿铁分部的咖啡和摩卡分部的饼干,这就不是工厂方法模式所能实现的了,这也就发展出来了抽象工厂模式。为什么是抽象方法呢?因为可以在抽象方法中放公共的逻辑,差异化的逻辑放在集成类中。
这里引出了一个“产品族”的概念,产品族是指位于不同产品等级结构中,功能相关联的产品组成的家族。
代码结构图如下:
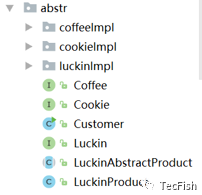
其中coffeeImpl、cookieImpl、luckinImpl分别为各种咖啡、饼干和下属的各个瑞幸分部。LuckinAbstractProduct代码如下:
public abstract class LuckinAbstractProduct {/***抽象方法内放公共的逻辑,统一管理,差异化的定制放在继承类中*/public abstract Coffee getMocca();public abstract Coffee getLatta();public abstract Cookie getMoccaCooike();}
LuckinProduct代码如下:
public class LuckinProduct extends LuckinAbstractProduct {@Overridepublic Coffee getMocca() {return new Luckin_Mocca().getCoffee();}@Overridepublic Coffee getLatta() {return new Luckin_Latta().getCoffee();}@Overridepublic Cookie getMoccaCooike() {return new Luckin_Mocca().getCookie();}@Overridepublic Cookie getLattaCooike() {return new Luckin_Latta().getCookie();}}
Customer代码如下:
public class Customer {public static void main(String[] args){LuckinProduct luckinApp = new LuckinProduct();log.info(luckinApp.getMocca().getName()+"..." + luckinApp.getLattaCooike().getName());}}
可以看到,我们可以同时获取到摩卡的咖啡和拿铁的饼干,这就实现了纵向的发展。
五、代理模式
代理(Proxy)是一种设计模式,提供了对目标对象另外的访问方式,即通过代理对象访问目标对象。这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能。这里使用到编程中的一个思想:不要随意去修改别人已经写好的代码或者方法,如果需改修改,可以通过代理的方式来扩展该方法。比如AOP、中介、黄牛等。
那么为什么要用代理模式呢?
中介隔离作用:在某些情况下,一个客户类不想或者不能直接引用一个委托对象,而代理类对象可以在客户类和委托对象之间起到中介的作用,其特征是代理类和委托类实现相同的接口。比如说银保通、jdbc
开闭原则,增加功能:代理类除了是客户类和委托类的中介之外,我们还可以通过给代理类增加额外的功能来扩展委托类的功能,这样做我们只需要修改代理类而不需要再修改委托类,符合代码设计的开闭原则。代理类主要负责为委托类预处理消息、过滤消息、把消息转发给委托类,以及事后对返回结果的处理等。代理类本身并不真正实现服务,而是同过调用委托类的相关方法,来提供特定的服务。真正的业务功能还是由委托类来实现,但是可以在业务功能执行的前后加入一些公共的服务。例如我们想给项目加入缓存、日志这些功能,我们就可以使用代理类来完成,而没必要打开已经封装好的委托类。
代理中的角色:
代理中,主要有代理角色和被代理角色,通常情况下,代理角色会持有被代理角色对象的引用。
代理模式的分类:静态代理、动态代理。
1、静态代理
静态代理:在代理之前,所有的东西都是已知的。如下图:

public class Matchmaker {private Person person;public Matchmaker(Person person) {this.person = person;}public void findLove() {log.info("根据要求物色对象");this.person.findLove();log.info("合适吗?");}}
媒人也可以对程序员的条件进行加工拓展。
public class StaticProxyTest {public static void main(String[] args) {Programmer programmer = new Programmer();Matchmaker matchmaker = new Matchmaker(programmer);matchmaker.findLove();}}
在使用的时候,把程序员的实例传给媒人,经过媒人修饰,外人看到的是媒人包装过后的程序员的条件。
这样做的优缺点:
优点:在符合开闭原则的前提下对目标对象进行拓展。
缺点:不能拓展,接口变化,代理类也得相应改变。
如何解决呢?这就是下面要说的动态代理。
2、动态代理
动态代理:在代理之前,所有的东西都是未知的。是通过字节码重组实现的。如下图:
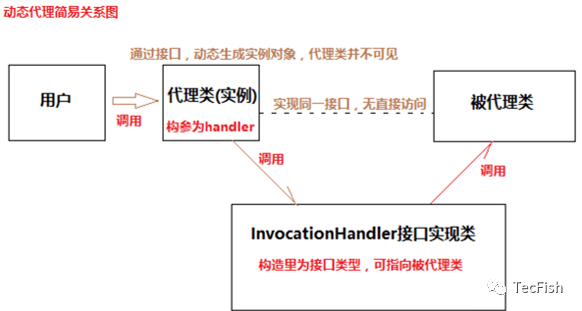
从代码层面来说:
Person接口和Programmer实现类不变,修改代理类如下:
public class JdkMatchmaker implements InvocationHandler{private Person person;public Object getInstance(Person person) throws Exception{this.person = person;Class<?> clazz = person.getClass();return Proxy.new ProxyInstance(clazz.getClassLoader(),clazz.getInterfaces(), this);}@Overridepublic Object invoke(Object proxy, Method method,Object[] args)throws Throwable {method.invoke(this.person,args);return null;}}
返回的Proxy.newProxyInstance()方法中有三个参数,分别是:
ClassLoaderloader:指定当前目标对象使用的类加载器
interfaces:指定目标对象实现的接口的类型,使用泛型方式确认类型
InvocationHandler:指定动态处理器,执行目标对象的方法时,会触发事件处理器的方法
使用方法如下:
public class JdkMatchmakerTest {public static void main(String[] args) {try {Person object = (Person)new JdkMatchmaker().getInstance(new Programmer());objecet.findLove();} catch (Exception e) {e.printStackTrace();}}}
可以看到,动态代理中,我们只需要编写一个动态处理器,真正的代理对象由JDK运行时为我们动态的来创建。相对于静态代理,动态代理大大减少了我们的开发任务,同时减少了对业务接口的依赖,降低了耦合度。但是它始终无法摆脱仅支持interface代理的桎梏,不能直接对class进行代理。如果没有接口怎么办?
3、CGLIB
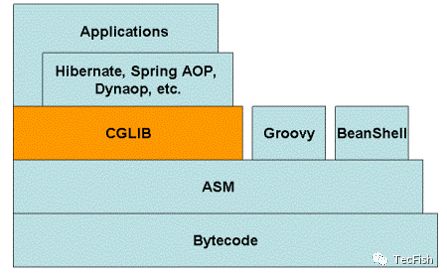
那么什么是CGLIB呢?CGLIB(Code Generator Library)是一个强大的、高性能的代码生成库,广泛应用于AOP中,用以进行方法拦截。
CGLIB代理主要通过对字节码的操作,为对象引入间接级别,以控制对象的访问。我们知道Java中有一个动态代理也是做这个事情的,那我们为什么不直接使用Java动态代理,而要使用CGLIB呢?答案是CGLIB相比于JDK动态代理更加强大,JDK动态代理虽然简单易用,但是其有一个致命缺陷是,只能对接口进行代理。如果要代理的类为一个普通类、没有接口,那么Java动态代理就没法使用了。
CGLIB底层使用了ASM(一个短小精悍的字节码操作框架)来操作字节码生成新的类。除了CGLIB库外,脚本语言(如Groovy何BeanShell)也使用ASM生成字节码。ASM使用类似SAX的解析器来实现高性能。如下图:
同样以媒人的例子,有一个程序员(Programmer)类,里面有找对象(findLove)方法,这时需要一个CGLIB的媒人(CglibMatchmaker)类,如下:
public class CglibMatchmaker implements MethodInterceptor {public Object getInstance(Class<?> clazz) throws Exception {Enhancer enhancer = new Enhancer();enhancer.setSuperclass(clazz);enhancer.setCallback(this);return enhancer.create();}@Overridepublic Object intercept(Object o, Method method, Object[] objects,MethodProxy methodProxy) throws Throwable {methodProxy.invokeSuper(o,objects);return null;}}
public static void main(String[] args) {try{Programmer programmer = (Programmer) new CglibMatchmaker().getInstance(Programmer.class);programmer.findLove();}catch (Exception e) {e.printStackTrace();}}
4、字节码重组
其实动态代理和CGLIB都是通过字节码重组实现的,字节码重组的过程如下:
①、通过反射拿到被代理对象的引用,并且获取到他所有的接口
②、通过jdk proxy重新生成新的类,同时新的类要实现被代理类所实现的所有的接口
③、动态生成业务代码
④、编译新生成的java代码.class文件
⑥、再重新加载到jvm中运行
在Spring中,JDK动态代理和CGLIB都在使用,UML图如下:
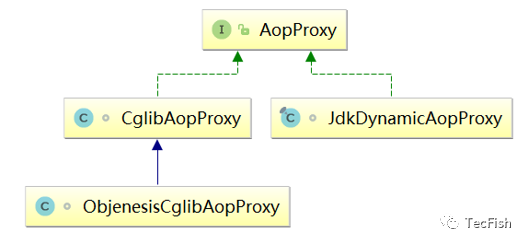
如果要被代理的对象是个实现类,那么Spring会使用JDK动态代理来完成操作,如果要被代理的对象不是个实现类那么,Spring会强制使用CGLib来实现动态代理。
有兴趣的同学可以去看一下SpringAop织入切面逻辑,入口方法是AbstractAutoProxyCreator.createProxy()方法。
六、策略模式
策略模式的思想是针对一组算法,将每一种算法都封装到具有共同接口的独立的类中,从而是它们可以相互替换。策略模式的最大特点是使得算法可以在不影响客户端的情况下发生变化,从而改变不同的功能。比如支付、比较器、旅游等。在支付中,客户可以选择微信支付,也可以选择支付宝支付,这就是一个策略的选择。Spring在实例化对象的时候用到了策略模式,在SimpleInstantiationStrategy类中。
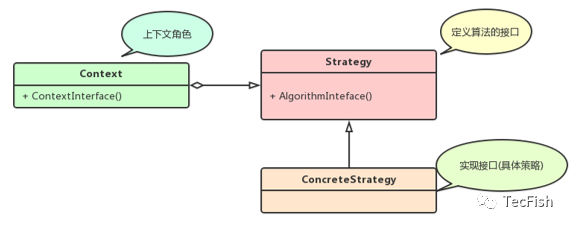
策略模式使用的就是面向对象的继承和多态机制,从而实现同一行为在不同场景下具备不同实现。它有三个角色:
上下文角色(Context):用来操作策略的上下文环境,屏蔽高层模块(客户端)对策略,算法的直接访问,封装可能存在的变化
抽象策略角色(Strategy):规定策略或算法的行为
具体策略角色(ConcreteStrategy):具体的策略或算法实现
关系如下图
主要解决的问题:在有多种算法相似的情况下,使用 if...else 所带来的复杂和难以维护。
下面举个例子:
假设现在有两个数与一个运算符,要求使用该运算符操作这两个数。通常情况下,我们会这么做:
public class Calculator {private static final String SYMBOL_ADD="+";private static final string SYMBOL_SUB="-";public int cal(int a, int b, String symbol){int result = 0;if (symbol.equals(SYMBOL_ADD)){result = a+b;}else if (symbol.equals(SYMBOL_SUB)){result = a-b;}return result;}}
1、策略模式
我们也可以使用策略模式,这样做:
首先,定义一个接口:
public interface ICalculator {int cal(int a ,int b);}
实现类如下:
public class Add implements ICalculator {@Overridepublic int cal(int a, int b) { return a+b; }}
上下文,封装角色。这里通过构造方法将具体的策略传入高层,而高层不用知道具体是哪种策略,只需要调用策略的方法即可:
public class Context {private ICalculator iCalculator;public Context(ICalculator iCalculator) {this.iCalculator = iCalculator;}public int cal(int a ,int b) {return this.iCalculator.cal(a,b);}}
主方法:
public class CalTest {public static void main(String[] args) {ICalculator iCalculator = new Add();Context context = new ConText(iCalculator);int result = context.cal(2,7);}}
可以看到,我们消除了if...else,取而代之的是客户端直接决定使用哪种算法,然后交由上下文获取结果。
2、策略枚举
public interface ICalculator {int cal(int a ,int b)}
它的实现类如下:
public class Add implements ICalculator {@Overridepublic int cal(int a ,int b) {return a+b;}}
定义枚举类:
public enum CalEnum {ADD(new Add()), SUB(new Sub());private ICalculator iCalculator;CalEnum(ICalculator iCalculator) {this.iCalculator = iCalculator;}public ICalculator getiCalculator() {return this.iCalculator;}}
主方法如下:
public class CalTest {public static void main(String[] args) {int result = CalEnum.ADD.getiCalculator().cal(3,2);log.info("计算结果={}",result);}}
可以看到使用枚举类就不用了new对象,耦合性降低。
3、策略模式优缺点
策略模式的优点:
1、策略模式的功能就是通过抽象、封装来定义一系列的算法,使得这些算法可以相互替换,所以为这些算法定义一个公共的接口,以约束这些算法的功能实现。如果这些算法具有公共的功能,可以将接口变为抽象类,将公共功能放到抽象父类里面。
2、策略模式的一系列算法是可以相互替换的、是平等的,写在一起就是if-else组织结构,如果算法实现里又有条件语句,就构成了多重条件语句,可以用策略模式,避免这样的多重条件语句。
3、扩展性更好:在策略模式中扩展策略实现非常的容易,只要新增一个策略实现类,然后在使用策略实现的地方,使用这个新的策略实现就好了。
策略模式的缺点:
1、客户端必须了解所有的策略,清楚它们的不同:
如果由客户端来决定使用何种算法,那客户端必须知道所有的策略,清楚各个策略的功能和不同,这样才能做出正确的选择,但是这暴露了策略的具体实现。
2、增加了对象的数量:
由于策略模式将每个具体的算法都单独封装为一个策略类,如果可选的策略有很多的话,那对象的数量也会很多。
3、只适合偏平的算法结构(好几层级的if,else不合适):
由于策略模式的各个策略实现是平等的关系(可相互替换),实际上就构成了一个扁平的算法结构。即一个策略接口下面有多个平等的策略实现(多个策略实现是兄弟关系),并且运行时只能有一个算法被使用。这就限制了算法的使用层级,且不能被嵌套。
七、总结
A B O U T I N S T R U C T O R
讲 师 速 递
讲师介绍
李浩春,泰康人寿总公司系统应用部后端工程师。强硬的技术实力加上风趣幽默的性格,实属团队中不可多得的良师益友。以下附上他的几张帅照,有想认识的朋友欢迎私我呀!



科技鱼系列
第一期 编码有故事
第二期 流量防卫兵Sentinel
第三期 计算精度与Java编译问题探究
第四期 科普区块链(上)
第五期 科普区块链(下)
第六期 前端工程化实践

