






分享嘉宾:张文涛 腾讯 Angel Graph 团队成员、北京大学博士生
编辑整理:吴祺尧
出品平台:DataFunTalk
导读:现实生活中,很多情况下数据都是以图的形式来展现的,例如社交网络、生物医药、材料领域等。图神经网络(GNN)相较于卷积神经网络(CNN)或者传统的机器学习方法,拥有利用邻居节点的特征来增强自身特征的能力。但是,工业场景下应用GNN存在着可扩展性和灵活性这两个问题。今天分享的主题是腾讯Angel Graph最新的工作:图注意力多层感知器,旨在解决上述两个问题。
今天的介绍会围绕下面六点展开:
图注意力多层感知器的提出动机
相关工作
NDLS
GAMLP
实验结果
总结
首先和大家分享下提出图注意力多层感知器的动机。
1. GNN的低可扩展性

我们在训练大规模图数据的时候,若使用单机训练则会遇到高内存占用,以及高耗时的问题。比如当网络数据有十几亿节点时,使用单机去训练传统GNN完全不能满足性能要求。所以我们一般会使用分布式训练。
但是在分布式场景下GNN的训练又会面临严重的通信开销问题。例如我们在Reddit数据集用分布式训练的方法训练两层的GraphSage,在这个过程中计算系统的吞吐量来观察分布式训练带来的计算加速增益。我们的实验环境是一台机器两个GPU,每个GPU就是一个worker节点。从实验结果图中我们可以观察到,随着worker节点的数量增加,计算加速增益距离理论上理想的加速效果有很大的差距,而究其原因正是巨大的通信开销。
2. GNN的低灵活性
GNN的另一个问题是低灵活性。
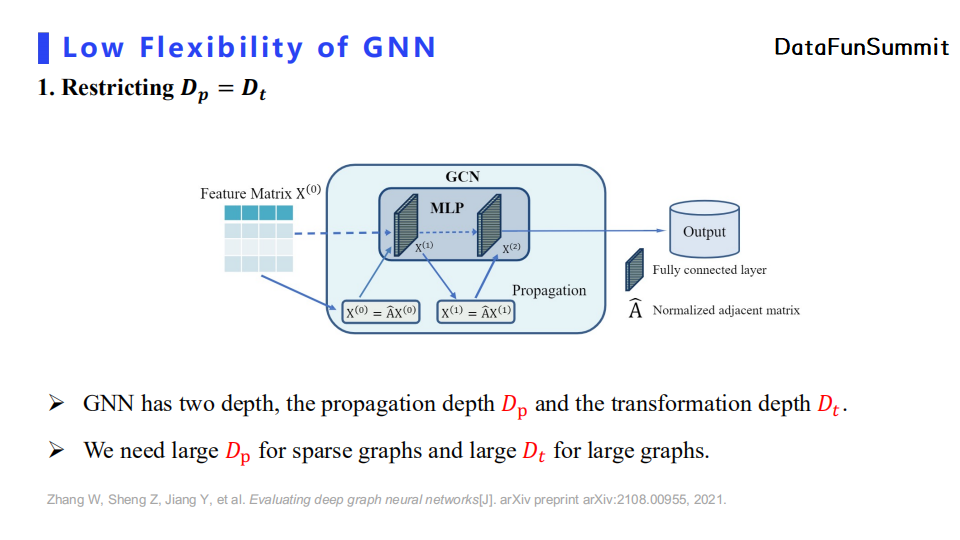
首先,它强制约束了MLP非线性变换深度等于消息传播深度。拿GCN举例来说,GCN的每一层都包含一次消息传递与一层非线性变换,那么GCN做的消息传递的次数就恒等于非线性变换的次数。我们分析了目前GNN无法堆叠较深层次的原因。传统观点认为模型深度较深时会产生过平滑现象,而我们认为这个原因被过分夸大了。我们测试了多个深层GNN网络结构,经过分析后认为模型性能不佳的更多原因在于模型的退化问题。例如,如果我们把消息传播的过程全部去除,那么这时GCN便退化为MLP。我们在大多数数据集上发现四层的MLP就已经很难训练了,所以我们可以进一步得出GCN无法使用较深的网络的本质原因。此外,我们也探究了什么时候GNN需要大的消息传播深度以及MLP变换深度。在节点数量比较多的稀疏图的情况下,GNN需要较大的消息传播深度以及较小的MLP变换深度,而这时便于传统GCN限制两个深度相等的要求产生了矛盾。具体的实验结果可以去查看我们在arXiv上的工作。
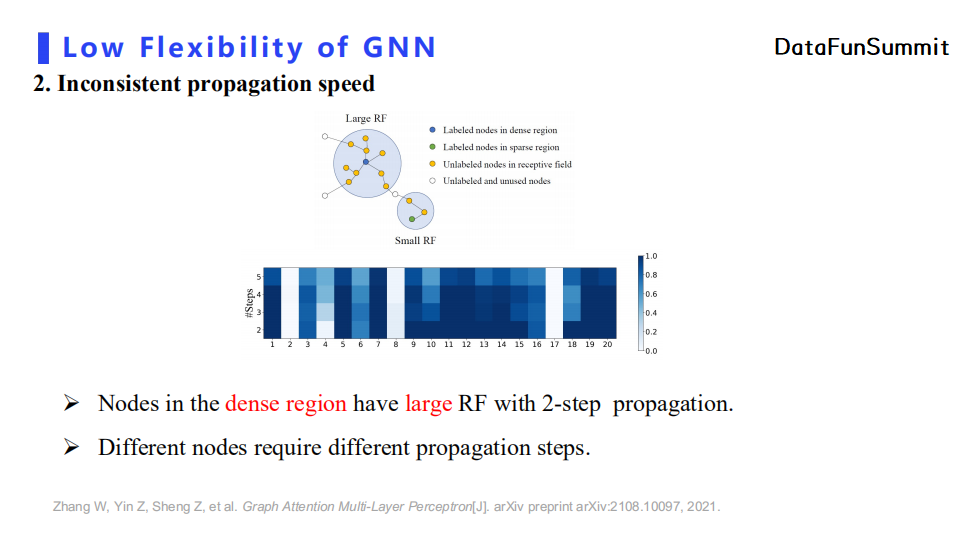
其次,GNN中节点的消息传播速度存在不一致性。具体来说,我们将感受域(RF)定义为节点与其消息传播后能影响到的节点的集合,那么若一个节点处于连接比较稠密的区域则两步消息传播后其RF就很大,即消息传播速度较快。从上图可以看出,蓝色点与绿色点虽然都是通过两层消息传播层,但是蓝点明显聚合了更多邻居节点的信息。
现实中,我们的数据质量是非常差的;数据标签的收集是比较困难的,很多场景中的数据是没有标签的;数据是分散的,这也是最重要的一点,每家应用的数据不一样,比如腾讯用的是社交属性数据,阿里用的是电商交易数据,微众用的是信用数据,都是分散来应用的。现实中,如何进行跨组织间的数据合作,会有很大的挑战。

首先,我们的目的之一是希望GNN能够有高可扩展性。达到这一目标的传统做法是采样以及模型解耦。采样分为三个层次:图级别采样、层级别采样、节点级别采样。而模型解耦的典型工作有:SGC、SIGN、GBP、S2GC。我们的工作属于模型解耦的类型,因为这种做法可以使模型即可扩展又保持高效。
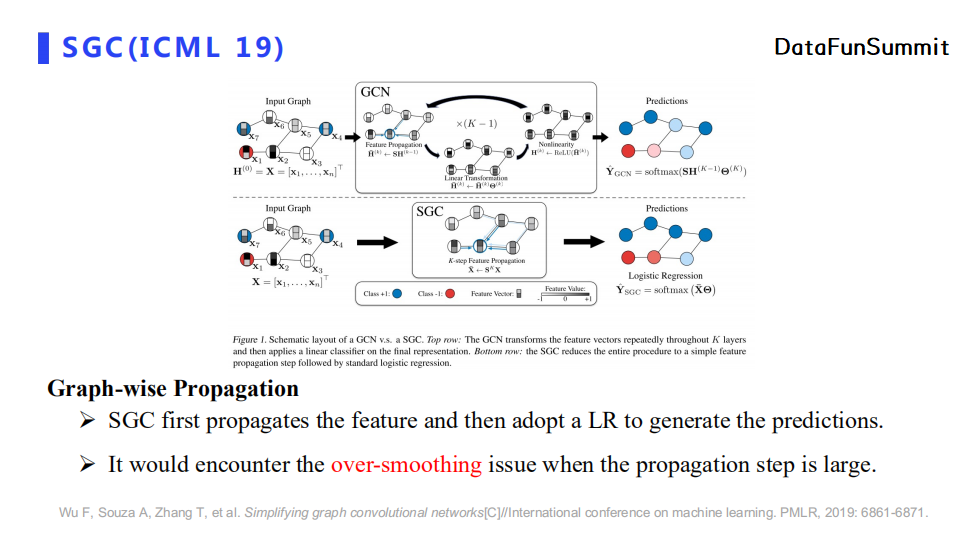
SGC采用了图层次的消息传递。它设置了较深的消息传播深度,即使得图中每个节点都可以聚合多跳的邻居节点特征,最后使用一个简单逻辑回归模型进行分类。但是SGC仅仅使用了最后一跳的信息,并没有充分利用不同跳的节点特征。此外,当消息传播深度较深时,SGC会出现过平滑问题。

SIGN解决了不同跳的信息没有充分利用的问题,它将不同跳的特征做了拼接操作,并将其输入至一个简单的MLP。相较于SGC,SIGN提供了更多的传播算子(diffusion operator),比如PageRank或者三角计数。但是,SIGN的缺点在于它并没有注意到不同节点所需要的传播深度不同的问题。如果跳数K取得非常大,那么后续拼接的特征都是过平滑特征,也就引入了很多噪声信息,最终导致模型性能不佳。
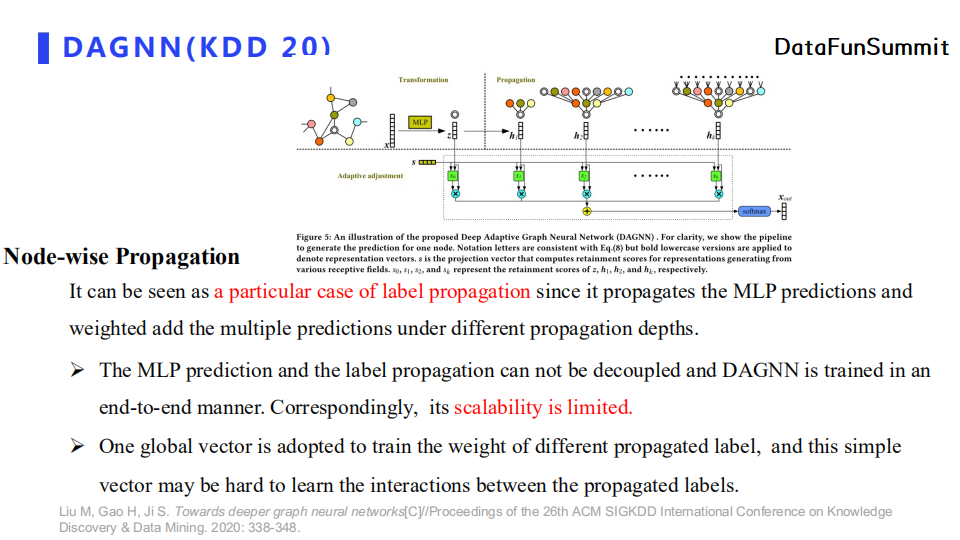
DAGNN和我们的工作比较相似,都属于节点层面的消息传递范式。它首先对每个节点的特征使用MLP进行映射,得到每个节点的伪标签值。之后,DAGNN会使用node-adaptive的消息传递,使得每个节点学习聚合邻居节点特征时的权重值。但是DAGNN在消息传播之前使用MLP,这导致我们需要得到训练后生成的节点embedding来做消息传递。而如果我们在处理超大规模图中使用了分布式训练方法,我们需要在消息传递之前拉取其他worker节点上存储的节点embedding,从而产生大量的通信开销。简单来说,DAGNN训练了多少个epoch,我们就需要拉取多少次节点embedding。此外,我们认为DAGNN在学习自适应聚合权重时仅仅使用了一个门机制,其表达能力是有所不足的。
下面介绍一下我们在今年NeurIPS的工作:NDLS。

当我们使用归一化邻接矩阵将节点特征传递无限次之后,等价的邻接矩阵第i行第j列元素仅与节点i与节点j的度数以及图中节点与边的数量相关。上图可以直观地看出节点传播深度过深后导致的过平滑问题。

我们从RF的角度来解释消息传播速率不一致的问题。如上图所示,图中左侧红色节点与右侧红色节点相比,同样经历两条的消息传播,其传播速度更快,对应的RF扩张速率也更快。我们在Cora数据集上对稠密连接区域和稀疏连接区域做了RF的对比实验,结果也表明稠密区域的RF扩张速率更快。

这就带来了under-smoothing以及over-smoothing这两个问题。如果像目前主流的方法,采用两层或者三层的GNN来解决over-smoothing问题,那么节点之间长期依赖关系就无法捕捉到。这个问题在图中节点特征较少的情况下非常常见,比如在推荐系统场景下新用户冷启动问题(节点特征较少,边的数量较少)。而解决这个问题的做法是使用较大的消息传播深度来增强图表达能力。以上即为under-smoothing问题。另一方面,over-smoothing问题,即无论节点处于稀疏连接区域或者稠密连接区域,节点在聚合过多跳的特征之后没有区分度。

NDLS中提出的解决方法是使用一个依赖于节点的控制平滑度的方式。我们认为SGC效果较好的原因来源于特征传递而非MLP变换。基于这一思想,我们定义了Local-Smoothing Iteration(LSI)。我们把节点特征传递无限次,即使用上图的公式计算出一个稳态特征。之后我们使用邻接矩阵对节点特征传递K次,并对输出的特征矩阵每一行(即每个节点的特征)与稳态特征的每一行计算距离。大多数节点随着K增大,其对应的距离会逐渐变小,即距离稳态越接近。对节点i,当这个距离小于一定阈值时我们就设定该节点最佳的传播深度为对应的K值。
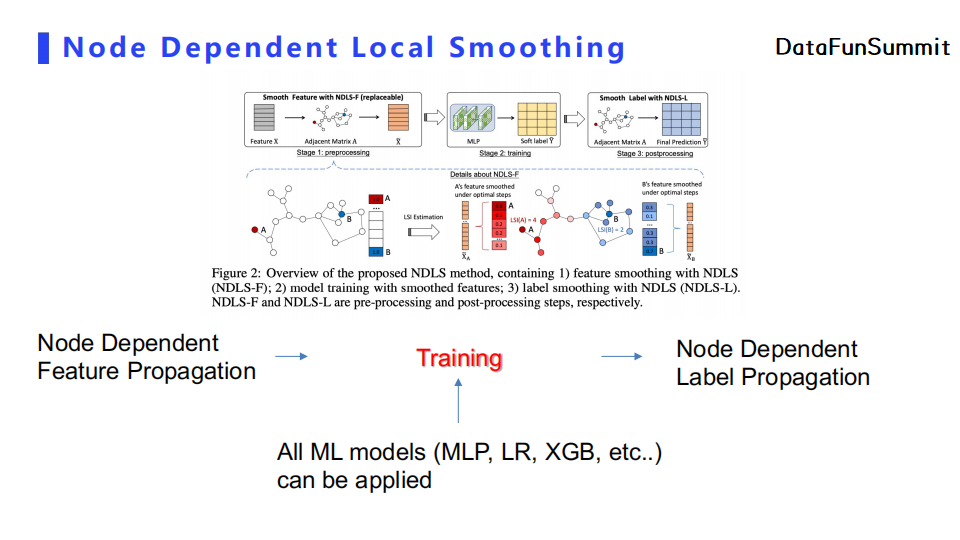
NDLS的框架由Node Dependent的特征传播,特征训练(可以使用MLP等任意机器学习模型)以及Node Dependent的标签传播组成。上图给出了一个直观的解释。例如A节点其传播深度为4,而B节点其传播深度为2。最后,在节点传播K跳之后,我们可以把之前所有K跳的特征做一个平均。

从实验结果可以看出MLP在加入Node Dependent特征平滑(FS)以及Node Dependent标签平滑(LS)后都可以取得性能提升。此外,LS可以作为一个插件直接使用到现有模型中来提升它们的性能。最后,NDLS在取得高精度的情况下可以保持较好的计算效率。
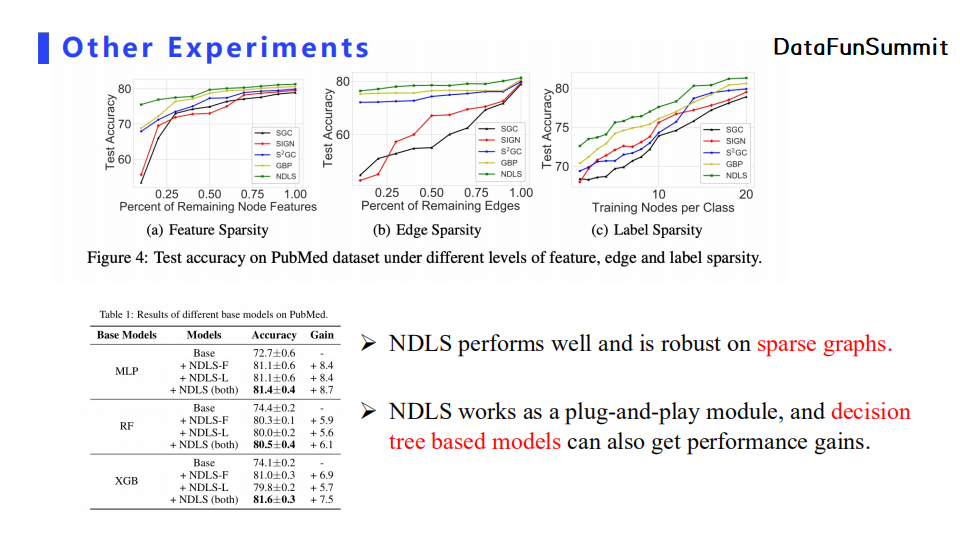
我们对图数据进行采样得到一些稀疏图,并在稀疏图中进行了对比实验。实验结果表明模型使用NDLS后,在稀疏图中相较于基线模型都得到了性能提升。

我们的工作中也包含了理论分析。具体地,我们想要知道什么因素可以影响LSI的效果。LSI主要以图的边数量、节点数量以及图的稀疏性呈正相关关系,而和节点度数呈负相关关系。从上图理论3.2也可以看出,如果图中一个节点的邻居节点的度数很大,那么它也会有一个较小的LSI;而且相邻的节点LSI也相近。上图中右侧可视化展示表明越靠近稠密区域的节点其LSI也越小。

总结来说,NDLS的优点是可扩展性以及灵活性。
可扩展性指的是它可以在单机处理超大规模的图,其消耗的内存比较少,同时在分布式场景下由于不存在额外的通信开销,只需要一次特征预处理或者标签预处理,剩下的工作就仅仅是训练一个普通的独立同分布模型即可。
NDLS的灵活性体现在它可以与任意模型搭配使用。
但是,NDLS有两个局限。
首先,它与下游任务是解耦的,并没有端对端的训练一个图表达。这就导致了得到的图表达仅仅针对通用的任务,但是具体到下游任务其性能不一定很好。
其次,简单的将多跳的特征直接进行均值化操作可能不是一个最佳选择。一个更好的方法应该是使用自适应的聚合。
下面要介绍的GAMLP不仅保留了NDLS高可扩展性和灵活性,还解决了上述两个问题。
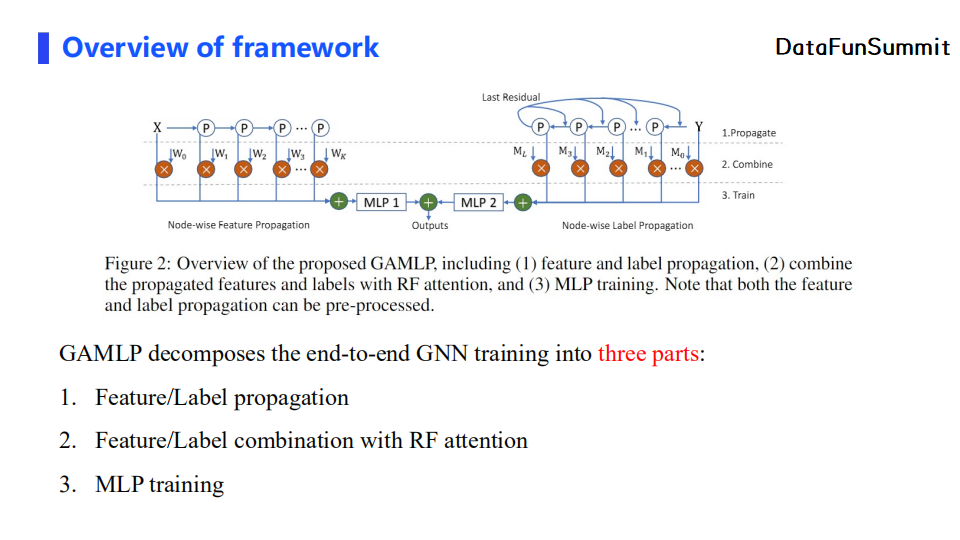
先从全局层面介绍GAMLP。首先,GAMLP分别做了节点自适应的特征传播与标签传播。之后,对传播后得到的特征和标签做加权求和。最后,特征会经过MLP进行非线性变换,我们也会对MLP进行训练。下面,我会对上述三个部分分块进行讲解。
1. 传播(Propagation)

我们首先需要进行node-wise的特征传播。和SGC类似,节点可以得到K跳内所有其他节点的特征信息。特征聚合使用的是加权求和的形式,其权重矩阵Wk是一个对角矩阵,矩阵中的第i行第i列的元素值代表节点i在K跳传播后的特征的重要性权重。

类似地,我们还会进行node-wise的标签传播。但是值得注意的是,如果我们直接像node-wise特征传播一样直接计算加权融合特征,由于在跳数l较小时传播标签值与原始标签值相近,则简单加权求和会有标签泄漏的问题,导致学习的权重值偏向较小跳数的传播特征。针对这个潜在的问题,我们采用了Last Residual Connection的方法。具体地,第l跳的传播标签特征会加入最后一跳的传播特征,其加权系数与当前跳数有关,且它会随着跳数的增大而减小(使用cos函数)。
2. 特征聚合(Combine)
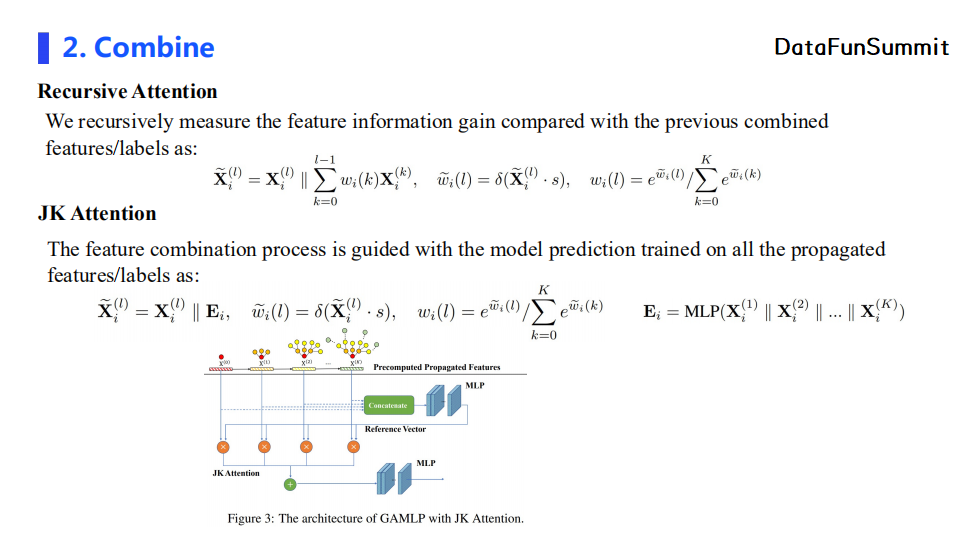
我们提出了两种attention机制:Recursive Attention和JK Attention。前者在计算第l层特征的重要性时拼接了之前所有层的加权特征。这样计算得到的权重值的物理意义为:当前层特征有多少比例是之前所有层所不包含的信息。JK Attention则模仿了JK Net的设计,将每个节点不同层的特征拼接并经过一个MLP进行变换,并将输出特征作为一个reference来衡量当前层的节点特征的重要性。JK Attention得到的权重值的物理意义为:当前层的特征信息相较于所有层的特征信息,其信息量较大的特征占比有多少。
3. 模型训练(Training)

模型中的MLP部分有两个分支,一部分用于对节点自适应传播特征进行变换,另一部分则对节点自适应传播标签进行变换。最终的输出特征通过β参数进行加权求和,我们可以通过调节β值来控制两者的重要性。如果我们的输入图拥有较好的节点特征,但其标签质量较差,那么我们可以减小β,使得特征更加关注于节点传播特征。模型的目标函数使用交叉熵损失函数。
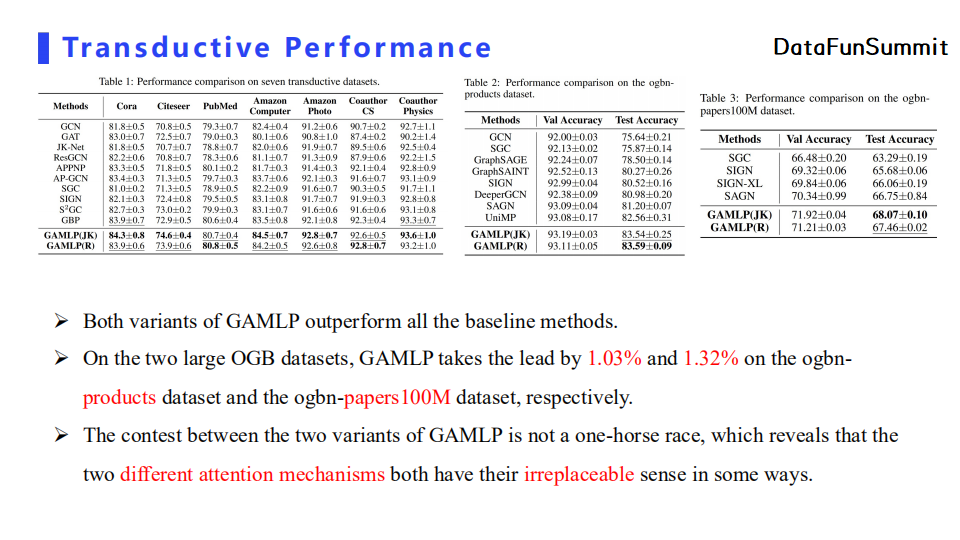
首先在直推式(transductive)学习的设定下,实验结果表明两种GAMLP相较于所有基线方法在所有数据七个数据集上都有一定的性能提升。特别地,在两个大型OGB的数据集上,GAMLP的表现都超过了基线方法1个点以上。另一方面,两种attention机制的特征融合方法都是不可被直接替代的,它们各自都有自己的优势。
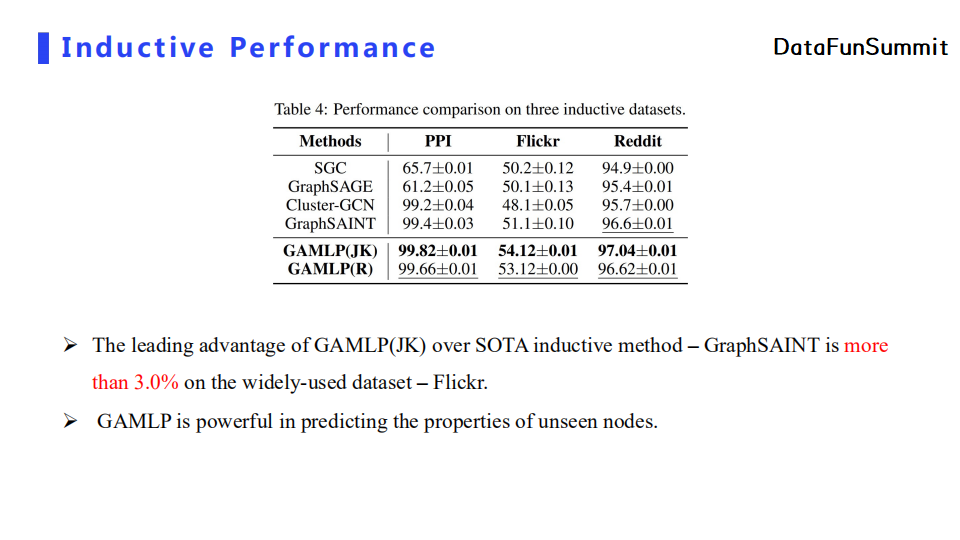
其次,在归纳式(inductive)学习的设定下,GAMLP比SOTA的方法有超过三个点的性能提升,证明了GAMLP可以有效地对未知节点的属性进行预测。
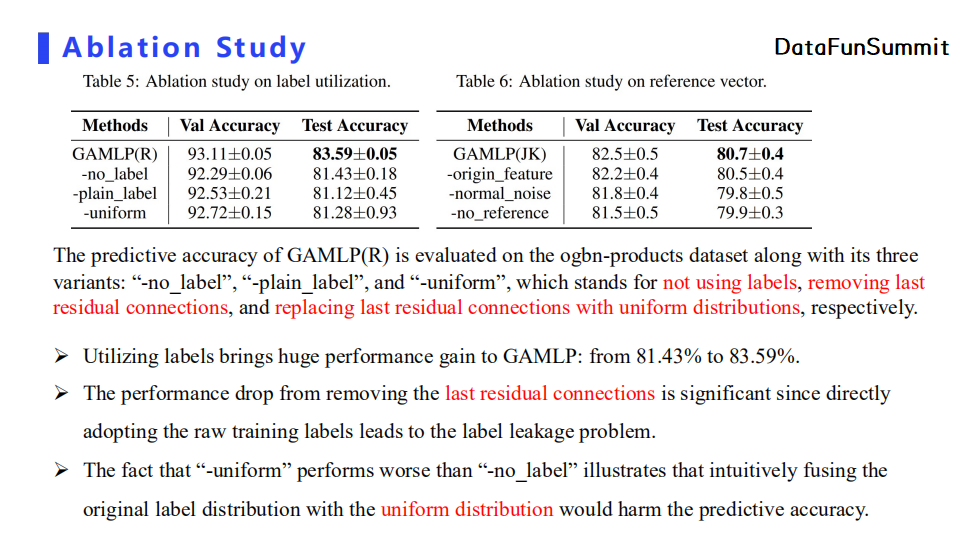
针对对比实验部分,我们首先证明了last residual connection的有效性。我们在实验中分别对比了不使用传播标签、直接去除last residual connection(即直接使用自适应标签传播的标签值),以及使用均匀分布的标签值替换last residual connection的性能。实验结果表明,不使用传播标签比直接去除last residual connection模块直接使用传播标签的模型以及使用均匀分布的标签值进行替换后的模型的性能更好。这证明了标签泄漏问题会负面影响模型的预测能力。而显然加入last residual connection后模型效果最佳,证明了其在改善标签泄漏问题的重要性。
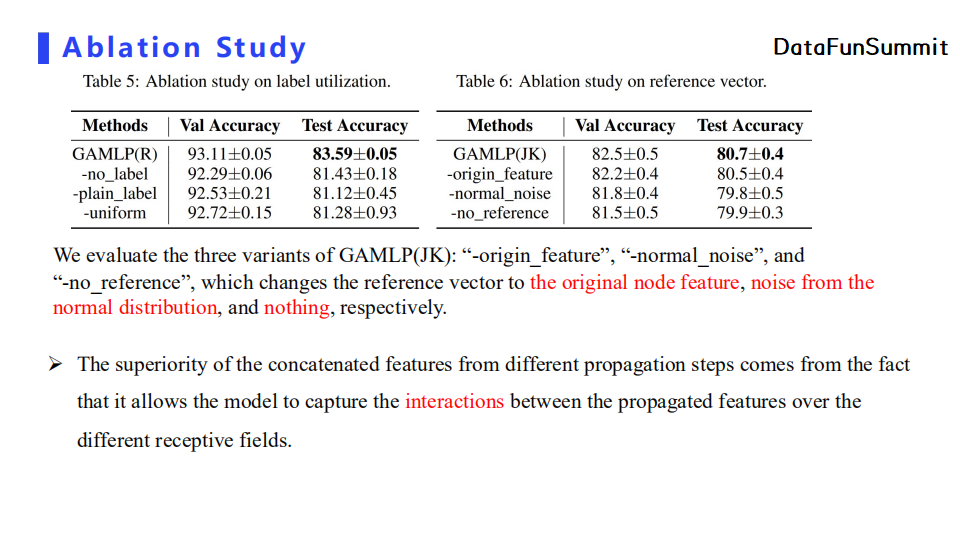
我们也对JK Attention进行了对比实验,将attention机制中衡量特征重要性的参考向量分别替换为原节点特征、正态分布的噪声特征以及不添加任何参考特征。实验结果表明后面几种参考向量相比于JK Attention机制,模型性能都有不同程度的下降。
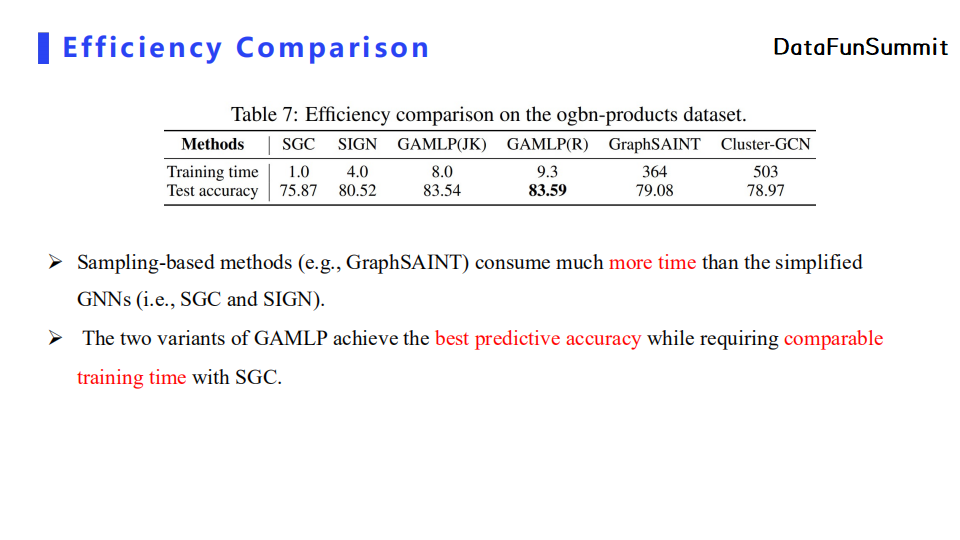
接下来,针对模型效率我们也进行了对比实验。GAMLP虽然比起SGC和SIGN在单机上要慢一些,但是我们的预测精度比较好,而且训练时间也不会相差太多。相对地,采用图采样的模型比采用解耦思想的模型训练时间要多出不止一个数量级。
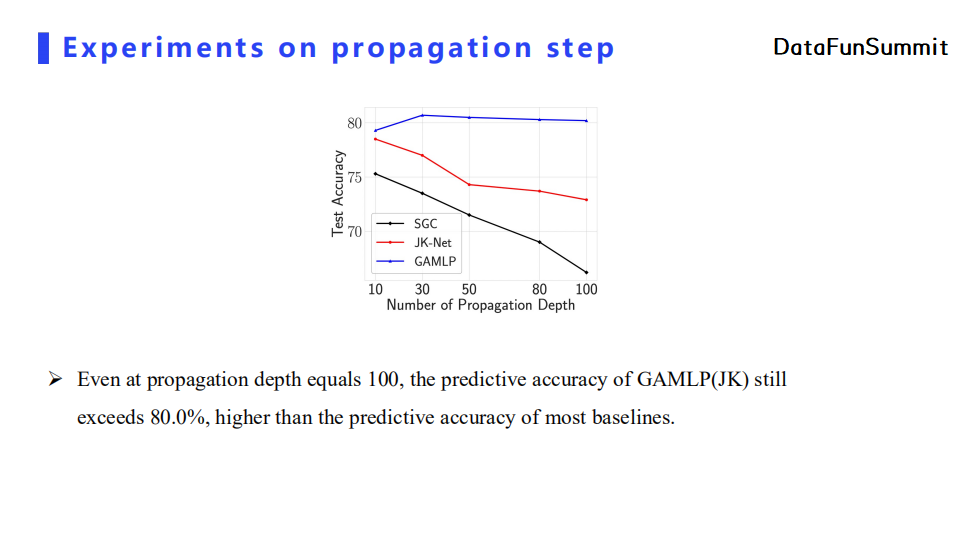
我们对传播深度也进行了对比。当传播深度为100时,GAMLP的分类精度依然可以达到80%以上,远超其他基线模型。这在实际应用中会有很大的好处,因为GAMLP不需要针对不同类型的图对模型深度进行调参。
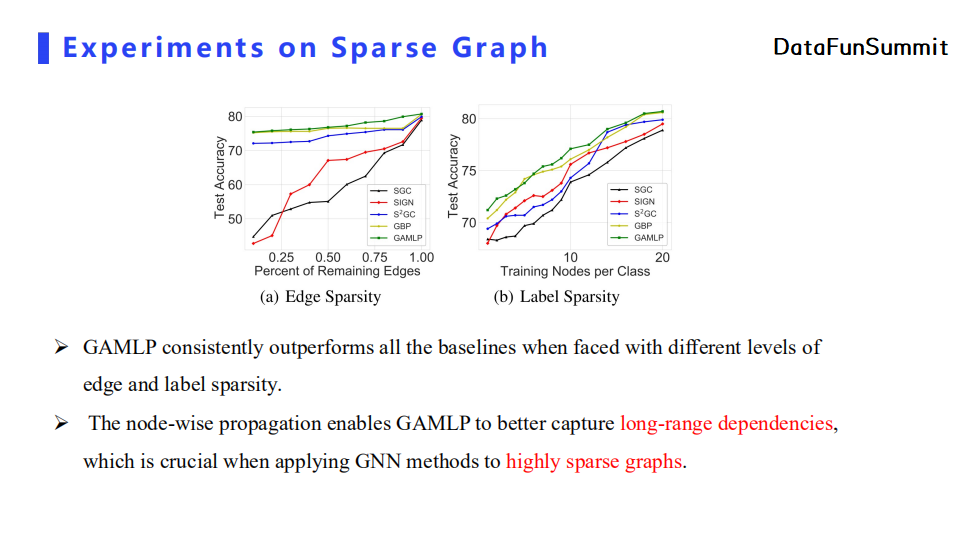
最后,GAMLP在各类型的稀疏图上的性能也比其他基线模型更优,即GAMLP无论在边数比较稀少或者标签值比较缺乏的情况下都能得到较优的分类精度,证明了它可以利用长距离节点特征来增强图表达。
GAMLP在深度、可扩展性,以及计算效率上具有如下优势:
首先,它可以达到很深的传播深度,并保证不出现过平滑现象;
第二,GAMLP无论在单机场景下还是分布式场景下都可以获得较好的加速效果;
第三,GAMLP计算效率比较高,因为它只需要一次消息传播预处理即可,而模型训练仅仅针对后面的MLP部分,所以训练速度较快。
GAMLP的应用场景有两方面:
一方面,我们可以将其使用在稀疏图上,因为GAMLP的传播深度可以设定得很深,使得其可以在稀疏图上获得更好的节点表达;
此外,由于GAMLP的高效性和高可扩展性,它可以处理超大规模图(包含十亿甚至上百亿节点的图)。
Q:GAMLP消息传播中节点特征和标签是分开处理的,这一点是如何想到的?
A:节点特征和标签一起做消息传播这一想法其实早已在很多工作中体现,比如百度的UniMP。
Q:GAMLP具体能应用在哪些场景?
A:GAMLP没有固定的应用场景,因为它提出的目的是为了解决稀疏图与大规模图的训练问题。可能在推荐场景下GAMLP会比较实用。比如在推荐场景下,我们所拥有的节点特征在冷启动的背景下是十分稀少的,对应了稀疏图场景。另外,推荐系统中很多时候拥有海量的用户以及商品节点。由于单机难以处理这种大规模图,我们在使用分布式训练框架时,GAMLP可以显著减低通讯开销。
Q:GAMLP能够做深是不是因为每个节点可以个性化地选择传播步数,而不是所有节点通过采样来传播相同的步数?
A:是的。比如SGC,比如你设定传播深度为10,那么所有节点都需要传播10层。但是当一个节点处于比较稠密的区域时,它经过很少的传播深度就基本上可以覆盖全图的节点,那么这就导致其节点embedding与全图很多其他节点的embedding十分相似,进而导致下游任务效果不佳。而GAMLP的解决方法是使用node adaptive的消息传播机制,过平滑的节点特征会自动降低权重。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

电子书下载


关于我们:
🧐分享、点赞、在看,给个3连击呗!👇
