




分享嘉宾:祝海林 Kyligence 技术合伙人 Byzer PMC
出品平台:DataFunTalk
导读:近日,Kyligence 开源项目 MLSQL 宣布正式更名为 Byzer。与此同时,全新的 Byzer 开源社区也正式成立。Byzer 这一名称源于中国古代神兽“白泽”,其能言语,通万物之情,知鬼神之事。Byzer 语言创始人祝海林提到:“我们希望 Byzer 可以像神兽白泽一样,让数据说‘人’话。”据了解,Byzer 将秉持低成本落地 Data + AI 的技术初衷,并融合更加开放且多元的语言及产品能力,打造更加完善的新一代开源语言生态。
01
现如今,企业如果想要有效地落地 Data + AI ,往往需要多种工具协作,这对企业和数据工程师来说也是不小的挑战。从公司角度来说,其主要面临 ROI 低、缺少 ML 专家、机器学习实操困难以及部署复杂、难以维护等问题。
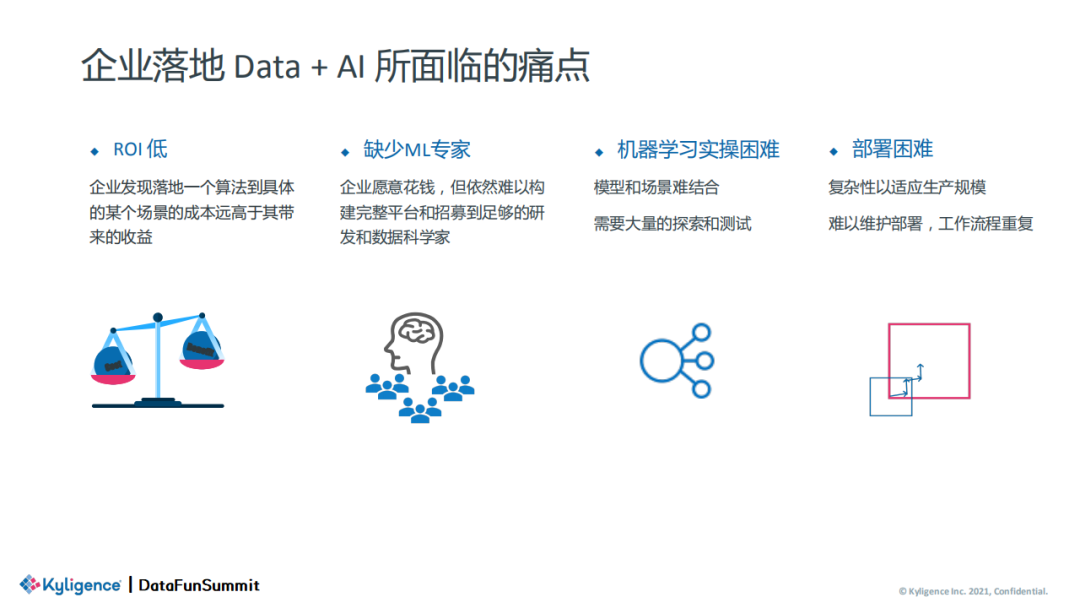
而对一线数据工程师而言,则需要在冗长的数据链路中通过各种平台和组件的调用去完成端到端的 Data + AI 落地。总体来看,企业和一线人员其实花了大量的精力在解决这些组件以及数据上的问题,却没有太多的时间花在深入场景和 AI 的落地上。随着大数据、人工智能、云计算等技术的迅速发展,云基础设施、基础软件、算法模型等都逐渐完善和成熟,业界对数据平台的效率诉求越来越高,低效的跨平台数据运转逐渐成为工程师落地数据平台和完成 AI 工程化的痛点。但是,无论是从更换基础设施入手,还是换上更易用的框架,又或是引进更优秀的研发人才,都难以做到大幅度的效率提升。
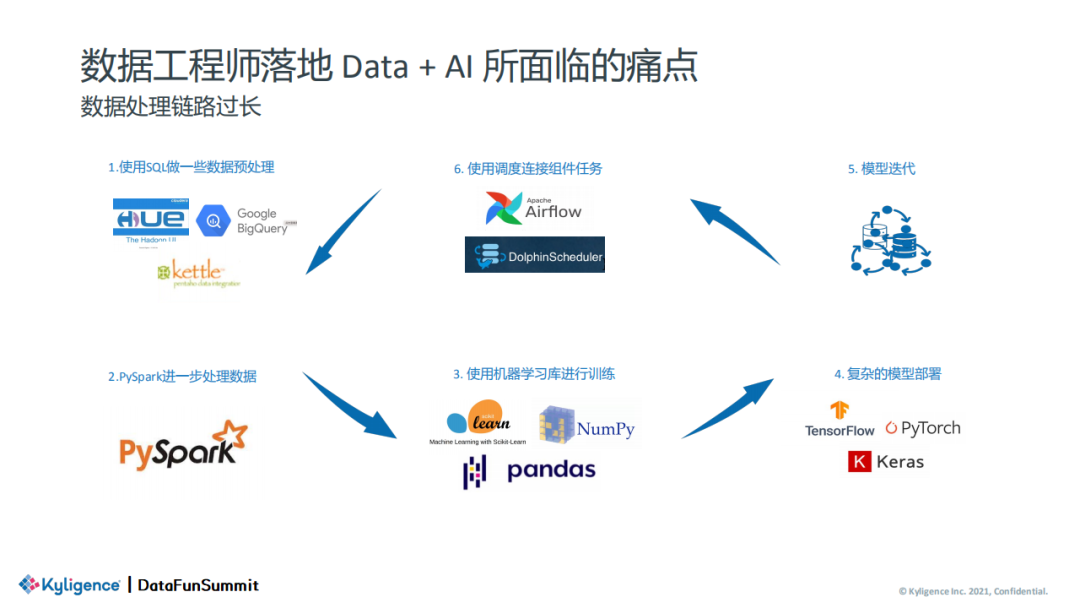
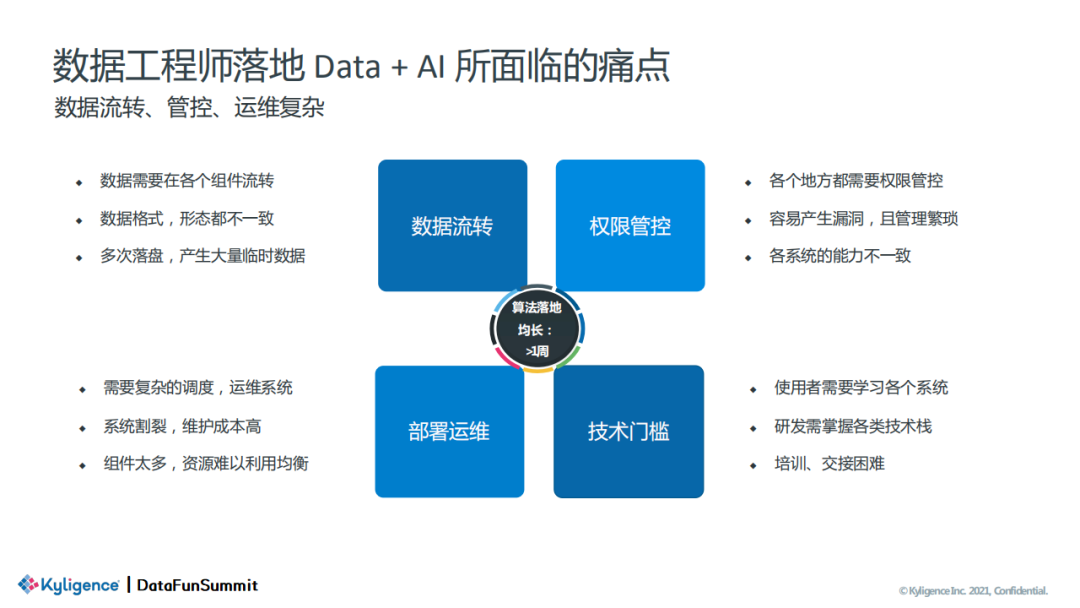
所以,如何真正提高效率来落地数据平台和 AI 工程化?Byzer 团队认为只有在编程语言层面进行革新,才能从根本上提高效率。Byzer 作为一门低代码的开源编程语言,致力于更好地打通复杂的数据链路,实现低成本的数据分析和 AI 落地。
02
Byzer 的发展历程,打造新一代开源语言生态
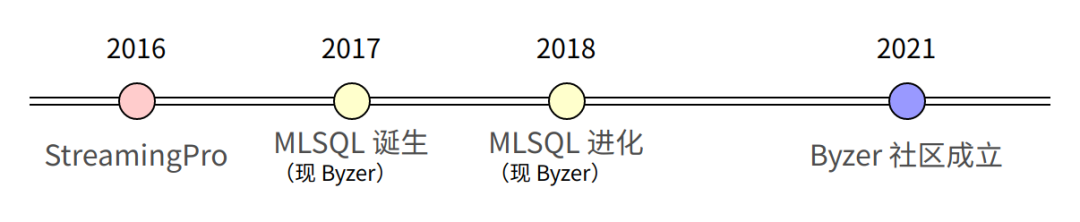
1. 开源之路 — 源起
项目刚刚开源时的定位:“Declarative workflows for building Spark Streaming”,翻译过来就是通过申明式工作流构建 Spark Streaming 程序。起初的目的是为了简化 Spark Streaming 的开发,提升流数据处理的效率,于是有了 StreamingPro 的诞生。之后, StreamingPro 日渐成熟且扩展性也不错,但是在使用的过程中,依旧存在部分问题:
首先, json 并不是一个很好的表达方式,在里面写 SQL 很痛苦。
另外,配置只是换了写代码的方式,程序还是要每次运行的时候提交到 yarn 集群。这也就意味着只有拥有跳板机的同学才能使用。这样除了部分研发以外,其他人都没办法用,而且启动慢。
因此祝海林萌生重新开发一套 DSL 的想法。这套 DSL 经过发展,就变成了后来的 Byzer。
2. 开源之路 — 进化
到了 2017 年的时候,Byzer 做了两个显著的改变:
Spark 应用变成服务,提供 Rest 接口执行 Byzer 脚本,不再是按 Application 的方式执行。
Byzer 脚本正式取代了Json 配置文件。
在这一年里,基于 Byzer 诞生了一整套周边系统,包括动态 DAG 调度(类似 Airflow 等),脚本管理系统,前端 Web 等等,这个过程我们依然只是把 Byzer 定位在 ETL 环节。
3. 开源之路 — 扩大版图
之后,为了衍生 Byzer 的能力,更好地支持算法团队,团队以 PySpark 为出发点,先后研究了探索了 Spark Deep Learning, TFoS 等项目。有了上面的积累后,Byzer 添加了对 Spark MLlib 库的支持,train/ predict/ run 等语法也是这个时候引入的。此时,Byzer 语言真正做到了实现 Data + AI 的统一。随着项目的进一步发展,Byzer 秉持低成本落地 Data + AI 的技术初衷,并融合更加开放且多元的语言及产品能力,打造更加完善的新一代开源语言生态。
03
Byzer 四大特性降低成本,释放员工生产力
Byzer 旨在帮助用户以低成本和高效率的方式落地数据平台和完成 AI 工程化,释放数据分析师、工程师以及运维人员的生产力。其主要有以下四点特征:
万物皆表(Everything is a table):
Byzer 语言的核心设计是万物皆表(Everything is a table),我们希望用户可以非常容易的将任何实体对象通过 Byzer 来抽象成二维表,从而能够基于表来进行数据处理或模型训练等进一步操作。Byzer 可以通过虚拟表串联数据流,做到多数据源无缝对接,并同时支持模型的批、流、API的一键部署。
类 SQL 语法(SQL-like Language):
在语言设计层面,Byzer 采用了声明式融合命令式语言编程设计,SQL-like 语法简单又灵活。
内置算法和插件(Built-in Algorithms and Plugins):
支持 Python、标准库、使用自定义 UDF(Scala/Java)。内置大量算法和特征工程工具,帮助平民分析师更快上手机器学习。
可定制,简单,强大(Customizable, Simple and Powerful):
Byzer 通过一套语言、一个引擎,就能覆盖整个数据链路,开箱即用。且 Byzer 从 Day1 起就是云原生设计,同时原生分布式引擎(Spark 引擎和可插拔 Ray引擎)的设计,可以让 Byzer 充分实现算力和存储的云端扩展。
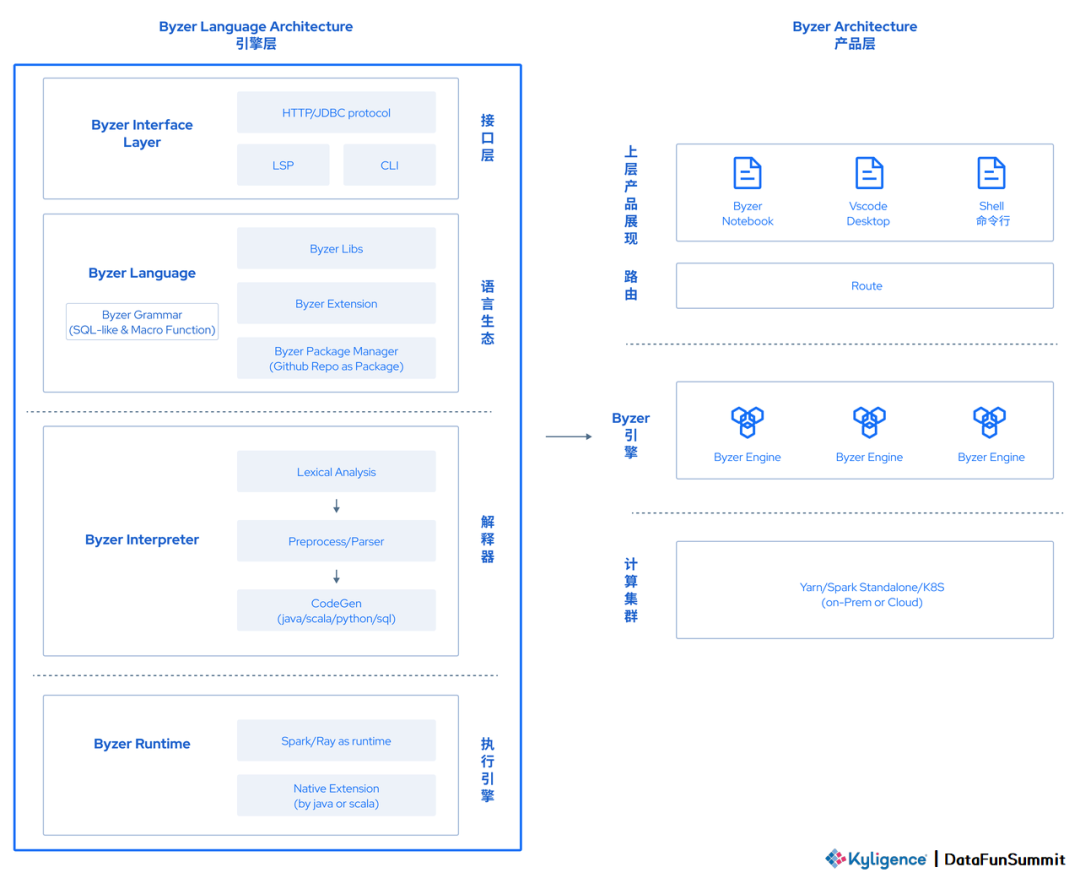
上图为 Byzer 架构图,我们可以看到 Byzer 作为一个解释型语言,拥有解释器(Interpreter)以及运行时环境(Runtime),Byzer 的 Interpreter 会对 Byzer 的脚本做词法分析、预处理、解析等,然后生成 Java/ Scala/ Python/ SQL 等代码,最后提交到 Runtime 上进行执行。
Byzer 使用 Github 作为包管理器(Package Manager),有内置 lib 库和第三方 lib 库(lib 库是使用 Byzer 语言编写出的功能模块)。
从上述设计理念实现而来,Byzer 既保留了 SQL 的优势,简洁易懂,还允许用户通过扩展点来进行更多的进阶操作,提供更多可编程能力。
04
这是一个非常典型的企业管理案例。目前,Kyligence 团队内部使用多款 SaaS 软件来进行项目管理、客户管理等。如何分析和利用好散落在各个 SaaS 系统中的数据,反哺和赋能企业自身的管理和运维能力,成为了公司专职管理人员的关注的重点。因此,Kyligence 在 Azure 上基于 Kylingence Cloud 建立了一个分析系统 —— Flag 来分析业务需求。随着Flag 承接的需求日益增多,需要整合的数据也越来越多,因此 Byzer 上线生产,有效帮助了公司分析和管理数据资产。
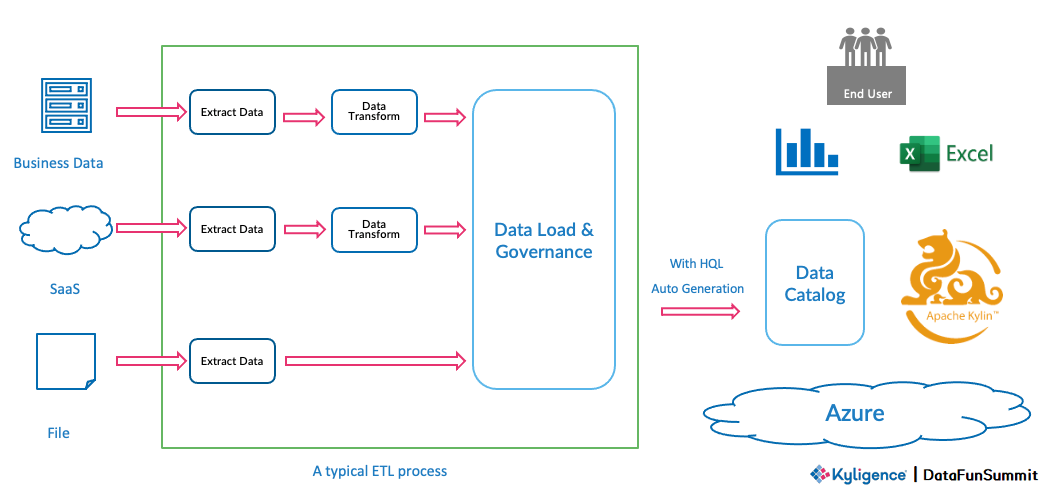
1. 上线 Byzer 前 Flag 平台遇到的问题与挑战
数据流转:公司要接的数据源有飞书、Jira、Wiki、Worktile、ZoHo、CSV、DB库等等,数据源的接入需要逐一适配、多次落盘,产生大量临时数据。
权限管控:各个地方都需要权限管控,管理相对繁琐。
部署运维:专职管理人员需要请求数据开发工程师完成复杂的需求和调度,且系统割裂,维护成本高。
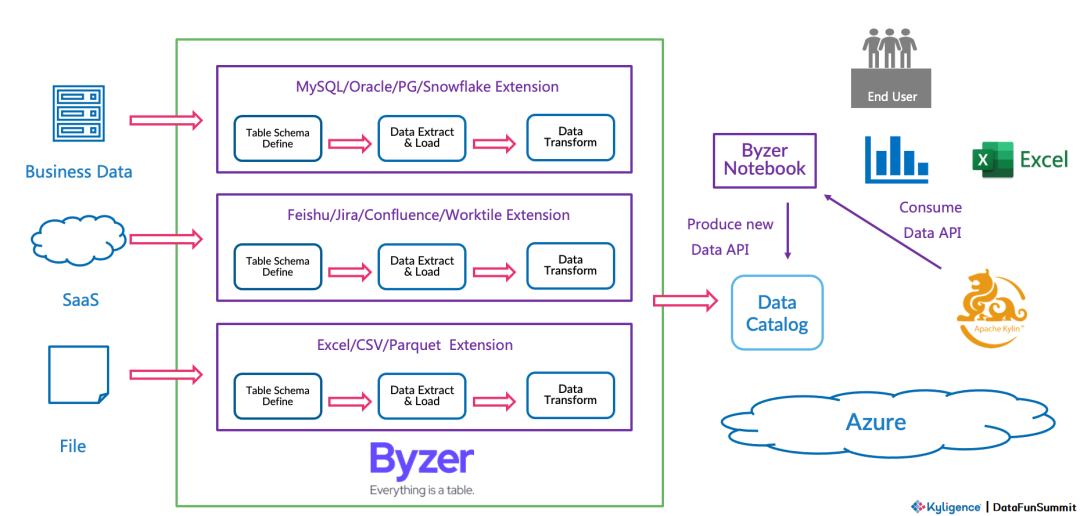
2. Byzer 上线之后优化的方案
单平台覆盖完整数据链路:利用 Byzer 的能力,则可以简化繁琐的 ETL 数据流程,对接企业内使用的各种 SaaS 系统,进行取数,清洗,整理,然后落盘至云上的对象存储中,然后使用上层 OLAP 引擎和 BI 产品进行建模分析和报表可视化,解放工程师。
数据结果高效输出:同步优化了端到端数据链路,利用 Byzer 将一些关键信息通过飞书插件和邮件通知到指定人员。
灵活易运维:赋能平台运维管理员,以后有需求可以自己写 Byzer 语言完成。
Byzer 上线之后
05
Byzer 未来规划,共建智能时代的数据生态
数字化转型进程正在加快,随着组织内部部署的数字化应用增长,数据烟囱问题日益突出,如何提升开发效率、降低数据获取门槛、促进数据文化素养、以 AI 获取竞争优势是当下亟需关注的问题。作为一门编程语言,Byzer 赋能企业优化数据资产,降低企业成本和提高运营效率。与此同时,Byzer 社区将继续下沉开源,联合其他的开源社区,共建智能时代的数据生态,帮助中小企业低成本地落地大数据平台和打造更多有价值、可信赖的产品。
今天的分享就到这里,谢谢大家。
点击下方 关注 Byzer Community
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

关于 Kyligence
Kyligence 由 Apache Kylin 创始团队创建,致力于打造下一代智能数据云平台,为企业实现自动化的数据服务和管理。基于机器学习和 AI 技术,Kyligence 从多云的数据存储中识别和管理最有价值数据,并提供高性能、高并发的数据服务以支撑各种数据分析与应用,同时不断降低 TCO。Kyligence 已服务中国、美国及亚太的多个银行、保险、制造、零售等客户,包括建设银行、浦发银行、招商银行、平安银行、宁波银行、太平洋保险、中国银联、上汽、一汽、安踏、YUMC、Costa、UBS、Metlife、AppZen 等全球知名企业和行业领导者。公司已通过 ISO9001,ISO27001 及 SOC2 Type1 等各项认证及审计,并在全球范围内拥有众多生态合作伙伴。

点击“阅读原文”了解更多
