




HASH ON 子句
使用 CREATE INDEX 语句的 HASH ON 子句指定森林树索引的子树(存储区)的数目及其列。
HASH ON 子句

元素 | 描述 | 限制 | 语法 |
column | 您使用 HASH ON 子句创建森林树索引的列或列组的名称 | 该列表必须是在 CREATE INDEX 语句中使用的索引列的前缀列表。 | 标识符 |
number | 要创建森林树索引所需的子树(存储区)数 | 森林树索引的存储区数必须在 2 到每个 dbspace 可用索引页数之间。 | 整数文字 |
用法
森林树索引是拆离的索引。它们不能是连接的索引。
您可以在基本数据类型的列上创建森林树索引。
您不能:
l 在具有复杂数据类型的列、UDT 、或函数列上创建森林树索引。
l 当创建森林树索引时,使用 CREATE INDEX 语句的 FILLFACTOR 选项。因为索引是从顶向底建立。
l 创建集群的森林树索引。
l 在森林树索引上运行 ALTER INDEX 语句。
l 在使用聚合(包括最小和最大范围值)的查询中使用森林树索引。
l 直接在森林树索引的 HASH ON 列上执行范围扫描。
然而,您可以在不列在 HASH ON 列列表的列上执行范围扫描。对于在 HASH ON 列列表列出的列的范围扫描,您必须创建包含此范围扫描的适当列表的附加 B-tree 索引。该附加 B-tree 索引可能具有与森林树索引相同的列列表,加或减一列。
l 可对 OR 索引路径使用森林树索引。数据库服务器不会在索引列上具有 OR 为此的查询中使用森林树索引。
当您创建森林树索引时,选择足够的列以创建唯一值。
提示: 一般情况下,要选择的列取决于每一列的副本数。例如,如果第一列包含很少量的副本,如果前两列不包含大量副本,则前两列满足散列。如果前两列包含大量的副本,则您还需要选择第三个列。
子树的数目取决于您创建的索引的目的。如果您的目的是:
l 为减少争用,最初创建每个 CPU VP 2 个子树的森林树索引。您可能需要更多子树,这取决于表中的行数和存在多少副本。
l 要减少 B-tree 中层级数:
1. 运行 oncheck -pT 命令。
2. 在此输出中,找到每一层级的节点数。
3. 决定需要多少个子树来实现索引中每个数的期望深度。
例如,假设一个索引每页均有 100 个键,该索引有 1M 个键,则该树则看起来像这样:
· Level 1 (root) 100 keys
· Level 2 10K keys
· Level 3 1M keys
要将 3-level tree 减少到 100 2-level tree, 该索引大概需要 100 个子树。要将 3-level tree 减少到 10K 1-level tree ,该索引大概需要 10K 个子树。
如果使用了太多的或太少的子树,则森林树页面可以比传统的 B-tree 页面更稀疏。当页面稀疏时,更多页占据缓冲池,这将导致其它表的缓存变得更少。
示例
以下命令创建了名为 idx1 的森林树索引,它在 c1 列上有 100 个子树:
CREATE INDEX idx1 ON tab1(c1) HASH ON (c1) with 100 buckets;
以下命令创建了名为 idx2 的森林树索引。在此命令中,该语句的 HASH ON 部分的前缀列表是 c1 和 c2,它是在该语句的 CREATE INDEX 部分中使用的 c1 、c2 和 c3 列的前缀列表:
CREATE INDEX idx2 on tab2(c1, c2, c3) HASH ON (c1, c2) with 10 buckets;
以下命令在列 c1 和列 c2 上创建了一个等式查找的森林树索引:
CREATE INDEX idx3 on tab3(c1, c2) HASH ON (c1, c2) with 100 buckets;
以下命令创建了类似于先前森林树索引的 B-tree 索引。该索引用于列 c1 和列 c2 的范围扫描:
CREATE INDEX idx4 on tab4(c1, c2, c3);
FILLFACTOR 选项
当您想要创建压缩索引或为以后索引的扩展提供信息时,可使用 FILLFACTOR 选项指定索引页的充满程度。
FILLFACTOR 选项只在以下情况中有效:
· 当在一个含有超过 5,000 行并使用超过 100 个表页的表上构建索引时
· 挡在分片表上创建索引时
· 当在非分片表上创建分片索引时
不能在森林树索引上使用 FILLFACTOR 选项。
FILLFACTOR Option

元素 | 描述 | 限制 | 语法 |
percent | 当创建索引时每个被索引数据填充的索引页的百分比。缺省值为 90 。 | 1 ≤ percent ≤100 | 精确数值 |
当创建索引时,数据库服务器最初仅填充 FILLFACTOR 值指定的节点百分比。
FILLFACTOR 还能在 ONCONFIG 文件中作为参数来设置。CREATE INDEX 语句上的 FILLFACTOR 子句覆盖 ONCONFIG 文件中的设定。有关 ONCONFIG 文件和您能使用的参数的更多信息,请参阅 GBase 8s 管理员指南。
提供低百分比值
如果您提供一个低百分比值,类似 50 ,您允许索引中的增长。索引的节点最初填充到一定的百分比并为插入包含空间。可用空间的数量取决于每页中键的数量以及百分值。
例如,FILLFACTOR 值为 50%,页面将半满并能适应大小的加倍。低百分比值能导致更快的插入并能用于期望增长的索引。
提高百分比值
如果您提高百分比值,例如 99 ,则索引将是压缩的,并且任何新索引的插入将呆滞分割节点。密度的最大值是100% 。具有 100% 的 FILLFACTOR 值时,索引没有空间可用于增长;任何索引的添加都将导致分割节点。
99% 的 FILLFACTOR 值允许每个节点至少一个插入的空间。高百分比值可能产生更快的查询,并适合与您不希望增长的索引或大部分只读索引。
存储选项
存储选项指定索引的分布方案。您可使用 IN 子句来为整个索引指定存储空间,或者可使用 FRAGMENT BY 子句来在多个存储空间上分片索引。
存储选项
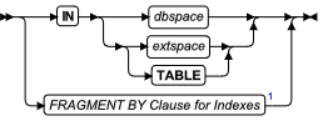
元素 | 描述 | 限制 | 语法 |
dbspace | 存储索引的 dbspace | 必须存在 | 标识符 |
extspace | 由 onspaces 命令分配到数据库服务器外的存储区域的名称 | 必须存在 | 请参阅您的存取方法的文档。 |
如果您指定任何存储选项(除了 IN TABLE),您将创建一个拆离的索引。拆离索引是使用特定的分布模式创建的索引。即使为索引指定的分布模式与为表指定的相同,索引仍被认为要拆离。如果表的分布方案更改了,所有拆离的索引还将继续使用 Storage Option 子句指定的分布方案。
如果您不包含 Storage Option 子句,则缺省情况下在同一 dbspace 建立连接索引,并将其作为对应表的分片。然而,如果启用自动定位,则缺省情况下单个分片中循环表上建立的索引被拆离,并将其放置在服务器选择的 dbspace 中。通过设置 AUTOLOCATE 配置参数或者将会话环境变量选项设置为正整数来启用自动定位。
索引的 COMPRESSED 选项
如果索引拥有 2000 或更多的键,则可使用 CREATE INDEX 语句的 COMPRESSED 关键字压缩 B-tree 索引。
您可以在分片表或未分片表上创建压缩的索引。
您不能创建的压缩的索引是集群索引。然而,您可以通过运行带 index compress 参数的 SQL 管理 API task() 或 admin() 函数压缩现有的集群索引。
要被压缩,索引中的分片或索引必须具有至少 2000 个键。如果您在创建不具有足够多的键的索引时使用 COMPRESSED 选项,则数据库服务器在创建该索引时不会压缩该索引或分片。即使向该索引添加键,其仍然保持未压缩状态。如果您想要压缩该索引,则运行带 index compress 参数的 SQL 管理 API task() 或 admin() 函数。
如果表没有足够的数据来提供足够大的索引键样本,则数据库服务器不会压缩该索引或分片。即使将最小数量的新键添加到现有未压缩的索引中,数据库服务器仍不会压缩该索引。 然而,压缩索引后,数据库服务器压缩并插入任何新的键到该索引中。
以下示例在 customer 表的 address 列创建了一个名为 cust3_ix 的压缩的索引:
CREATE INDEX cust3_ix ON customer (address) COMPRESSED
EXTENT SIZE 32 NEXT SIZE 32;
以下示例创建了一个唯一的压缩的索引:
CREATE UNIQUE INDEX cust3_ix ON customer (address) COMPRESSED ;
