




hash 索引是 PG/OG 中的一种索引类型。索引中存储经过计算后的 hash code,而不是原始数据值,所以每个索引项占用的空间较小,一定程度上加快了执行速度。另外 hash 索引由于存储的是经过 hash 运算后的 hash code,因此可以支持一些 Btree 索引不能支持的大数据类型(如果索引项超过 8K,Btree索引无法支持)。
hash 索引的特点是查找速度较快,但是也有一些使用限制,例如只能支持等值查询,不支持范围查询;不支持排序;不支持多列索引等,这些都和索引本身的结构有直接的关系。
hash 索引结构
hash 表是一种常见的数据结构,其原理是某一种数据类型的数值映射到 N 个 hash 桶(bucket)中,这样的映射函数称为 hash 函数。使用 hash 表的时候会遇到 hash 冲突(collision),即不同的值映射到相同的 hash 桶,所以在定位到 hash 桶后,还需要在 hash 桶内再查找。
hash 索引的原理与 hash 表一致,只是索引中还需要存储数据 heap tuple 的 TID。PG/OG 中 hash 索引至少包含2个或2个以上的 hash bucket,索引值经过 hash 运算后得到的 hash 值,hash 值再经过一次运算映射到 bucket number,从而确定 index tuple 分布在哪个 hash bucket 中。
对空表建 hash 索引,会初始化2个 hash bucket,随着数据的插入需要更多的 hash bucket 以减少 hash 冲突。
实际在创建索引的过程中,如果表上有数据,不会从 2 个初始 bucket 开始不断通过 split 来扩展 bucket 的数量,而是预估需要的 bucket 的数量,然后一次分配足够的 bucket。
当需要新增 hash bucket 时,对当前存在的 bucket 执行 “split”,原来再这个执行 split 的 bucket 中的某些 index tuples 需要根据更新后的 key-to-bucket-number 的映射关系被转移到新的 hash bucket 中。
索引页
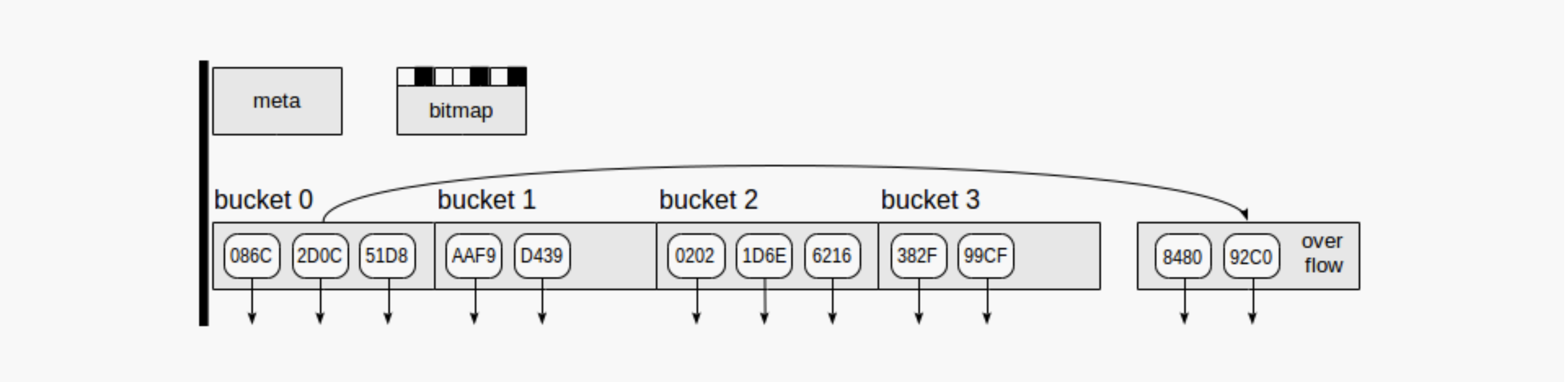
每个 hash bucket 中可能包含多个 page。hash bucket 中的第一个 page 在创建 bucket 时分配,称为 “primary page”;
bucket 中的其他 page 称为 “overflow page”。bucket 中的所有 page 在 special 区域记录左右 page 的信息,组织成双向链表。overflow page 并不与 bucket 绑定,原来被 bucket A 使用的 overflow page,在空闲被释放后可能会被 bucket B 使用。
通过 bitmap page 来跟踪当前哪些 overflow page 是空闲的。
总结一下,hash 索引共有 4 类 page:
1. meta page. page number = 0, 包含索引的元数据和控制信息。
2. primary page. 也称为 primary bucket page,有时简称为 bucket page,是创建 bucket 时分配给 bucket 的第一个 page。
3. overflow page. 当 primary page 空间不够时,会创建 overflow page,但与 bucket 并没有绑定关系,当由于删除操作导致 overflow page 空闲时,会被归还给空闲池,可以被其他 bucket 再使用。
4. bitmap page. 用于跟踪被释放可以被再使用的 overflow page。
同一个 page 内的索引数据,按照 hash code 排序以支持在 page 内使用二分查找,加快查找速度。但 bucket 内不同的 page 之间是无序的。【实际同一个 page 内的 index tuple 也未必是有序的,index tuple 排序是有条件的。】
这部分可以参考代码中的注释部分,只有索引的大小超出 maintenance_work_mem 或可用 buffer 大小时才会排序。
* If we just insert the tuples into the index in scan order, then
* (assuming their hash codes are pretty random) there will be no locality
* of access to the index, and if the index is bigger than available RAM
* then we'll thrash horribly. To prevent that scenario, we can sort the
* tuples by (expected) bucket number. However, such a sort is useless
* overhead when the index does fit in RAM. We choose to sort if the
* initial index size exceeds maintenance_work_mem, or the number of
* buffers usable for the index, whichever is less. (Limiting by the
* number of buffers should reduce thrashing between PG buffers and kernel
* buffers, which seems useful even if no physical I/O results. Limiting
* by maintenance_work_mem is useful to allow easy testing of the sort
* code path, and may be useful to DBAs as an additional control knob.)
*
* NOTE: this test will need adjustment if a bucket is ever different from
* one page. Also, "initial index size" accounting does not include the
* metapage, nor the first bitmap page.
*/
hash 索引只能通过 reindex 命令来回收空间。已经分配的 overflow page 可以回收被其他 bucket 再使用,但不会被归还给操作系统。也没有办法减少 hash bucket 的数量。
bucket split
primary page 是按照 2 的指数分配的,每次分配时 bucket 数量会翻倍。当 bucket 基数很大时,一次分配太多的 bucket 过于粗犷,所以又将 bucket 翻倍的过程拆分为 4 个阶段(phase)。
假设需要新增 2^x 个 bucket,如果分为 4 个 phase,每个 phase 分配的 bucket 数量为 2^x/4 = 2^(x-2)。
在一个完整的 bucket 翻倍的过程中分配的 bucket 称它们处于同一个 split point group,为 split point group 编号,通过编号就可以确定 bucket 的信息。
可以根据 split point group 编号计算出当前的 bucket 数量。例如,初始分配时共分配 2 个 bucket,总的 bucket 数量为 2,此时 split point group = 1;第一次扩展新增的 bucket 数量为 2,总的 bucket 数量为 4,split point group = 2。
如果 split point group < 10,bucket 的基数还不是很大,简单的一次分配完所有 bucket,而不分成 4 个 phase;
split point group >= 10 时,分 4 个 phase 分配。例如 split point group = 10,需要新分配的 bucket 数量为 2^9,每个 phase 分配 2^7。
代码中将新增一批 bucket 称为一个 “splitpoint”,而将每次 bucket 数量翻倍称为一个 “splitpoit group”。 当 splitpoint group < 10 时,一个 splitpoint group 只有一个 splitpoint,而 splitpoint group >= 10 时,一个 splitpoint group 有 4 个 splitpoint。
每个 split point group 的同一个 phase 分配的 bucket page(primary page) 在索引中是连续的。bucket page 是在分配 bucket 时创建的,同一阶段的 bucket 是一起分配的,因此 bucket page 是连续的。
这种分配方式可以从 bucket number 相对容易地计算出 bucket page 的物理地址,只需要使用少量的控制信息。
对于一个 bucket number,通过 _hash_spareindex 计算出它所属的 split point group 及 phase 。
通过 split point group 及 phase 计算出一个全局的 splitpoint phase number S,然后执行 “hashm_spares[S] + 1” + bucket number 来计算对应的 bucket 的物理地址。
splitpoint group < 10 时,每个 splitpoint group 有一个 phase;splitpoint group >= 10 时,每个 splitpoint group 有 4 个 phase。
举例:假设现在的 bucket 数量是 896,根据规则计算出 splitpoint group = 10,phase = 2 (0,1,2,3),则计算出的全局 splitpoint phase = 10 + (10 - 10) * 4 + 2 = 12。
其中 hashm_spares[] 是存储在 meta page 中的数组,hashm_spares[S] 可以认为是在 splitpoint phase S 前所有已经分配的 overflow page 的总数(还有 bitmap page,虽然 bitmap page 的数量可能很少)。
其中 hashm_spares[0] = 0,因此 bucket 0 和 bucket 1 的 bucket page 的 block number 分别是 1 和 2。
显然 hashm_spares[N] <= hashm_spares[N+1],hashm_spares[N+1] - hashm_spares[N] 表示在 phase N 和 phase N+1 之间增加的 overflow page 和 bitmap page 的数量。
举例说明:
初始 hash bucket 数量为 2,假设最大的 page 数是 hash 桶数的 4 倍(代码中根据 tuples/buckets 来确定是否需要分裂)。则 2 个 hash bucket 最大有 8 个 page,超过这个数量就需要 bucket split。

则根据计算公式 page number = “hashm_spares[S] + 1” + bucket number,可以计算出 split point group = 2,bucket 2 的 primary page 的 page number = 7 + 1 + 2 = 10,即 bucket 2 的 primary page 的 block number = 10,同样可以算出 bucket 3 的 primary page 的 block number = 11。
当 S 个 split point 完成后,hashm_spares[0] 到 hashm_spares[S] 都是有效的;其中 hashm_spares[S] 记录当前 overflow page 和 bitmap page 的总数。
新的 overflow page 根据需要进行分配,然后通过增加 hashm_spares[S] 来记录。
当需要新增一个 split point phase 时,拷贝 hashm_spares[S] 的值到 hashm_spares[S+1],然后增加 S 的值(存储在 meta page 的 hashm_ovflpoint 字段)。
通过这种方式可以预留正确数量的 bucket page,同时为在这些 bucket page 后面分配 overflow page 做准备。
hashm_spares[] 中 S 之前的项不能修改,因为那会导致已经创建的 bucket page 需要移动。
由于 overflow page 可以被回收再使用,因此需要有机制跟踪当前空闲可用的 overflow page。
overflow page 的状态(0 表示可用,1 表示不可用)记录在 bitmap page 中。 bitmap 中的项通过 “bit number” 进行索引,bit number 从 0 开始,每一个 overflow page 用一项表示。
通过 hashm_spares 可以在 overflow page 的 block number 和 bitmap page 中的 bit number 之间进行转换。
并发控制
hash 索引中对 bucket 中的 primary page 加 cleanup lock,意味着可以对整个 bucket 进行重写。
如果需要对多个 bucket 加锁,为避免死锁,总是先对 bucket number 较小的加锁。
meta page 加锁是在所有 bucket 上的锁加完以后。
扫描和插入都需要定位到具体的 bucket,这需要先从 meta page 获得 bucket 的数量、highmask 以及 lowmask。但是处于性能考虑,不可能每次操作都去对 meta page 加锁。
为此,在 relcache 中存储 meta page 的缓存副本。只要对应的 bucket 没有 split,缓存的信息都还是正确的。
为应对可能发生的 split,每个 bucket 的 primary page 在 hasho_prevblkno 字段存储上次 split 后 bucket 的数量。
这样做没有什么额外的代价,因为 primary page 是 bucket 的第一个 page,hasho_prevblkno 存储的是它之前的 page 的 block number,通常它的值是 InvalidBlockNumber。
根据 meta page 缓存副本计算得到 bucket number 后,对 bucket 的 primary page 加锁,检查 primary page 中存储的 bucket 数量是否大于 meta page 缓存副本中的 bucket 数量。
如果大于,那么一定是 bucket 发生了 split。因为 primary page 中存储的 bucket 的数量,初始时是小于当时实际的 bucket 数量的,除非发生 split 否则不会增加。这种情况下,需要释放 bucket 上的锁,重新获取 meta page 更新缓存信息,然后重试。
如果 primary page 中存储的 bucket 数量不大于 meta page 缓存中的 bucket 数量,则肯定没有发生 split。因为如果发生 split,会创建一个新的 bucket,新创建的 bucket 的 bucket number 比之前的 bucket 的 bucket number 都大。
重试的代价很高,但是每个 bucket split 的次数实际是有上限的,因为桶的总数被限制为小于 2^32,所以跟访问 bucket 的次数比起来发生 split 的次数的量级实际是很小的。
在 hash 索引相关的操作中使用了很多的 flag,其中:
bucket-being-split 和 bucket-being-populated 表明 bucket 处于 split 过程中,bucket-being-split 在老的 bucket 上设置 ,而 bucket-being-populated 在新的 bucket 上设置 。一旦 split 执行完成,这两个 flag 会立即清除。
split-cleanup 表明刚发生 split 的 bucket 还没有移除已经拷贝到新 bucket 中的 tuples;这表明 split 还未完全完成。
一旦确定没有在新的 bucket 填充完成前对老的 bucket 的 scan 在执行,就可以从老的 bucket 中删除这些副本,并清除 split-cleanup flag。这个标记需要在下一次 split 前清除,否则无法执行下一次 split。
tuple 上的 moved-by-split 标记表明这个 tuple 是从老的 bucket 移动到新的 bucket 的。并发的 scan 会跳过有这些标记的 tuple,直到 split 完成。
一旦 tuple 被标记为 moved-by-split 就不会清除这个标记,这个并没有什么副作用。不清除这个标记的原因是不想引起不必要的 I/O。
索引操作
当前 hash 索引支持的操作包括:
1. 读操作根据指定的 hash code 扫描索引项
2. 向正确的 hash bucket 中插入新的 index tuple
3. 通过 split 扩展 hash bucket
4. garbage collection(删除 dead tuples,bucket 空间压缩)
split 动作是由插入引起,一旦 hash table 超过设定的 load factor,就会执行 split,但可以将其视为独立的动作。
注意,没有 bucket-merge 操作,因为 bucket 数量永远不会收缩。
insert、split 和 gc 都需要访问空闲空间管理,该模块跟踪可用的 overflow page。
读操作
如果目标 bucket 还在 split 填充的过程中
释放 primary page 上的 lock 及 pin,pin 老的 bucket,对其加 shared lock
释放老的 bucket 上的 lock,但保留 pin
重新对新的 bucket 加 shared lock
正常 scan 老 bucket 及新 bucket 中未标记为 moved-by-split 的 tuple
然后,对每个读请求:
重新获取当前访问 page 的 lock
如果有必要,访问下一个 page(访问过程会 pin primary page,同时也会 pin 当前访问的 page)
获取 tuple
释放 page 的 lock
读操作执行完成:
释放所有的 pin
在整个 scan 的过程中需要 pin primary page,防止读操作当前访问到的位置被 split 或 compaction 动作修改失效。(这个过程中,其他 bucket 仍然可以执行 split 或 compaction)。
为了并发能力,需要让读操作能够处理并发的写,这意味着读操作需要能够重新找到释放 lock 前 scan 到的位置。
由于执行了 pin,删除动作在 bucket 中是不会发生的。假设 heap tuple 的 TID 都是唯一的,重新找到 scan 的位置,可以通过查找到上次返回的 TID 来实现。
插入动作不会导致索引项跨 page 移动,因此上次返回的索引项还在同一个 page 中,在同一个 page 相同的位置,或者偏移更大的位置。
为支持 split 期间执行 scan,如果在 scan 开始时 bucket 被标记为 bucket-being-populated,scan 操作扫描 bucket 内的所有 tuple,除了有 moved-by-split 标记的。
一旦完成对当前 bucket 的扫描,scan 还需要扫描老的 bucket,新的 bucket 是从老的 bucket split 出来的。
写操作
如果 bucket 上有 bucket-being-split 标记,而且 pin 的数量是 1,则完成 split 动作,具体如下
释放 primary page 的 exclusive lock
获取 split 新创建的 bucket
scan 新 bucket,组织索引数据
尝试获取新老 bucket 上的 cleanup lock
如果新老 bucket 上的 cleanup lock 都获取到了
使用下面描述的 split 算法完成 split
释放老 bucket 上的 pin,然后重新执行 insert
如果当前 page 满了,首先检查当前 page 是否包含 dead tuples
如果包含 dead tuples,则移除 dead tuples,然后检查空间是否足够插入。如果够则执行插入,否则释放 lock 但保留 pin,然后检查下一个 page;重复上述动作。
>> 如果 bucket 中所有 page 都不满足插入条件,则可能需要执行 split,这个在后面描述
对 meta page 加 exclusive lock。每个 insert 都需要修改 meta page ?
在 page 的合适位置插入 index tuple
page 标脏
增加 meta page 中的 tuple 计数,决定是否需要 split
meta page 标脏
写 WAL
释放 meta page 的 exclusive lock
释放当前 page 的 exclusive lock
如果当前 page 不是 primary page,释放 primary page 上的 pin
如果需要 split,执行下面的 split 算法
释放 meta page 的 pin
当写操作无法在 bucket 内的 page 中找到合适的插入位置时,需要获取一个 overflow page,然后将其加入到 bucket 的链表上。这部分算法后面介绍。
split
split 算法在索引空间溢出(填充率超出预设值)时运行,该算法会尝试执行,但不一定会成功。split 算法将 1 个 bucket 拆分为 2 个 bucket,从而降低每个 bucket 的填充率。
具体步骤如下:
检查是否需要 split
如果不需要 split,释放 meta page 上的 lock 和 pin,然后退出
需要 split
确定 split 哪个 bucket
对 bucket 加 cleanup lock,如果加锁失败,放弃执行
如果 bucket 处于 split 过程中,或者有 split-cleanup 相关任务:
尝试完成 split 和 split-cleanup
如果成功,则重头开始本次 split;失败,放弃执行
标记新老 bucket 处于 split 过程中
新老 bucket 标脏
写 WAL 记录 split 过程中新申请的 page
拷贝老 bucket 中需要移动到新 bucket 的 index tuple 到新申请的 page 中,将这些 tuple 标记为 moved-by-split
写 WAL 记录。如果新 page 写满,或者整个拷贝过程结束。
释放老 bucket 上 primary page 的 lock,但保留 pin,然后处理下一个 page,重复上述动作直至结束。
清除新老 bucket 上处于 split 过程中的标记,老 bucket-being-split,新 bucket-being-populated
正确设置老 bucket 上的 split-cleanup 标记
写 WAL 记录新老 bucket 上的变化
split 尝试获取老 bucket 上的 cleanup-lock 可能会失败,如果有其他任务在 bucket 上加了任意类型的 lock 或者有 pin。
如果发生这种情况,不会去等待锁获取到,因为当前还持有 meta page 的 exclusive lock。所以这是一个条件 LWLockAcquire 操作,如果失败就放弃执行 split。
每个插入都可能去尝试执行 split,最终总会成功。
如果 split 因为其他原因失败,例如磁盘空间不足,索引不会损坏。在执行插入时,会先尝试 split,再执行 insert。
某个 split 没有完成不会阻塞后续 bucket 被拆分,但对于同一个 bucket 如果前一次 split 未完成,不会进行下一次 split。
Garbage Collection
garbage collection 用于删除 dead tuple 占用的空间,压缩 bucket
伪代码如下:
next bucket := 0
pin meta page,对 meta page 加 exclusive lock
从 meta page 获取 bucket number 的最大值(hashm\_maxbucket)
释放 meta page 的 lock 和 pin
while next bucket <= max bucket number do
获取 primary page 的 cleanup lock
loop:
scan and remove tuples
mark the target page dirty
write WAL for deleting tuples from the target page
if this is the last bucket page, break out of loop
pin and x-lock the next page
release prior lock and pin (except keep pin on primary page)
if the page we have locked is not the primary bucket page:
release lock and take exclusive lock on primary bucket page
if there are no other pins on the primary bucket page:
squeeze the bucket to remove free space
release the pin on primary bucket page
next bucket ++
end loop
pin meta page and take buffer content lock in exclusive mode
check if number of buckets changed
if so, release content lock and pin and return to for-each-bucket loop
else update metapage tuple count
mark meta page dirty and write WAL for update of metapage
release buffer content lock and pin
这个设计允许并发的 splits 和 scans。如果发生 split,则被移动到新的 bucket 中的 tuples 被访问了两次。
当 cleanup scan 期间释放 primary page 上的 lock 时,允许并发的 scan 执行,同时确保 scan 一直落后于 cleanup。
必须保证 scan 落后于 cleanup,否则 vacuum 可能导致 scan 操作扫描出的 TIDS 减少。
空闲空间管理
空闲空间管理主要有俩个子算法,一个用于获取空闲的 overflow page 加到 bucket 的链表中;另一个用于将空的 overflow page 归还到空闲池。
获取 overflow page :
对 meta page 加 exclusive lock
确定下一个 bitmap page number;如果完成,退出循环
释放 meta page 上的 lock
pin bitmap page,对 bitmap page 加 exclusive lock
查找空闲的 overflow page (在 bitmap 中值为 0)
如果找到:
将位图中对应的位置为 1
bitmap page 标脏
对 meta page 加 exclusive lock
如果 first-free-bit 值未发生修改,
更新 first-free-bit,将 meta page 标脏
如果没有找到:
释放当前 bitmap page 上的 lock
如果有下一个 bitmap page,则尝试在下一个 bitmap page 查找
--如果所有的 bitmap page 都查找过了
对 meta page 加 exclusive lock
新增一个 overflow page;更新 meta page
meta page 标脏
返回新增的 overflow page number
上述过程反复对 meta page 执行加锁和放锁的动作,这个过程有点烦人,但可以尽量减少并发的损失。如果一直持有锁,可能导致并发能力下降。
调用上面的获取 overflow page 算法的插入流程如下:
-- 首先是检测到目标 bucket 中没有空闲空间可以插入
记住 bucket 中访问的最后一个 page,释放这个 page 上的 write lock
重新对最后一个 page 加 write lock
如果加锁的 page 已经不是最后一个 page,则移动到最后一个 page
执行上面描述的获取 overflow page 的算法
更新最后一个 page,让其链接到获取到的 overflow page,然后将其标脏
对 overflow page 加 write lock,然后对其初始化,将其前向指针连接到之前最后一个 page
写 WAL 记录增加的 overflow page
释放 free-page-acquire 算法中 meta page 和 bitmap page 上的 lock
释放之前的最后一个 page 上的 lock
释放 overflow page 上的 lock
对新的 page (overflow pahge)执行插入
这里处理了同时两个并发的写操作都去扩展 bucket 的情况,最终结果是两个 overflow page 被加入到 bucket 中,每个 overflow page 中有一个 tuple。
bucket split 的算法类似,但不需要担心并发 split 的问题,因为会对新的 bucket 加 exclusive lock
释放 overflow page :
从 bucket 链上取下 overflow page,这个过程需要更新这个 overflow page 左右的关联 page
pin meta page 对 meta page 加 shared lock
确认这个 overflow page 对应的 bitmap 位在哪个 bitmap page 中
释放 meta page 的 lock
pin bitmap page,对 bitmap page 加 exclusive lock
重新对 meta page 加 exclusive lock
移除被释放的 oveflow page 中的 tuples
更新 bitmap 位
bitmap page 标脏
如果释放的 overflow page 的 page number 小于 first-free-bit,更新 meta page 中的 first-free-bit,meta page 标脏
写 WAL 记录 overflow page 释放的操作
释放 bitmap page 上的 lock 和 pin
释放 meta page 上的 lock 和 pin
这里需要先清除 bitmap 位,然后修改 first-free-bit (即 meta page 中的 hashm_firstfree)。
可能存在将 first-free-bit 设置的太小的情况,因为刚释放的 overflow page 马上就被使用了,但这不影响正确性,代价是查找空闲的 overflow page 的任务可能需要多找一些。
但是必须防止出现 first-free-bit 设置得太大的情况,因为这意味着被释放的 overflow page 可能永远不会被查找到。
在将 overflow page 从 bucket 链上取下时执行移除 tuple 是为了让整个操作成为原子操作。
如果不这样做可能导致 standby 上出现虚假读,相同的 tuple 用户可能会看到两次。
WAL
hash 索引的相关操作,如 创建索引、插入、删除、bucket split、分配 oveflow page、以及空间压缩等在发生 crash 的时候不能保证一致性,因此在执行这些操作时需要写 WAL。
CREATE INDEX
创建索引需要写多条 WAL 记录,首先需要记录 meta page 的初始化,然后需要记录每个 bucket 的创建,以及 bitmap page 的初始化。
这个过程不需要原子性,因为整个索引对外还不可见,如果中间发生 crash ,创建流程会回滚。
同时整个过程中要在一条 WAL 中记录是很困难的,因为一条 WAL 记录中最大只能包含固定数量的 page,这个数值在当前的 WAL 机制中是 XLR_MAX_BLOCK_ID(32)。
INSERT
普通插入操作(不需要 split 或新的 overflow page)只需要一条 WAL 记录,过程只涉及一个 bucket page 及 meta page。
如果插入导致需要新增 oveflow page,则新增的 overflow page 需要一条记录,然后插入操作需要一条记录。
如果插入操作导致 bucket split,那么插入操作需要一条记录,新的 bucket 需要一条记录,新的 bucket 中的每个 oveflow page (需要从老的 bucket 移动 tuples 到新的 bucket)有一条记录 , split 完成有一套记录表明新老 bucket 上的 split 相关操作都已经完成。
如果 split 需要新申请 overflow page,每个新申请的 overflow page 需要一条 WAL 记录。
SPLIT
由于 split 包含多个原子操作,可能出现向新 bucket 中移动 tuples 的时候 crash 的情况。
这种情况下,恢复以后老的 bucket 被标记为 bucket-being-split,新的 bucket 被标记为 bucket-being-populated,表明 split 还未完成,读操作可以正确处理这种情况。
然后在老的 bucket 下一次 insert 或者 split 时候完成之前的 split。读操作也可以完成残留的 split,但是最好不要在只读流程中去增加额外的更新动作。
在 vacuum 流程中完成 split 看起来是一件很自然的事情,但是由于 split 可能需要新申请 page,可能在磁盘空间不够的情况下出现失败。
这样可能导致 vacuum 失败。执行 vacuum 本来是为了释放空间,现在因为空间不够导致 vacuum 失败这样设计有些不合理。
DELETE
从 bucket 删除 tuple 有两个原因,一是删除 dead tuple,另一个是删除 split 后老 bucket 中已经拷贝到新 bucket 的那些 tuples。
每个执行删除操作的 page 需要一条 WAL 记录,另外还需要清除 needs-split-cleanup 标记也需要一条记录。当 dead tuples 被删除后,更新 meta page 还需要一条 WAL。
由于删除包含多个原子操作,中间可能出现 crash 的情况。如果在 (a) 从 bucket page 删除 tuples, (b) 清除标记位,或 (c) 更新 meta page 中间发生 crash。
如果在完成 (b) 之前发生 crash,会在恢复后下次 vacuum 或者 insert 再次尝试去清理 bucket。这可能会有一些性能影响,但逻辑没问题。
如果在完成 (c)之前发生 crash,可能在下次 vacuum 更新 meta page 之前可能会导致额外发生一些 split,但对于其他操作,如 insert、delete 和 scan 没有影响。
解决这个问题可以在回放期间基于删除操作来更新 meta page,但是这样做带来的复杂性可能需要权衡。
压缩操作(squeeze) 将 tuple 从 bucket 链上靠后的 page 移动到靠前的 page 中,并在被移入 tuple 的 page 写满或者移出 tuple 的 page 变为空的时候记录 WAL。
squeeze 包含多个写操作,中间可能会发生 crash。恢复后,操作可以正常执行,但索引膨胀的问题没有解决,这可能对读写操作性能有些影响,直到下一次 squeeze 执行。
cleanup lock 可以防止一个 bucket 中一个 split 执行时,又发生另一个 split。同时也可以保证我们自己的后台 scan 不会被中止。
本文主要介绍了 hash 索引的原理、结构及内部机制,下一篇将从代码实现角度介绍 hash 索引的具体实现。
参考:
https://postgrespro.com/blog/pgsql/4161321
https://git.postgresql.org/gitweb/?p=postgresql.git;a=blob;f=src/backend/access/hash/README;hb=HEAD
