





总第486篇
2022年 第003篇

1 背景
2 赛题简介
3 现有方法和问题
3.1 现有方法
3.2 问题
4 我们的方法
4.1 基础指标
4.2 集成方法CRS
5 实验分析
5.1 实验结果
5.2 消融实验
5.3 CRS效果
6 总结
参考文献
作者简介
1 背景

2 赛题简介
Context:对话中的提问,或者说对话的上下文。 Response:针对Context的回复,也即评估的具体对象;对话数据集中的Response一般由不同对话生成模型产生,如GPT-2和T5。 Reference:人工给出的针对Context的参考回答,一般为5条左右。
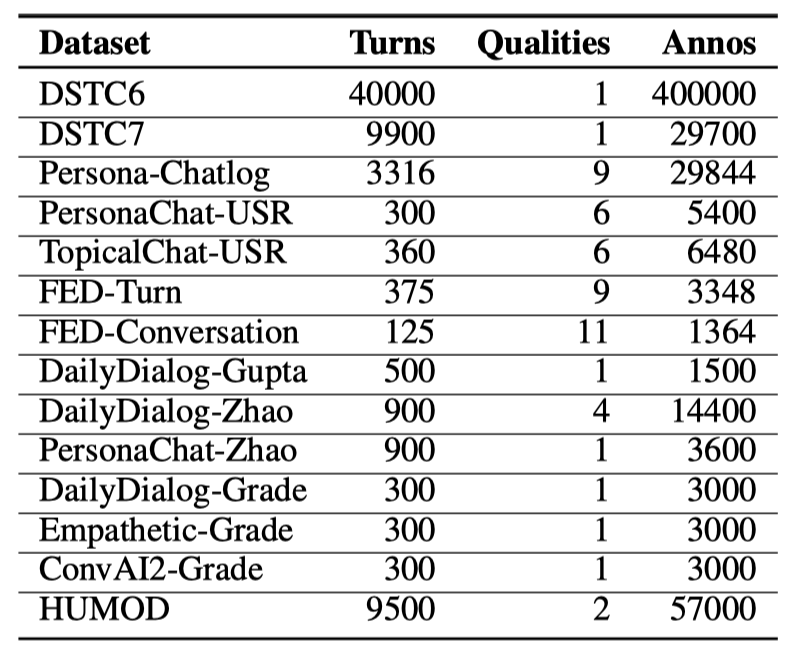

3 现有方法和问题
3.1 现有方法
Response是否通顺流畅。 Context和Respose的相关程度。 Response本身是否详细,更像人类等。
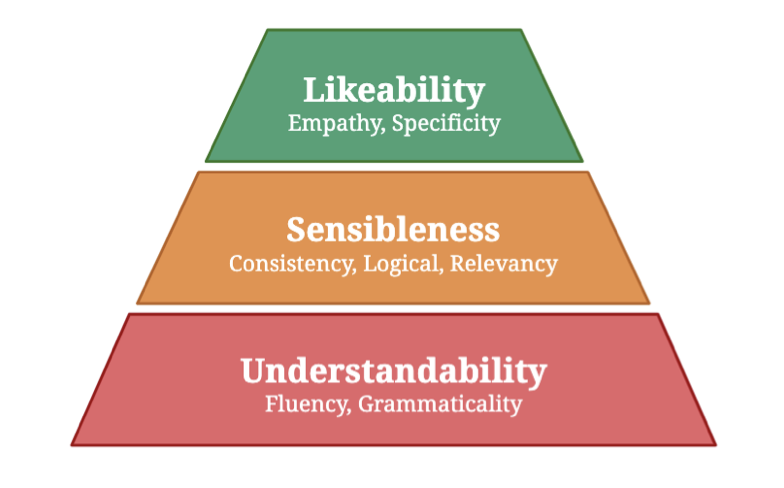
3.2 问题
更细粒度的Context-Response句子对的主题一致性。 回复者对当前对话的参与度。
4 我们的方法
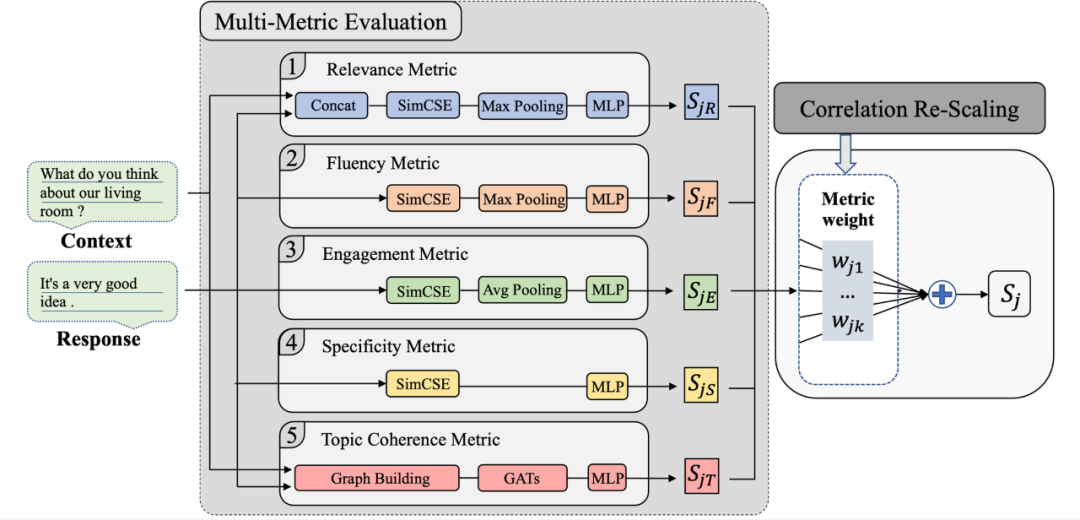
4.1 基础指标
4.1.1 Fluency Metric (FM)
在Dailydialog数据集中随机选择一个Response,并以0.5概率决定r是正样本还是负样本。 如果样本r是正样本,随机选择一种调整:a.不调整;b.对每一个停用词,以0.5的概率删除。 如果样本r是负样本,随机选择一种调整:a.随机打乱词序;b.随机删除一定比例的词语;c.随机选择部分词语并重复。
4.1.2 Relevance Metric (RM)
4.1.3 Topic Coherence Metric (TCM)
4.1.4 Engagement Metric (EM)
4.1.5 Specificity Metric (SM)
4.2 集成方法CRS
4.2.1 不同评估维度权重分布的计算
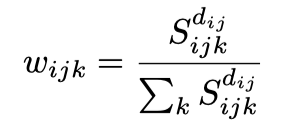
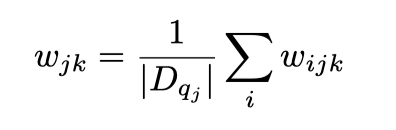
4.2.2 计算指标打分的加权和

5 实验分析
5.1 实验结果

5.2 消融实验

TCM、RM和EM对于模型性能的贡献最大,打分集成阶段删除这三个评估指标后,测试集上的平均Spearman相关性打分分别降低了3.26%、1.56%和1.01%。 粗粒度的RM指标和细粒度的TCM指标是有益的互相补充。如果分别去除RM或TCM指标,性能会有稍微下降;如果同时去除RM和TCM指标,评估方法缺乏了Context相关的信息,性能会大幅降低到11.07%。 SM指标在测试集上的提升基本可以忽略。我们分析原因是:测试集中用于生成Response的各个生成模型在测试集语料上过拟合较为严重,因此生成了很多非常详细,但和Context不相关的Response。因此SM指标的优劣对于测试集质量的评估基本没有作用。
5.3 CRS效果

6 总结
参考文献
作者简介
美团科研合作
阅读更多
文章转载自美团技术团队,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
