一、
功能概述——查询重写
定义:
查询重写就是把用户输入的SQL语句转换为更高效的等价SQL。
原则:
查询重写遵循两个基本原则。
(1) 等价性:原语句和重写后的语句,输出结果相同。
(2) 高效性:重写后的语句,比原语句在执行时间和资源使用上更高效。
方式:
查询重写优化既可以基于关系代数的理论进行优化,例如谓词下推、子查询优化等,也可以基于启发式规则进行优化,例如Outer Join消除、表连接消除等。另外还有一些基于特定的优化规则和实际执行过程相关的优化,例如在并行扫描的基础上,可以考虑对Aggregation算子分阶段进行,通过将Aggregation划分成不同的阶段,可以提升执行的效率。
代价:
查询重写不只是基于经验的查询重写,还可以是基于代价的查询重写。
二、
源代码文件

ü 目录:
src/gausskernel/optimizer/prep

ü preptlist:
预处理语法树的目标列表。
对于INSERT和UPDATE语句,目标列表中包含的对于每个目标关系的属性的入口必须是正确顺序的。通俗的来说就是INSERT语句中插入数据的顺序可能和关系表中的属性顺序不一致,比如表中属性的顺序是A
B C,而插入语句是按照 B C A这样插入数据的。对于所有语句,我们有时需要为了返回的属性和EvalPlanQual需要的行号信息加入多余的目标列表入口。举例来说,有时我们的查询结果不一定是关系表中存在的列,而是类似A+B这样的新列(A和B都是原关系表中的属性)。EvalPlanQual是一个函数,主要用于检查被修改的行,在read commited隔离级别下是否有必要重新去读。
ü preprownum:
把rownum改写为limit。
{select * from
table_name where rownum < 5;}
{select * from
table_name limit 4;}
ü prepqual:
预处理条件语句。确保语法树是否扁平(flatness),如果不扁平的话需要让这个语法树变平。简单的来说就是将编译阶段被当作二元运算符写入树中的逻辑符(AND,OR)在树中变为多元运算符(A
AND (B AND C) 变成 A AND B AND C)。现在这项功能主要交给eval_const_expressions这个函数,因为这个函数本来就需要遍历表达式树,可以在遍历的过程中同时将树扁平化,这样就可以免去多次遍历的麻烦。
ü prepnonjointree:
预处理子序列和不需要join的操作。
ü prepjointree:
预处理子序列和需要join的操作。
ü prepunion:
预处理集合运算。但类似UNION ALL的直接附加关系不在这里处理。
架构:
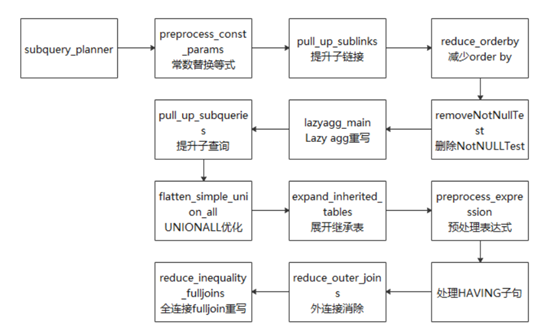
(1) 提升子查询:子查询出现在RangeTableEntry中,它存储的是一个子查询树,若子查询不被提升,则经过查询优化之后形成一个子执行计划,上层执行计划和子查询计划做嵌套循环得到最终结果。在该过程中,查询优化模块对这个子查询所能做的优化选择较少。若该子查询被提升,转换成与上层的join,由查询优化模块常数替换等式:由于常数引用速度更快,故将可以求值的变量求出来,并用求得的常数替换它,实现函数为preprocess_const_params。
(2) 子查询替换CTE:理论上CTE(common
table expression,通用表达式)与子查询性能相同,但对子查询可以进行进一步的提升重写优化,故尝试用子查询替换CTE,实现函数为substitute_ctes_with_subqueries。
(3)
multi count(distinct)替换为多条子查询:如果出现该类查询,则将多个count(distinct)查询分别替换为多条子查询,其中每条子查询中包含一个count(distinct)表达式,实现函数为convert_multi_count_distinct。
(4) 提升子链接:子链接出现在WHERE/ON等约束条件中,通常伴随着ANY/ALL/IN/EXISTS/SOME等谓词同时出现。虽然子链接从语句的逻辑层次上是清晰的,但是效率有高有低,比如相关子链接,其执行结果和父查询相关,即父查询的每一条元组都对应着子链接的重新求值,此情况下可通过提升子链接提高效率。在该部分数据库主要针对ANY和EXISTS两种类型的子链接尝试进行提升,提升为Semi Join或者Anti-SemiJoin,实现函数为pull_up_sublinks。
(5) 减少ORDER
BY:由于在父查询中可能需要对数据库的记录进行重新排序,故减少子查询中的ORDER BY语句以进行链接可提高效率,实现函数为reduce_orderby。
(6) 删除NotNullTest:即删除相关的非NULL Test以提高效率,实现函数为removeNotNullTest。
(7) Lazy
Agg重写:顾名思义,即“懒聚集”,目的在于减少聚集次数,实现函数为lazyagg_main。
(8) 对连接操作的优化做了很多工作,可能获得更好的执行计划,实现函数为pull_up_subqueries。
(9)
UNION ALL优化:对顶层的UNION ALL进行处理,目的是将UNION ALL这种集合操作的形式转换为AppendRelInfo的形式,实现函数为flatten_simple_union_all。
(10) 展开继承表:如果在查询语句执行的过程中使用了继承表,那么继承表是以父表的形式存在的,需要将父表展开成为多个继承表,实现函数为expand_inherited_tables。,实现函数为expand_inherited_tables。
(11)预处理表达式:该模块是对查询树中的表达式进行规范整理的过程,包括对链接产生的别名Var进行替换、对常量表达式求值、对约束条件进行拉平、为子链接生成执行计划等,实现函数为preprocess_expression。
(12) 处理HAVING子句:在Having子句中,有些约束条件是可以转变为过滤条件的(对应WHERE),这里对Having子句中的约束条件进行拆分,以提高效率。
(13) 外连接消除:目的在于将外连接转换为内连接,以简化查询优化过程,实现函数为reduce_outer_join函数。
(14) 全连接full
join重写:对全连接函数进行重写,以完善其功能。比如对于语句SELECT * FROM t1 FULL
JOIN t2 ON TRUE可以将其转换为: SELECT * FROM t1 LEFT JOIN t2
ON TRUE UNION ALL (SELECT * FROM t1 RIGHT ANTI FULL JOIN t2 ON TRUE),实现函数为reduce_inequality_fulljoins。
三、
函数解析
1.
reduce_orderby
由于在父查询中可能需要对数据库的记录进行重新排序,故减少子查询中的ORDER BY语句以进行链接可提高效率,实现函数为reduce_orderby。例如在如下SQL语句中子查询的ORDER BY就可以在实际运行时被删除:select * from (select *
from table_name order by column_name desc) 。
void reduce_orderby(Query* query, bool
reduce)
l
ORDER BY 语句用于根据指定的列对结果集进行排序。
l
减少子查询中的orderby,减少无效的orderby(UNION)。
l
入口为subquery_planner。query为待处理的查询树。reduce标志是否要减少orderby
1)
如果目前是update和insert命令,遍历query树,找到为select的子语句。
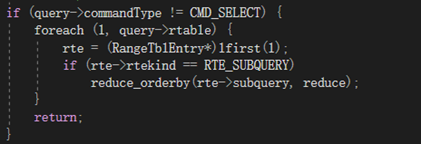
2)
递归查找子查询中的orderby,然后决定是否可以减少。

3)
如果有集合操作,需要递归找到orderby,并直接减少。
在如(SELECT * FROM t1 WHERE username LIKE 'l%' ORDER BY sroce
ASC)
UNION
(SELECT * FROM t1 WHERE username LIKE '%m%' ORDER BY score
ASC)的集合操作中order by没有效果。

其中RangeTblEntry 为 查询树节点中的表实体对象。
static void reduce_orderby_final(RangeTblEntry*
rte, bool reduce)
l
减少orderby语句的执行函数
1)
确定当前的表实体对象是子查询。当传入的reduce标志是正且此时子查询内存在排序语句,释放排序语句的节点,并置为空。

static void
reduce_orderby_recurse(Query* query, Node* jtnode, bool reduce)
l
递归检查join节点,并对表实体对象执行减少orderby操作。
1)
join节点为集合操作时,orderby可以减少,将标志置为true,继续递归。
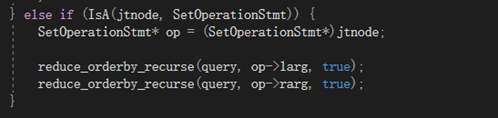
2)
join节点为join操作时,检查jointype,orderby可以减少,将标志置为true,继续递归。若jointype不是期望的任意一种类型,报错。
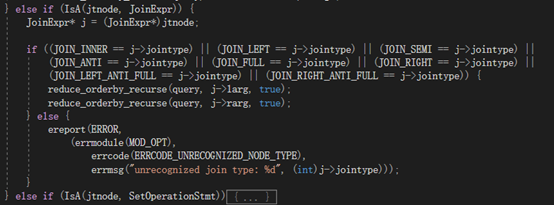
3)
当join节点为where...from...结构时,当from还有其他子树时(嵌套查询),可以减少orderby语句。
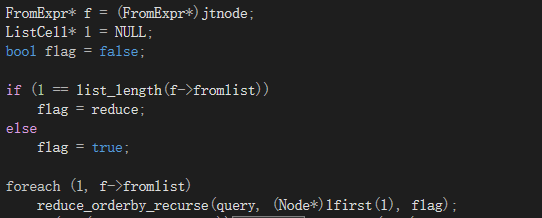
4)
注意如果存在rownum则不能减少orderby。
例如在如下这种情况中select * from
table_name where rownum < n union select * from (select * from table_name
order by column_name desc) where rownum < n; orderby不能被减少,故需要单独使用contain_rownum_walker函数检测检测这种情况。


5)
递归到rangetableentry时可以调用final函数执行减少操作。RangeTblRef是Query->jointree的叶子节点,所以是该函数递归结束的条件,调用final函数执行减少操作。

2.
reduce_outer_joins
l
目的在于将外连接转换为内连接,以简化查询优化过程。
例如,在如下语句中外连接可以被转换为内连接。
SELECT ... FROM a LEFT JOIN b ON (...) WHERE b.y = 42;
当join条件成立时,返回左表中的数据。如果左表中满足指定条件的某行数据在右表中出现过,则此行保留在结果集中。
当join条件不成立时,返回左表中的数据。如果左表中满足指定条件的某行数据没有在右表中出现过,则此行保留在结果集中。
l
当外连接上有一个严格的条件,限制在连接中可能为空的属性不能为空时,外连接可以被转化为内连接。
例如,在如下语句中外连接可以被转换为内连接。
SELECT
... FROM a LEFT JOIN b ON (a.x = b.y) WHERE b.y IS NULL;
l
可以将外连接转换为anti join。
l
因为RIGHT JOIN和LEFT JOIN的本质其实是一样的,故可以把把RIGHT JOIN翻转成LEFT JOIN,这样可以节省代码相同的代码。
l
为了识别严格条件语句,这个函数必须在预处理表达时之后执行。
reduce_outer_joins
为了避免检查不必要的条件语句,在当前节点下面没有外连接时停止搜索。将这个过程分为两个部分。第一部分,收集join语句两边的表的信息,并且确定是否存在外连接。第二部分,检查条件语句并且转换连接类型。
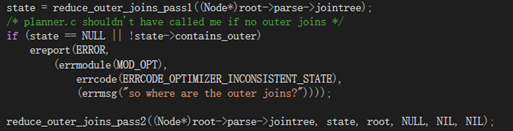
reduce_outer_joins_pass1
pass1返回一个描述jointree状态的节点。与其他函数类似,讨论join节点为RangeTblRef、FromExpr、JoinExpr的三种情况。
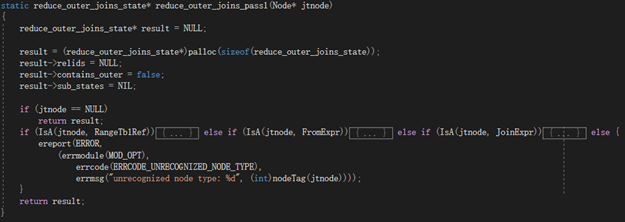
reduce_outer_joins_pass2
1)
参数nonnullable_vars、forced_null_vars为被条件语句要求必须为空和非空的属性列表。

2)
检查必须为非空/空的属性与在外连接中将要为空/非空的属性有没有重合,由此确定目标的转换连接类型。
3)
注意ANTI JOIN类型可以不用讨论,因为ANTI JOIN只有可能由提升子链接函数引入。上层的条件语句不会涉及到其两侧。
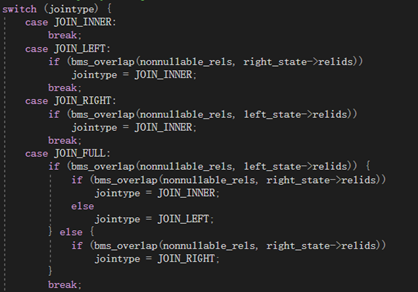
3.
pull_up_sublinks
l 目的在于提升子链接,是查询重写最基础及重要的函数之一。
l 子链接出现在WHERE/ON等约束条件中,通常伴随着ANY/ALL/IN/EXISTS/SOME等谓词同时出现。虽然子链接从语句的逻辑层次上是清晰的,但是效率有高有低,比如相关子链接,其执行结果和父查询相关,即父查询的每一条元组都对应着子链接的重新求值,此情况下可通过提升子链接提高效率。
l 在该部分数据库主要针对ANY和EXISTS两种类型的子链接尝试进行提升,提升为Semi Join或者Anti-SemiJoin,实现函数为pull_up_sublinks。
l 因为经过提升子链接处理的语句会变为Join语法,故需要在提升子链接之后进行减少Join的处理。
l openGauss数据库为不同的谓词设置了不同的SUBLINK类型。openGauss数据库为子链接定义了单独的结构体——SubLink结构体,其中主要描述了子链接的类型、子链接的操作符等信息。
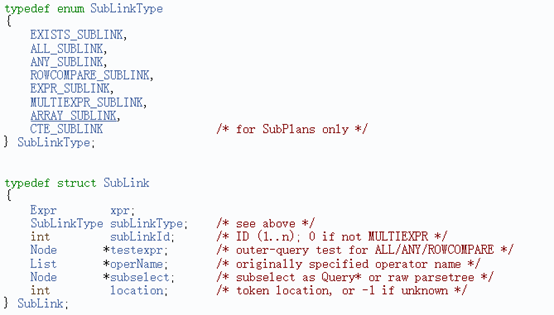
l
子链接提升的主要过程是在pull_up_sublinks函数中实现,pull_up_sublinks函数又调用pull_up_sublinks_jointree_recurse递归处理Query->jointree中的节点。
pull_up_sublinks_jointree_recurse
l
jnode分为三种类型:RangeTblRef、FromExpr、JoinExpr。针对这三种类别pull_up_sublinks_jointree_recurse函数分别进行了处理。
1)
RangeTblRef
RangeTblRef是Query->jointree的叶子节点,所以是该函数递归结束的条件,程序走到该分支,一般有两种情况。

当前语句是单表查询而且不存在连接操作,这种情况递归处理直到结束后,再去查看子链接是否满足其他提升条件。

查询语句存在连接关系,在对From->fromlist、JoinExpr->larg或者JoinExpr->rarg递归处理的过程中,当遍历到了RangeTblRef叶子节点时,需要把RangeTblRef节点的relids(表的集合)返回给上一层。主要用于判断该子链接是否能提升。

2)
FromExpr

递归遍历From->fromlist中的节点,之后对每个节点递归调用pull_up_sublinks_jointree_recurse函数,直到处理到叶子节点RangeTblRef才结束。

调用pull_up_sublinks_qual_recurse函数处理From->qual,对其中可能出现的ANY_SUBLINK或EXISTS_SUBLINK进行处理。

3)
JoinExpr

调用pull_up_sublinks_jointree_recurse函数递归处理JoinExpr->larg和JoinExpr->rarg,直到处理到叶子节点RangeTblRef才结束。另外还需要根据连接操作的类型区分子链接是否能够被提升。

调用pull_up_sublinks_qual_recurse函数处理JoinExpr->quals,对其中可能出现的ANY_SUBLINK或EXISTS_SUBLINK做处理。如果连接类型不同,pull_up_sublinks_qual_recurse函数的available_rels1参数的输入值是不同的。

pull_up_sublinks_qual_recurse函数除了对ANY_SUBLINK和EXISTS_SUBLINK做处理,还对OR子句和EXPR类型子链接做了查询重写优化。
四、
源代码学习感悟
l
学习源码前必要的准备工作
在学习源码之前首先应该回顾基本的SQL语法和数据库概念。以我学习的查询重写功能为例,如果对SQL语法不了解,那就很难理解很多函数的功能和设计。如果能事先理解哪些语法在什么条件下能够互相改写,那将会事半功倍。
l
好用的资料
因为openGauss是在开源数据库postgresql的基础上进行开发的,所以很多部分的代码和postgresql是完全一致的。
https://doxygen.postgresql.org/
postgresql的源码网站支持检索功能。在阅读源码的过程中,我经常遇到对其他文件中定义的结构或函数的调用。通过在源码网站中查找,可以快速找到该结构或函数是在哪个文件的什么位置定义的,并且可以通过链接快速定位到定义位置,还可以看到相关的其他函数。同时,源码网站的注释非常丰富,遇到一些先前代码中定义的函数,只需要看注释就可以大概理解其功能,减轻代码越看越多、逐渐偏离主题的痛苦。