




寻找以编程方式进行分析的方法说明计划,以了解添加索引是否有帮助。
对于具有强大谓词过滤器的全表扫描,该分析非常简单。如果在带有全表扫描的解释计划节点上有强大的谓词过滤器,那么它是索引的理想选择。
现在,对于联接存在类似的情况。
同样,如果联接在全表扫描中具有强大的谓词过滤器,则这是一个候选对象。
另一方面,当实际的联接字段看起来将受益于索引时,它就不那么明显了。
在下面的查询中,T1和T2具有相同的数据。
这是查询
select max(t1.data) from t1, t2
where
t1.id = t2.id
and t1.clus = 1 ;
首先,我们尝试不使用索引。
然后,我们尝试对T1的谓词过滤器使用索引。
然后,在T2的连接列上添加索引。
这个想法是,我们应该在添加每个索引时看到性能的提高,以便最终有效路径使用T1上的谓词过滤器索引返回少量行,然后使用T2 join上的索引将少量行带入T2通过NL联接的字段。
令人惊讶的事情是,HJ只是对来自T1的谓词过滤行的值进行哈希处理,并使用来自T2的所有行驱动到哈希结果中,只是效率很高,我们不必在t2联接列上维护索引!这让我感到惊讶。当然,HJ很酷,但是我一直认为它们只是时间索引(即散列结果),可以通过使用索引支持NL连接并且不必在每次查询执行时都重新创建散列结果来避免这种工作。(我必须进行一些负载测试,以查看NL vs HJ查询对数据库资源使用总量和负载的实际影响)。
只需在T1过滤器列上添加索引即可获得HJ,其效率与使用T2联接字段进行NL一样高效,但是在HJ的情况下,我们不必维护T2联接列过滤器。
T1.clus上有一个强大的谓词过滤器(称为“ clus”,因为值是聚类的,我们以后可以看成非聚类的,即相同的查询,但使用的是不聚类的“ val”列)
在下面的查询中,使用连接上的索引将谓词过滤器过滤到T2之后,在T1行上驱动NL是有效的。
但是,HJ(在谓词过滤器之后对T1进行哈希处理并使用来自T2的所有行驱动到哈希中)对我来说是令人惊讶的(更有效或更有效)。
第一个示例将从不使用任何索引开始。
创建测试数据:
drop table seed;
create table seed as
select rownum n from dual connect by level <= 1e6
;
drop table t1;
drop table t2;
create table t1 (
id int,
clus int,
val int,
data VARCHAR(40)
);
insert into t1 (
id, clus , val, data
)
select
n,
trunc(n/100),
mod(n,10000),
dbms_random.string('U',dbms_random.value(2,7))
from seed;
select count(*) from t1 where clus = 1;
100
select count(*) from t1 where val = 1;
100
create table t2 as select * from t1;
alter session set Statistics_level=all;
set timing on;
以下3个示例将在两个表上使用全表扫描。
(我使用“ + 0”来关闭索引,所以我不必删除并重新创建演示,因为在运行这些查询之前我实际上已经创建了索引)
下面的第一个NL比下一个HASH连接要慢,因为NL必须读取T1中每一行的完整表T2,从而导致300K +缓冲区访问(T1过滤时间后100行,每行3000个缓冲区)。
HASH只需读取一次T2(3K +缓冲区访问),然后在T1的散列中查找这些行中的每一行,仍然有很多行(应为1M,即T2中的所有行,这就是估计值),但是 实际说1212,我听不懂)。
散列T2而不是T1会占用更多的内存,不是1.5M而是50M,并且花费的时间更长,即使从T1上的过滤器查找的次数更少(只有100)。
select /*+ leading(t1 t2) use_nl(t2) */ max(t1.data) from t1, t2
where
t1.id = t2.id + 0
and t1.clus + 0 = 1 ;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
--------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:06.83 | 328K|
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:06.83 | 328K|
| 2 | NESTED LOOPS | | 1 | 36 | 100 |00:00:06.83 | 328K|
|* 3 | TABLE ACCESS FULL| T1 | 1 | 36 | 100 |00:00:00.07 | 3275 |
|* 4 | TABLE ACCESS FULL| T2 | 100 | 1 | 100 |00:00:06.76 | 325K|
--------------------------------------------------------------------------------------
3 - filter("T1"."CLUS"+0=1)
4 - filter("T1"."ID"="T2"."ID"+0)
select max(t1.data) from t1, t2
where
t1.id = t2.id + 0
and t1.clus + 0 = 1 ;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
-----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.09 | 3281 | | | |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.09 | 3281 | | | |
|* 2 | HASH JOIN SEMI | | 1 | 36 | 100 |00:00:00.09 | 3281 | 1753K| 1753K| 1414K (0)|
|* 3 | TABLE ACCESS FULL| T1 | 1 | 36 | 100 |00:00:00.09 | 3275 | | | |
| 4 | TABLE ACCESS FULL| T2 | 1 | 1000K| 1212 |00:00:00.01 | 6 | | | |
-----------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."ID"="T2"."ID"+ 0)
3 - filter("T1"."CLUS"+ 0=1)
select /*+ leading(t2 t1) use_hash(t1) max(t1.data) */ max(t1.data) from t1, t2
where
t1.id = t2.id + 0
and t1.clus + 0 = 1 ;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
-----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.32 | 6526 | | | |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.32 | 6526 | | | |
|* 2 | HASH JOIN | | 1 | 36 | 100 |00:00:00.32 | 6526 | 50M| 9345K| 49M (0)|
| 3 | TABLE ACCESS FULL| T2 | 1 | 1000K| 1000K|00:00:00.03 | 3251 | | | |
|* 4 | TABLE ACCESS FULL| T1 | 1 | 36 | 100 |00:00:00.08 | 3275 | | | |
-----------------------------------------------------------------------------------------------------------------
在谓词过滤器上添加索引:
在t1(clus)上创建索引t1_clus;
而且,由于我们在T1上访问的缓冲区少得多,因此哈希连接的访问速度更快。
从T1驱动的NL仍然必须对T2的每一行进行全表扫描,因此速度很慢。
select max(t1.data) from t1, t2
where
t1.id = t2.id + 0
and t1.clus = 1 ;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
--------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 10 | | |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 10 | | ||
|* 2 | HASH JOIN SEMI | | 1 | 100 | 100 |00:00:00.01 | 10 | 1753K| 1753K| 1408K (0)|
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 100 | 100 |00:00:00.01 | 4 | | ||
|* 4 | INDEX RANGE SCAN | T1_CLUS | 1 | 100 | 100 |00:00:00.01 | 3 | | ||
| 5 | TABLE ACCESS FULL | T2 | 1 | 1000K| 1212 |00:00:00.01 | 6 | | ||
--------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."ID"="T2"."ID")
4 - access("T1"."MILLI"=1)
select /*+ leading(t1 t2) use_nl(t2) */ max(t1.data) from t1, t2
where
t1.id = t2.id + 0
and t1.clus = 1 ;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS'));
--------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
--------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:08:14.23 | 2893K| 2892K|
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:08:14.23 | 2893K| 2892K|
| 2 | NESTED LOOPS | | 1 | 100 | 100 |00:08:14.23 | 2893K| 2892K|
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 100 | 100 |00:00:00.01 | 4 | 0 |
|* 4 | INDEX RANGE SCAN | T1_CLUS | 1 | 100 | 100 |00:00:00.01 | 3 | 0 |
|* 5 | TABLE ACCESS FULL | T2 | 100 | 1 | 100 |00:08:14.23 | 2893K| 2892K|
--------------------------------------------------------------------------------------------------------------------
在T2.id上添加索引,并允许从T1驱动的NL通过索引查找T2中的行,可使NL下降到与HASH JOIN大致相同。
当通过谓词过滤器上的索引访问T1时,HJ在T2的散列上速度更快,但是仍然对所有T2进行散列会使其变慢。
我不明白为什么通过索引而不是全表扫描访问T1时,在T2上进行HJ哈希运算的速度较慢。
drop index t2_id;
create index t2_id on t2 (id);
select /*+ leading(t1 t2) use_nl(t2) */ max(t1.data) from t1, t2
where
t1.id = t2.id
and t1.clus = 1 ;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS'));
-----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 17 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 17 |
| 2 | NESTED LOOPS SEMI | | 1 | 100 | 100 |00:00:00.01 | 17 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 100 | 100 |00:00:00.01 | 4 |
|* 4 | INDEX RANGE SCAN | T1_CLUS | 1 | 100 | 100 |00:00:00.01 | 3 |
|* 5 | INDEX RANGE SCAN | T2_ID | 100 | 1000K| 100 |00:00:00.01 | 13 |
-----------------------------------------------------------------------------------------------------------
select /*+ leading(t2 t1) use_hash(t1) */
max(t1.data) from t1, t2
where
t1.id = t2.id +1
and t1.clus = 1 ;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
--------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.22 | 3255 | | ||
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.22 | 3255 | | ||
|* 2 | HASH JOIN | | 1 | 78 | 100 |00:00:00.22 | 3255 | 50M| 9345K| 49M (0)|
| 3 | TABLE ACCESS FULL | T2 | 1 | 1000K| 1000K|00:00:00.03 | 3251 | | ||
| 4 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 100 | 100 |00:00:00.01 | 4 | | ||
|* 5 | INDEX RANGE SCAN | T1_CLUS | 1 | 100 | 100 |00:00:00.01 | 3 | | ||
-------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."ID"="T2"."ID"+1)
5 - access("T1"."CLUS"=1)
select /*+ leading(t2 t1) use_hash(t1) */
max(t1.data) from t1, t2
where
t1.id = t2.id
and t1.clus = 1 ;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
--------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:01.25 | 2246 | | ||
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:01.25 | 2246 | | ||
|* 2 | HASH JOIN | | 1 | 100 | 100 |00:00:01.25 | 2246 | 43M| 6111K| 42M (0)|
| 3 | INDEX FAST FULL SCAN | T2_ID | 1 | 1000K| 1000K|00:00:00.31 | 2242 | | ||
| 4 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 100 | 100 |00:00:00.01 | 4 | | ||
|* 5 | INDEX RANGE SCAN | T1_CLUS | 1 | 100 | 100 |00:00:00.01 | 3 | | ||
--------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."ID"="T2"."ID")
5 - access("T1"."CLUS"=1)
供参考,NL和HJ访问的顺序和提示
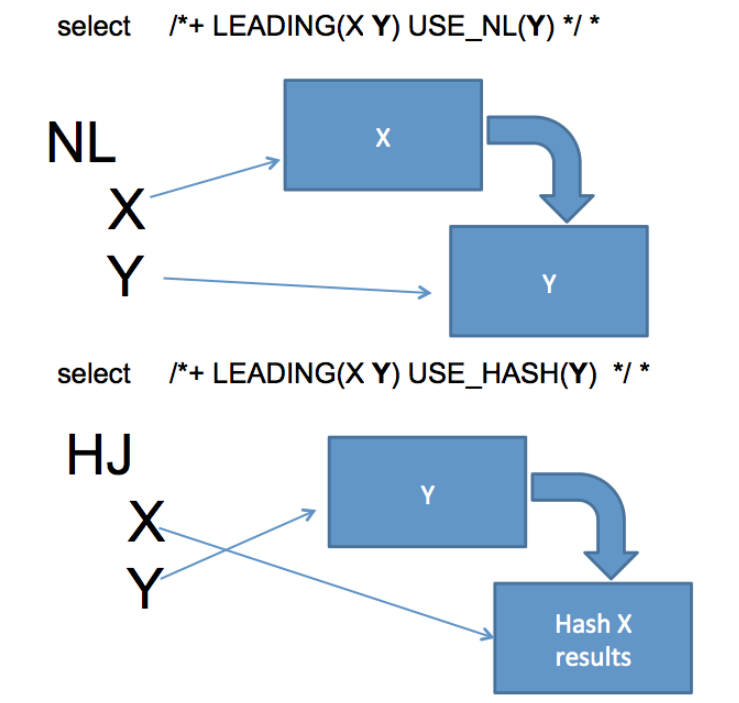
参考
http://datavirtualizer.com/right-deep-left-deep-and-bushy-joins-in-sql/
跟进:
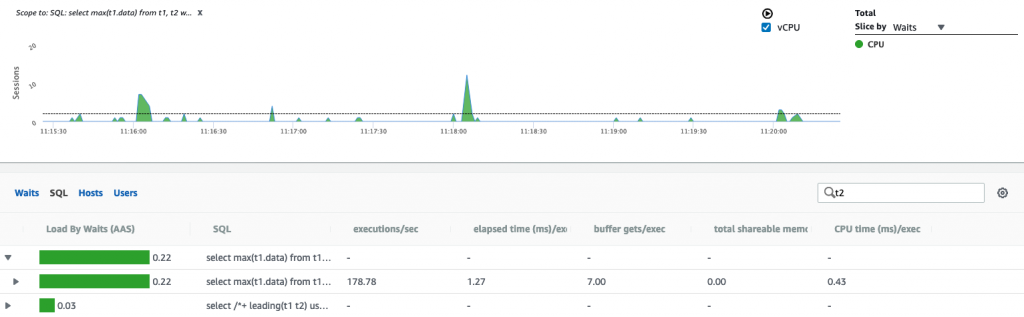
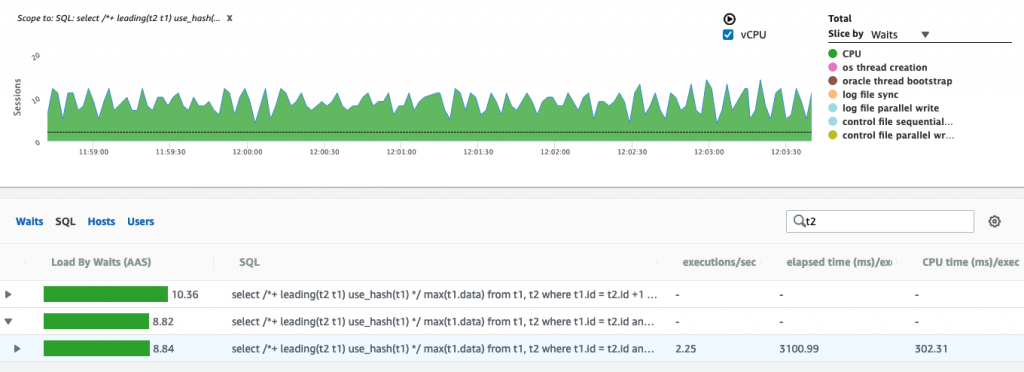
与下一个循环(0.03AAS)相比,哈希联接在DB上的负载大约是数据库的7倍(0.22 AAS),并且两者每秒执行178次。
First Load Chart图像具有用于高效HJ版本的顶部SQL向下钻取过滤器。这里显示了HJ计划。
--------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 10 | | |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 10 | | ||
|* 2 | HASH JOIN SEMI | | 1 | 100 | 100 |00:00:00.01 | 10 | 1753K| 1753K| 1408K (0)|
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 100 | 100 |00:00:00.01 | 4 | | ||
|* 4 | INDEX RANGE SCAN | T1_CLUS | 1 | 100 | 100 |00:00:00.01 | 3 | | ||
| 5 | TABLE ACCESS FULL | T2 | 1 | 1000K| 1212 |00:00:00.01 | 6 | | ||
--------------------------------------------------------------------------------------------------------------------------------
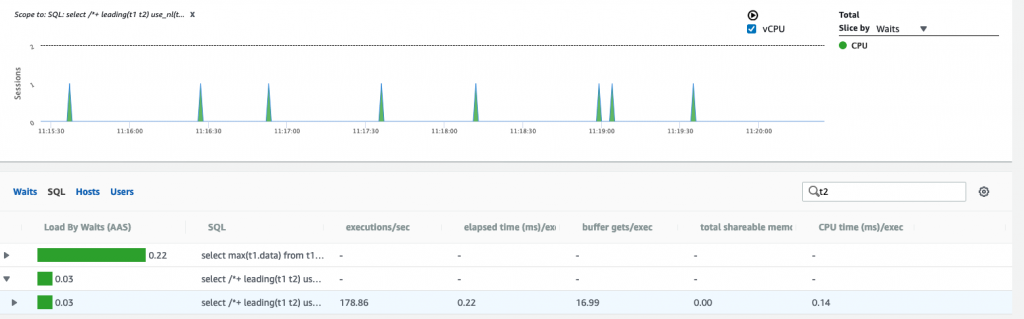
第二张图片是由NJ联接过滤的负载,这是说明。
-----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 17 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 17 |
| 2 | NESTED LOOPS SEMI | | 1 | 100 | 100 |00:00:00.01 | 17 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 100 | 100 |00:00:00.01 | 4 |
|* 4 | INDEX RANGE SCAN | T1_CLUS | 1 | 100 | 100 |00:00:00.01 | 3 |
|* 5 | INDEX RANGE SCAN | T2_ID | 100 | 1000K| 100 |00:00:00.01 | 13 |
-----------------------------------------------------------------------------------------------------------
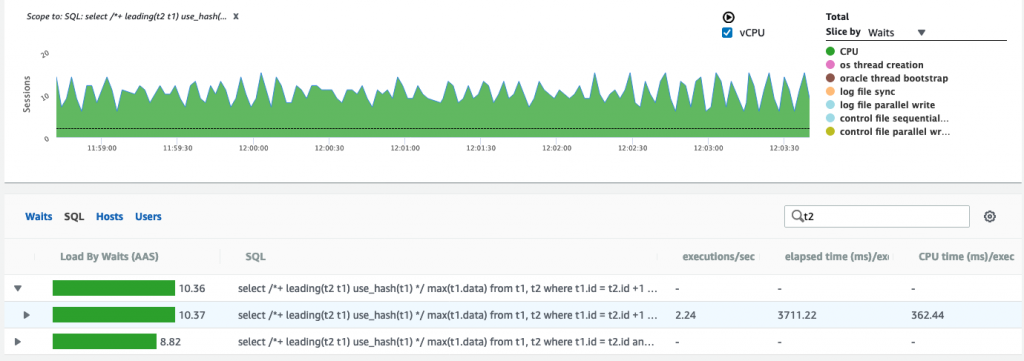
以下散列T2的散列联接并没有像对T1进行有效的散列那样有效,但是它使我感到困惑,在T1过滤器上使用索引比不使用它要昂贵。看起来在实际负载中是另一回事。
即使跳过T1索引显示的A-Time为0.22,而使用T1索引的显示为1.25,当运行并发负载时,它看起来却相反。
下面的第一个示例避免了T1上的索引,并且AAS为10.36,经过了3.7秒(而不是解释中的0.22)
第二个在T1过滤器上使用索引的索引的AAS为8.2,经过的时间为3.1秒(而不是解释中的1.25)
两者都正在执行2.24次执行/秒。
select /*+ leading(t2 t1) use_hash(t1) */
max(t1.data) from t1, t2
where
t1.id = t2.id +1
and t1.clus = 1 ;
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST'));
--------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.22 | 3255 | | ||
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.22 | 3255 | | ||
|* 2 | HASH JOIN | | 1 | 78 | 100 |00:00:00.22 | 3255 | 50M| 9345K| 49M (0)|
| 3 | TABLE ACCESS FULL | T2 | 1 | 1000K| 1000K|00:00:00.03 | 3251 | | ||
| 4 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 100 | 100 |00:00:00.01 | 4 | | ||
|* 5 | INDEX RANGE SCAN | T1_CLUS | 1 | 100 | 100 |00:00:00.01 | 3 | | ||
-------------------------------------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
--------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:01.25 | 2246 | | ||
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:01.25 | 2246 | | ||
|* 2 | HASH JOIN | | 1 | 100 | 100 |00:00:01.25 | 2246 | 43M| 6111K| 42M (0)|
| 3 | INDEX FAST FULL SCAN | T2_ID | 1 | 1000K| 1000K|00:00:00.31 | 2242 | | ||
| 4 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 1 | 100 | 100 |00:00:00.01 | 4 | | ||
|* 5 | INDEX RANGE SCAN | T1_CLUS | 1 | 100 | 100 |00:00:00.01 | 3 | | ||
--------------------------------------------------------------------------------------------------------------------------------
参考:
http://datavirtualizer.com/right-deep-left-deep-and-bushy-joins-in-sql/
http://www.nocoug.org/download/2012-08/Jonathan_Lewis_Creating_Tests.pdf
文章来源:http://www.oaktable.net/content/indexes-joins-oracle
