




延时队列
两个follower副本都已经拉取到了leader副本的最新位置,此时⼜向leader副本发送拉取请求,⽽leader副本并没有新的消息写⼊,那么此时leader副本该如何处理呢?
可以直接返回空的拉取结果给follower副本,不过在leader副本⼀直没有新消息写⼊的情况下,follower副本会⼀直发送拉取请求,并且总收到空的拉取结果,消耗资源。如下图:
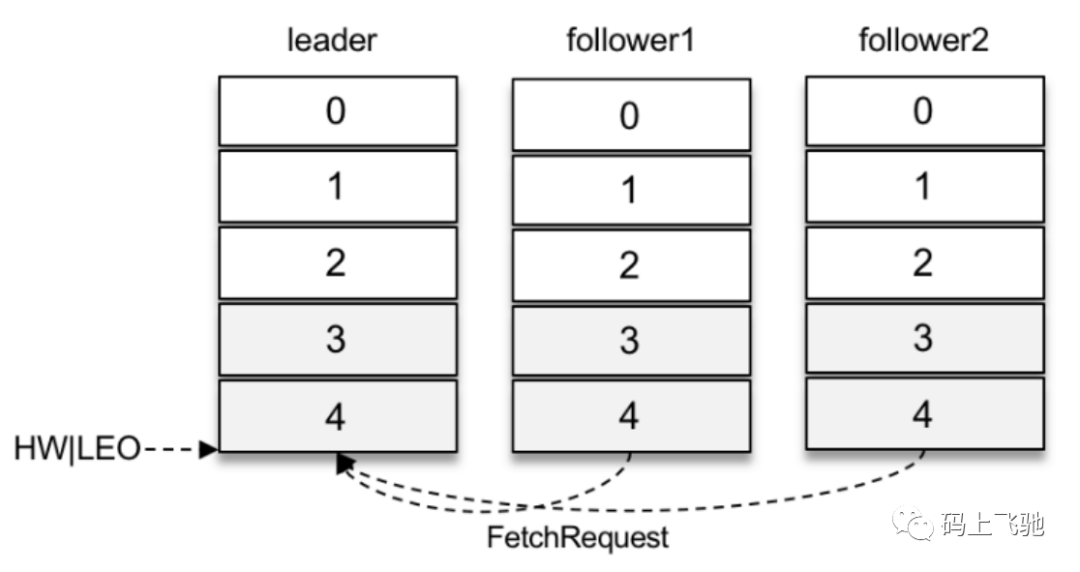
Kafka在处理拉取请求时,会先读取⼀次⽇志⽂件,如果收集不到⾜够多(fetchMinBytes,由参数fetch.min.bytes配置,默认值为1)的消息,那么就会创建⼀个延时拉取操作(DelayedFetch)以等待拉取到⾜够数量的消息。当延时拉取操作执⾏时,会再读取⼀次⽇志⽂件,然后将拉取结果返回给follower副本。
延迟操作不只是拉取消息时的特有操作,在Kafka中有多种延时操作,⽐如延时数据删除、延时⽣产等。
对于延时⽣产(消息)⽽⾔,如果在使⽤⽣产者客户端发送消息的时候将acks参数设置为-1,那么就意味着需要等待ISR集合中的所有副本都确认收到消息之后才能正确地收到响应的结果,或者捕获超时异常。
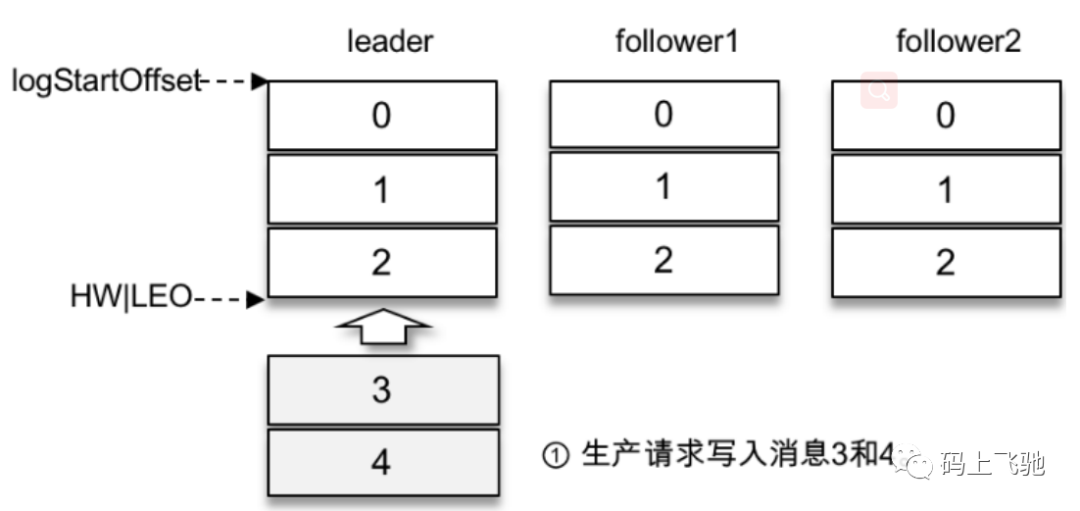
假设某个分区有3个副本:leader、follower1和follower2,它们都在分区的ISR集合中。不考虑ISR变动的情况,Kafka在收到客户端的⽣产请求后,将消息3和消息4写⼊leader副本的本地⽇志⽂件。
由于客户端设置了acks为-1,那么需要等到follower1和follower2两个副本都收到消息3和消息4后才能告知客户端正确地接收了所发送的消息。如果在⼀定的时间内,follower1副本或follower2副本没能够完全拉取到消息3和消息4,那么就需要返回超时异常给客户端。⽣产请求的超时时间由参数request.timeout.ms配置,默认值为30000,即30s。
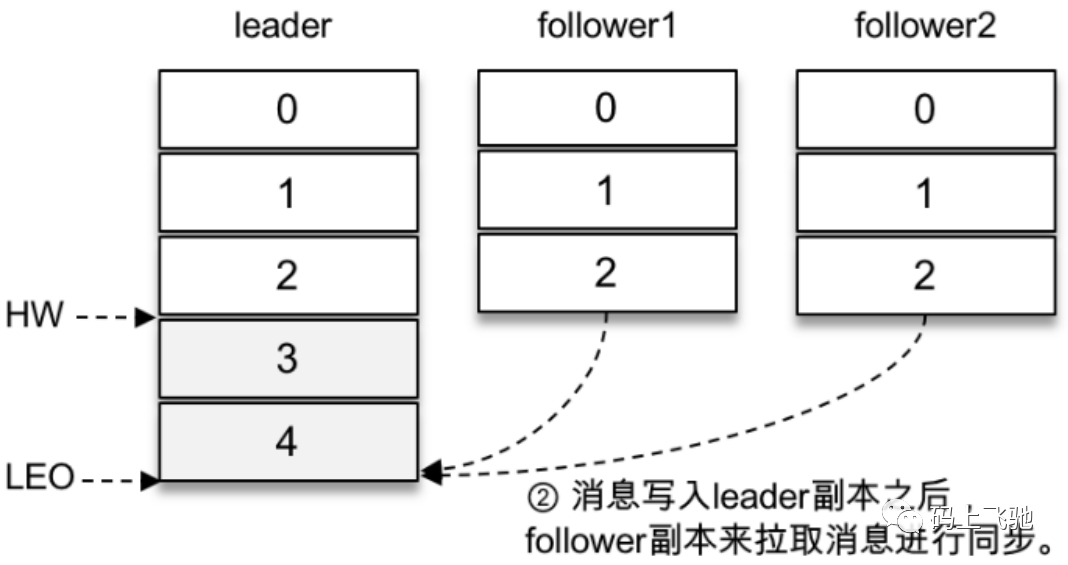
那么这⾥等待消息3和消息4写⼊follower1副本和follower2副本,并返回相应的响应结果给客户端的动作是由谁来执⾏的呢?
在将消息写⼊leader副本的本地⽇志⽂件之后,Kafka会创建⼀个延时的⽣产操作(DelayedProduce),⽤来处理消息正常写⼊所有副本或超时的情况,以返回相应的响应结果给客户端。
延时操作需要延时返回响应的结果,⾸先它必须有⼀个超时时间(delayMs),如果在这个超时时间内没有完成既定的任务,那么就需要强制完成以返回响应结果给客户端。其次,延时操作不同于定时操作,定时操作是指在特定时间之后执⾏的操作,⽽延时操作可以在所设定的超时时间之前完成,所以延时操作能够⽀持外部事件的触发。
就延时⽣产操作⽽⾔,它的外部事件是所要写⼊消息的某个分区的HW(⾼⽔位)发⽣增⻓。也就是说,随着follower副本不断地与leader副本进⾏消息同步,进⽽促使HW进⼀步增⻓,HW每增⻓⼀次都会检测是否能够完成此次延时⽣产操作,如果可以就执⾏以此返回响应结果给客户端;如果在超时时间内始终⽆法完成,则强制执⾏。
延时拉取操作,是由超时触发或外部事件触发⽽被执⾏的。超时触发很好理解,就是等到超时时间之后触发第⼆次读取⽇志⽂件的操作。外部事件触发就稍复杂了⼀些,因为拉取请求不单单由follower副本发起,也可以由消费者客户端发起,两种情况所对应的外部事件也是不同的。如果是follower副本的延时拉取,它的外部事件就是消息追加到了leader副本的本地⽇志⽂件中;如果是消费者客户端的延时拉取,它的外部事件可以简单地理解为HW的增⻓。
时间轮(TimeWheel)实现延时队列:
Kafka中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务TimerTask。
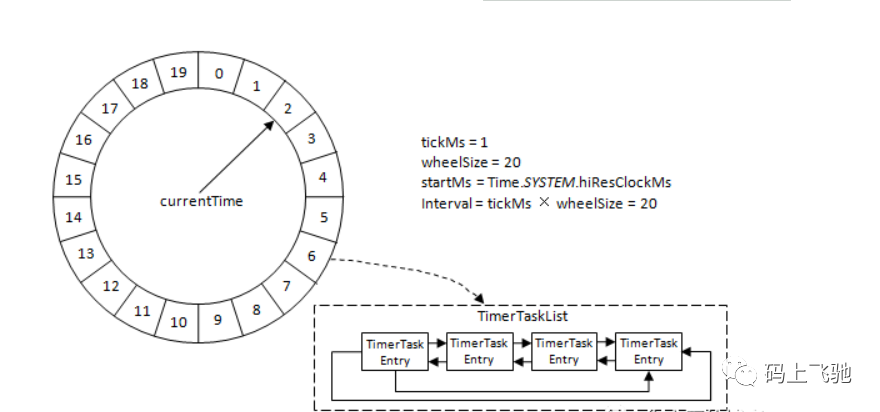
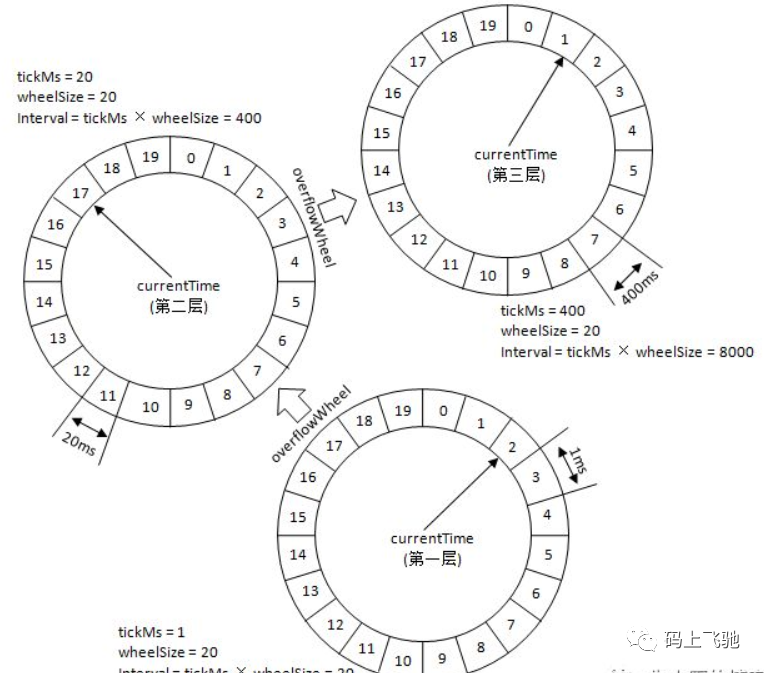
时间轮由多个时间格组成,每个时间格代表当前时间轮的基本时间跨度(tickMs)。时间轮的时间格个数是固定的,可用wheelSize来表示,那么整个时间轮的总体时间跨度(interval)可以通过公式 tickMs × wheelSize计算得出。时间轮还有一个表盘指针(currentTime),用来表示时间轮当前所处的时间,currentTime是tickMs的整数倍。currentTime可以将整个时间轮划分为到期部分和未到期部分,currentTime当前指向的时间格也属于到期部分,表示刚好到期,需要处理此时间格所对应的TimerTaskList的所有任务。
若时间轮的tickMs=1ms,wheelSize=20,那么可以计算得出interval为20ms。初始情况下表盘指针currentTime指向时间格0,此时有一个定时为2ms的任务插入进来会存放到时间格为2的TimerTaskList中。随着时间的不断推移,指针currentTime不断向前推进,过了2ms之后,当到达时间格2时,就需要将时间格2所对应的TimeTaskList中的任务做相应的到期操作。
此时若又有一个定时为8ms的任务插入进来,则会存放到时间格10中,currentTime再过8ms后会指向时间格10。如果同时有一个定时为19ms的任务插入进来怎么办?新来的TimerTaskEntry会复用原来的TimerTaskList,所以它会插入到原本已经到期的时间格1中。总之,整个时间轮的总体跨度是不变的,随着指针currentTime的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围在currentTime和currentTime+interval之间。
如果此时有个定时为350ms的任务该如何处理?直接扩充wheelSize的大小么?Kafka中不乏几万甚至几十万毫秒的定时任务,这个wheelSize的扩充没有底线,就算将所有的定时任务的到期时间都设定一个上限,比如100万毫秒,那么这个wheelSize为100万毫秒的时间轮不仅占用很大的内存空间,而且效率也会拉低。Kafka为此引入了层级时间轮的概念,当任务的到期时间超过了当前时间轮所表示的时间范围时,就会尝试添加到上层时间轮中。如下图:
重试队列
kafka没有重试机制不⽀持消息重试,也没有死信队列,因此使⽤kafka做消息队列时,需要⾃⼰实现消息重试的功能。
实现方案
创建新的kafka主题作为重试队列:
1:创建⼀个topic作为重试topic,⽤于接收等待重试的消息。
2:普通topic消费者设置待重试消息的下⼀个重试topic。
3:从重试topic获取待重试消息储存到redis的zset中,并以下⼀次消费时间排序。
4:定时任务从redis获取到达消费事件的消息,并把消息发送到对应的topic。
5:同⼀个消息重试次数过多则不再重试。
java代码实现方式:
1:新建springboot项⽬并配置maven的pom:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.8.RELEASE</version></parent><modelVersion>4.0.0</modelVersion><artifactId>kafla-retry-demo</artifactId><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.73</version></dependency></dependencies></project>
2:添加application.properties
# bootstrap.serversspring.kafka.bootstrap-servers=laifeiyang03:9092# key序列化器spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer# value序列化器spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer# 消费组id:group.idspring.kafka.consumer.group-id=retryGroup# key反序列化器spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer# value反序列化器spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer# redis数据库编号spring.redis.database=0# redis主机地址spring.redis.host=laifeiyang04# redis端⼝spring.redis.port=6379# Redis服务器连接密码(默认为空)#spring.redis.password=# 连接池最⼤连接数(使⽤负值表示没有限制)spring.redis.jedis.pool.max-active=20# 连接池最⼤阻塞等待时间(使⽤负值表示没有限制)spring.redis.jedis.pool.max-wait=-1# 连接池中的最⼤空闲连接spring.redis.jedis.pool.max-idle=10# 连接池中的最⼩空闲连接spring.redis.jedis.pool.min-idle=0# 连接超时时间(毫秒)spring.redis.timeout=1000# Kafka主题名称spring.kafka.topics.test=tp_demo_retry_01# 重试队列spring.kafka.topics.retry=tp_demo_retry_02
3:RetryqueueApplication.java
package com.laifeiyang.dev;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplicationpublic class RetryqueueApplication {public static void main(String[] args) {SpringApplication.run(RetryqueueApplication.class, args);}}
4:AppConfig.java
package com.laifeiyang.dev.config;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.redis.connection.RedisConnectionFactory;import org.springframework.data.redis.core.RedisTemplate;@Configurationpublic class AppConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {RedisTemplate<String, Object> template = new RedisTemplate<>();// 配置连接⼯⼚template.setConnectionFactory(factory);return template;}}
5:KafkaController.java
package com.laifeiyang.dev.controller;import com.laifeiyang.dev.service.KafkaService;import org.apache.kafka.clients.producer.ProducerRecord;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Value;import org.springframework.web.bind.annotation.PathVariable;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;import java.util.concurrent.ExecutionException;@RestControllerpublic class KafkaController {@Autowiredprivate KafkaService kafkaService;@Value("${spring.kafka.topics.test}")private String topic;@RequestMapping("/send/{message}")public String sendMessage(@PathVariable String message) throws ExecutionException, InterruptedException {ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);String result = kafkaService.sendMessage(record);return result;}}
6:KafkaService.java
package com.laifeiyang.dev.service;import org.apache.kafka.clients.producer.ProducerRecord;import org.apache.kafka.clients.producer.RecordMetadata;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.kafka.support.SendResult;import org.springframework.stereotype.Service;import java.util.concurrent.ExecutionException;@Servicepublic class KafkaService {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public String sendMessage(ProducerRecord<String, String> record) throws ExecutionException, InterruptedException {SendResult<String, String> result = this.kafkaTemplate.send(record).get();RecordMetadata metadata = result.getRecordMetadata();String returnResult = metadata.topic() + "\t" + metadata.partition() +"\t" + metadata.offset();System.out.println("发送消息成功:" + returnResult);return returnResult;}}
7:ConsumerListener.java
package com.laifeiyang.dev.config;import com.laifeiyang.dev.service.KafkaRetryService;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.kafka.annotation.KafkaListener;import org.springframework.stereotype.Component;@Componentpublic class ConsumerListener {private static final Logger log = LoggerFactory.getLogger(ConsumerListener.class);@Autowiredprivate KafkaRetryService kafkaRetryService;private static int index = 0;@KafkaListener(topics = "${spring.kafka.topics.test}", groupId = "${spring.kafka.consumer.group-id}")public void consume(ConsumerRecord<String, String> record) {try {// 业务处理log.info("消费的消息:" + record);index++;if (index % 2 == 0) {throw new Exception("该重发了");}} catch (Exception e) {log.error(e.getMessage());// 消息重试kafkaRetryService.consumerLater(record);}}}
8:KafkaRetryService.java
package com.laifeiyang.dev.service;import com.alibaba.fastjson.JSON;import com.laifeiyang.dev.entity.RetryRecord;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.common.header.Header;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Value;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.stereotype.Service;import java.nio.ByteBuffer;import java.util.Calendar;import java.util.Date;@Servicepublic class KafkaRetryService {private static final Logger log = LoggerFactory.getLogger(KafkaRetryService.class);/*** 消息消费失败后下⼀次消费的延迟时间(秒)* 第⼀次重试延迟10秒;第 ⼆次延迟30秒,第三次延迟1分钟...*/private static final int[] RETRY_INTERVAL_SECONDS = {10, 30, 1*60, 2*60, 5*60, 10*60, 30*60, 1*60*60, 2*60*60};/*** 重试topic*/@Value("${spring.kafka.topics.retry}")private String retryTopic;@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void consumerLater(ConsumerRecord<String, String> record){// 获取消息的已重试次数int retryTimes = getRetryTimes(record);Date nextConsumerTime = getNextConsumerTime(retryTimes);// 如果达到重试次数,则不再重试if(nextConsumerTime == null) {return;}// 组织消息RetryRecord retryRecord = new RetryRecord();retryRecord.setNextTime(nextConsumerTime.getTime());retryRecord.setTopic(record.topic());retryRecord.setRetryTimes(retryTimes);retryRecord.setKey(record.key());retryRecord.setValue(record.value());// 转换为字符串String value = JSON.toJSONString(retryRecord);// 发送到重试队列kafkaTemplate.send(retryTopic, null, value);}/*** 获取消息的已重试次数*/private int getRetryTimes(ConsumerRecord record){int retryTimes = -1;for(Header header : record.headers()){if(RetryRecord.KEY_RETRY_TIMES.equals(header.key())){ByteBuffer buffer = ByteBuffer.wrap(header.value());retryTimes = buffer.getInt();}}retryTimes++;return retryTimes;}/*** 获取待重试消息的下⼀次消费时间*/private Date getNextConsumerTime(int retryTimes){// 重试次数超过上限,不再重试if(RETRY_INTERVAL_SECONDS.length < retryTimes) {return null;}Calendar calendar = Calendar.getInstance();calendar.add(Calendar.SECOND, RETRY_INTERVAL_SECONDS[retryTimes]);return calendar.getTime();}}
9:RetryListener.java
package com.laifeiyang.dev.config;import com.alibaba.fastjson.JSON;import com.laifeiyang.dev.entity.RetryRecord;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.producer.ProducerRecord;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Value;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.data.redis.core.ZSetOperations;import org.springframework.kafka.annotation.KafkaListener;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.scheduling.annotation.EnableScheduling;import org.springframework.scheduling.annotation.Scheduled;import org.springframework.stereotype.Component;import java.util.Set;import java.util.UUID;@Component@EnableSchedulingpublic class RetryListener {private Logger log = LoggerFactory.getLogger(RetryListener.class);private static final String RETRY_KEY_ZSET = "_retry_key";private static final String RETRY_VALUE_MAP = "_retry_value";@Autowiredprivate RedisTemplate<String,Object> redisTemplate;@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@Value("${spring.kafka.topics.test}")private String bizTopic;@KafkaListener(topics = "${spring.kafka.topics.retry}")public void consume(ConsumerRecord<String, String> record) {System.out.println("需要重试的消息:" + record);RetryRecord retryRecord = JSON.parseObject(record.value(),RetryRecord.class);/*** 防⽌待重试消息太多撑爆redis,可以将待重试消息按下⼀次重试时间分开存储放到不同介质* 例如下⼀次重试时间在半⼩时以后的消息储存到mysql,并定时从mysql读取即将重试的消息储储存到redis*/// 通过redis的zset进⾏时间排序String key = UUID.randomUUID().toString();redisTemplate.opsForHash().put(RETRY_VALUE_MAP, key,record.value());redisTemplate.opsForZSet().add(RETRY_KEY_ZSET, key,retryRecord.getNextTime());}/*** 定时任务从redis读取到达重试时间的消息,发送到对应的topic*/// @Scheduled(cron="2 * * * * *")@Scheduled(fixedDelay = 2000)public void retryFromRedis() {log.warn("retryFromRedis----begin");long currentTime = System.currentTimeMillis();// 根据时间倒序获取Set<ZSetOperations.TypedTuple<Object>> typedTuples =redisTemplate.opsForZSet().reverseRangeByScoreWithScores(RETRY_KEY_ZSET, 0,currentTime);// 移除取出的消息redisTemplate.opsForZSet().removeRangeByScore(RETRY_KEY_ZSET, 0,currentTime);for(ZSetOperations.TypedTuple<Object> tuple : typedTuples){String key = tuple.getValue().toString();String value = redisTemplate.opsForHash().get(RETRY_VALUE_MAP,key).toString();redisTemplate.opsForHash().delete(RETRY_VALUE_MAP, key);RetryRecord retryRecord = JSON.parseObject(value,RetryRecord.class);ProducerRecord record = retryRecord.parse();ProducerRecord recordReal = new ProducerRecord(bizTopic,record.partition(),record.timestamp(),record.key(),record.value(),record.headers());kafkaTemplate.send(recordReal);}// todo 发⽣异常将发送失败的消息重新发送到redis}}
10:RetryRecord.java
package com.laifeiyang.dev.entity;import org.apache.kafka.clients.producer.ProducerRecord;import org.apache.kafka.common.header.Header;import org.apache.kafka.common.header.internals.RecordHeader;import java.nio.ByteBuffer;import java.util.ArrayList;import java.util.List;public class RetryRecord {public static final String KEY_RETRY_TIMES = "retryTimes";private String key;private String value;private Integer retryTimes;private String topic;private Long nextTime;public RetryRecord() {}public String getKey() {return key;}public void setKey(String key) {this.key = key;}public String getValue() {return value;}public void setValue(String value) {this.value = value;}public Integer getRetryTimes() {return retryTimes;}public void setRetryTimes(Integer retryTimes) {this.retryTimes = retryTimes;}public String getTopic() {return topic;}public void setTopic(String topic) {this.topic = topic;}public Long getNextTime() {return nextTime;}public void setNextTime(Long nextTime) {this.nextTime = nextTime;}public ProducerRecord parse() {Integer partition = null;Long timestamp = System.currentTimeMillis();List<Header> headers = new ArrayList<>();ByteBuffer retryTimesBuffer = ByteBuffer.allocate(4);retryTimesBuffer.putInt(retryTimes);retryTimesBuffer.flip();headers.add(new RecordHeader(RetryRecord.KEY_RETRY_TIMES,retryTimesBuffer));ProducerRecord sendRecord = new ProducerRecord(topic, partition, timestamp, key, value, headers);return sendRecord;}}
至此,kafka就说到这里,实际关于kafka的一些实际运用场景很多很多,比如主要运用的消息传递、实时监控指标、日志汇总、流处理、活动采集等等,这里就不多说了,大家也可根据kafka源码自行剖析下部分场景,比如broker的启动流程、topic的创建流程、producer生产者流程、consumer消费者流程等等。

