作者丨陈彦杰
编辑丨林颖
供稿丨eBay 技术荟
导读
TiDB 简介
PD(Placement Driver)是有状态元数据节点,可以存储元数据并为集群授时。PD 收集集群状态信息,并负责集群调度。
TiDB 服务器(区分于TiDB集群)是无状态查询节点,负责接受客户端请求,将 SQL 查询转换成 TiKV 能接受的 Key 查询,并负责事务处理。
TiKV 是有状态存储节点,它将所有数据以 Key-Value 的形式存储在底层的 RocksDB[1](一个性能优异的单机 NoSQL 数据库)中。TiKV 使用了两个 RocksDB 实例,分别存储查询数据和日志数据。因此TiKV底层数据的存储形式和大部分 NoSQL 数据库一样,都是 SSTable。SSTable 的特性之一就是 Key 有序,这个特性决定了 TiDB 数据分片的模式 —— 将连续 Key 分段,而不是按 Key 做哈希。另外,TiDB 数据管理的基本单位是 Region(即 Key 连续的数据块)。由于数据块是以 SSTable 形式实现,而且一个 Region 内部本身就是有序的,TiDB 只要保证 Region 相互之间是有序的,就可以得到一个全局有序的数据集。

图 1 TiDB 整体架构
HTAP 带来的性能挑战和解决方案
问题的发现
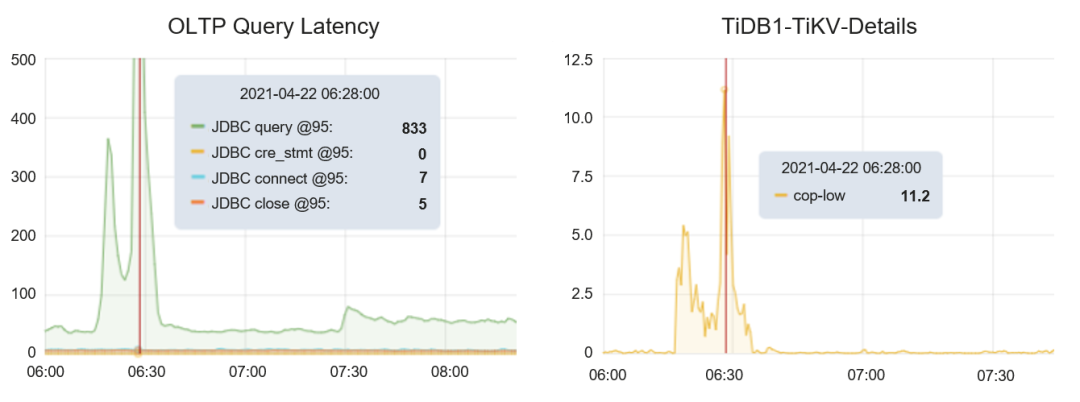
解决方案
Peer 在 Raft 协议下有三种角色:
Leader:负责响应客户端的读写请求; Follower:被动地从 Leader 同步数据,当 Leader 失效时会进行选举产生新的 Leader; Learner:只参与同步 raft log 而不参与投票。
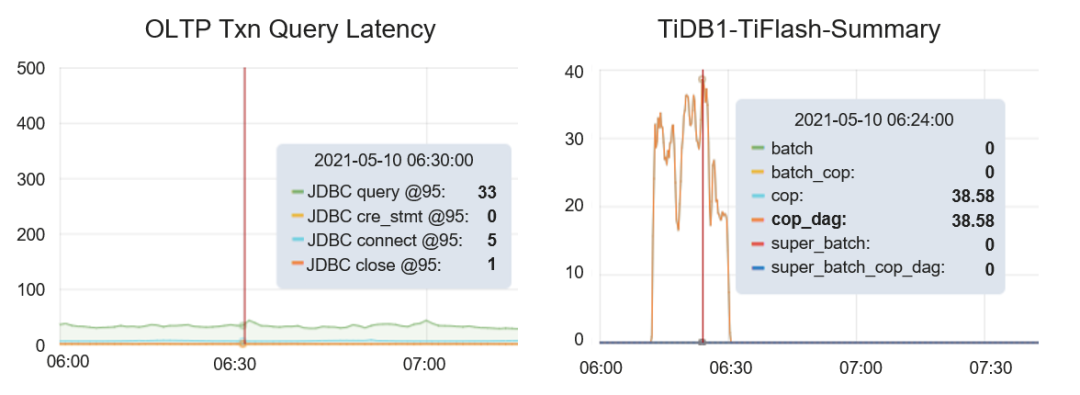
图 3 JDBC 延迟与 TiFlash 负载关系
TiDB 跨数据中心和地域亲和性优化
背景介绍
时间戳(TSO)
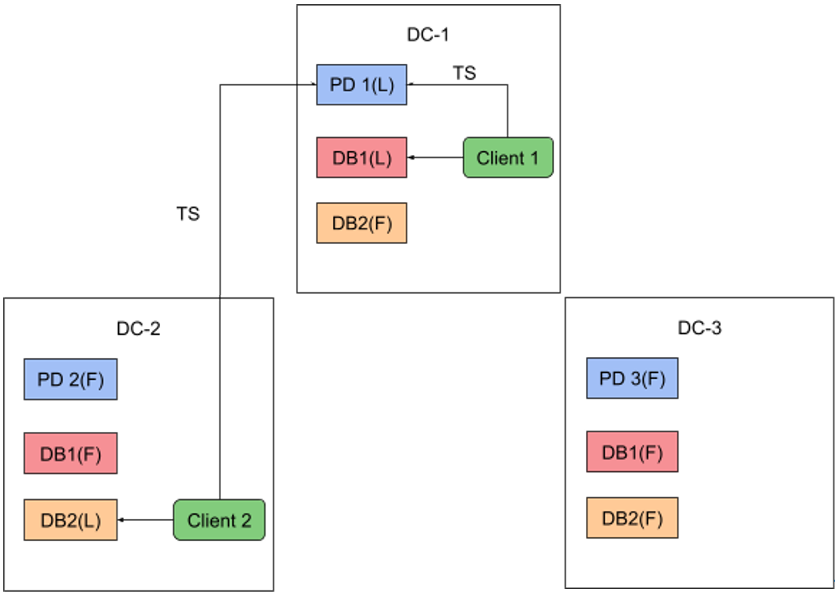
图 4 跨数据中心的授时服务器请求
Leader 读取
问题的发现
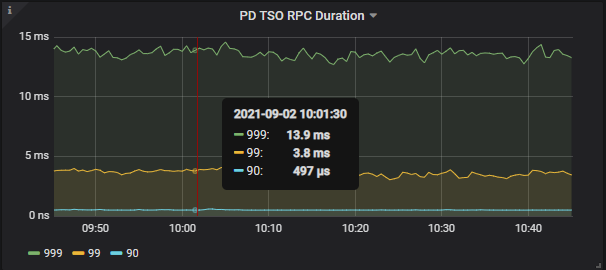
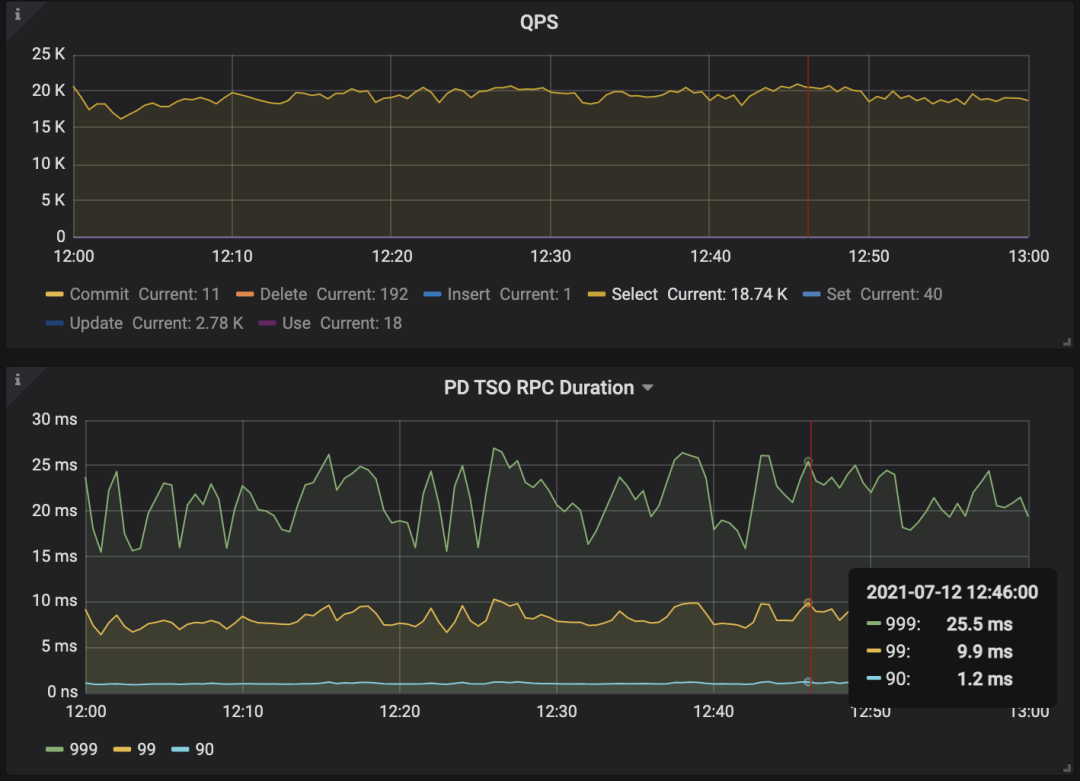
图 5 获取时间戳的网络开销
解决方案
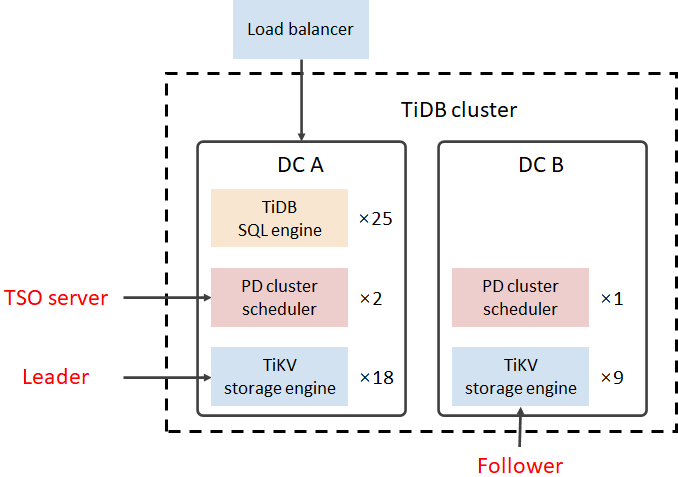
图 6 两数据中心架构
查询计划稳定性
问题的发现
解决方案

其他 TiDB 的调优
横向扩展
磁盘选择
总结与展望
参考资料:
[1]http://rocksdb.org
[2]https://docs.pingcap.com/zh/tidb/stable/tidb-storage
[3]https://docs.pingcap.com/zh/tidb/stable/tidb-computing
[4]https://docs.pingcap.com/zh/tidb/stable/tidb-scheduling
[5]https://docs.pingcap.com/zh/tidb/v4.0/tiflash-overview