




通过PG等待事件来定位系统问题,从理论上是可行的,这一点在前面几天的讨论中已经做了分析。不过到底效果如何呢?如果真的有效,那么真的为PG数据库运维提供了一种新武器。实际上,从数据库的设计来说,等待事件的最主要的目的也是真实反映数据库系统的运行状态。只是PG的核心开发人员把数据给了我们,但是并没有给我们解析数据的密码。其实Oracle也一样,OWI最初也只是为内部研发人员服务的,只是后来Oracle通过statspack报告,awr等,逐渐把等待事件分析的一些算法提供给了我们。
就目前的情况看,通过等待事件来解析一些我们以前不太容易分析的问题,似乎效果还是挺不错的。我搞了个测试环境,通过benchmark来压测一个瀚高数据库。第一次我把shared_buffers设置为1GB,然后进行压测,在压测中段选取30分钟的D-SMART等待事件采样(3分钟一次):
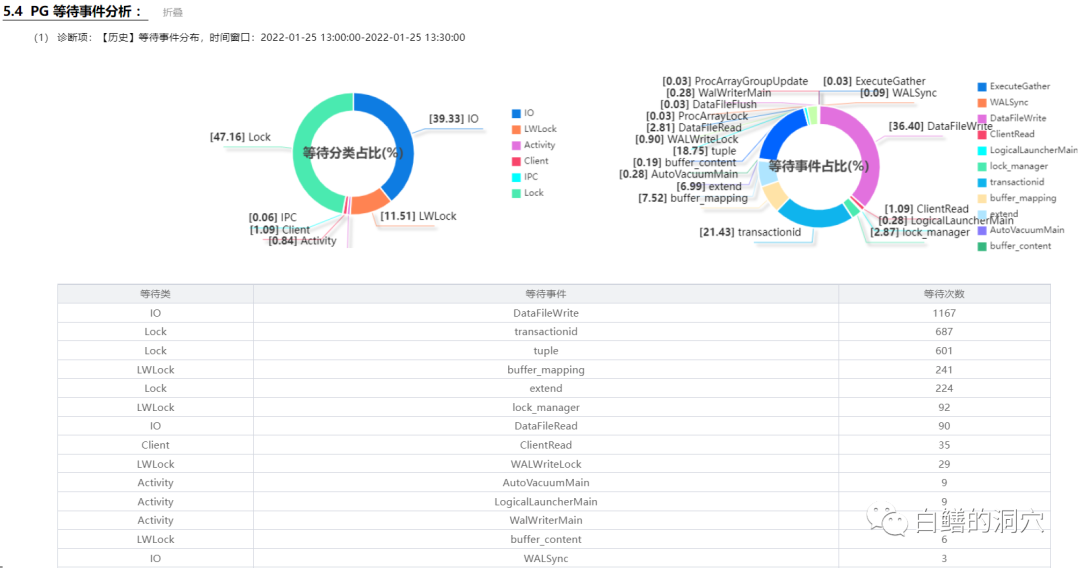
可以看出最多的等待事件是数据文件写,其次是等待事务结束,以及元组锁。Buffer_mapping这个和shared buffers相关的等待事件也很高,半小时内采样到了241个。我们再来看看把shared buffers加大到8GB后的30分钟采样数据。
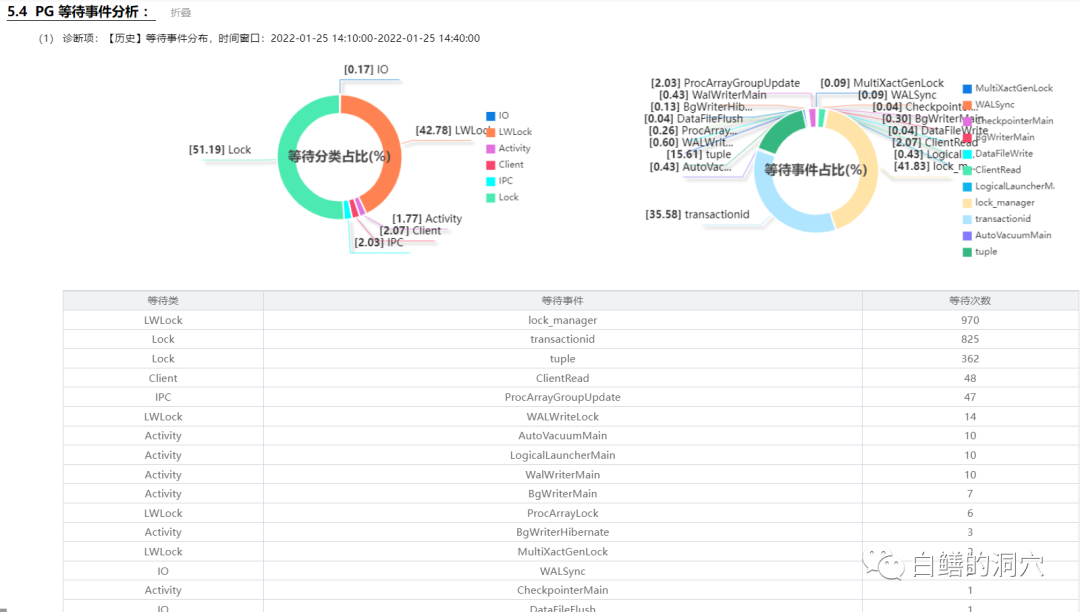
可以看到,数据完全不同了。实际上从benchmark测试的结果也可以看到,在第一次测试的时候,tpmc从40多万上升到60万,然后下降,最后稳定在40多万。缓冲区加大到8GB后,TPMC一直稳定在60多万,明显要高了不少。
从等待事件上看,最高的是锁管理lock_manager,这是Backend添加锁或者等待锁时候等待的LwLock。这个等待和等待事务提交结束的数量差不多。再其次是元组锁。其他等待事件相对就较少了。特别是少了DataFileWrite和Buffer_mapping这两个刚才那次测试中比较多的等待事件。
从上面的等待事件来看,因为Shared_buffers设置了比较合适的值,减少了因为共享缓冲区不足而引起的缓冲区的争用和为了给脏数据腾地方,大量刷新数据的等待。等待事件反映出的总体情况是解释得通的。
如果不使用等待事件分析,通过其他的方法来分析共享缓冲池是否不足,就需要用一些其他的手段了。可能有人会想到共享缓冲区的命中率。
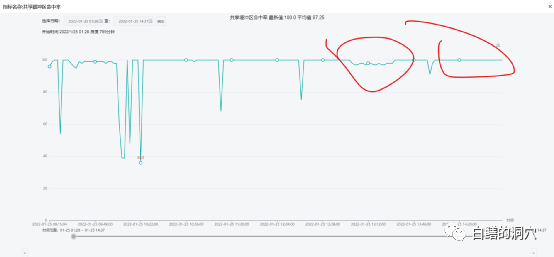
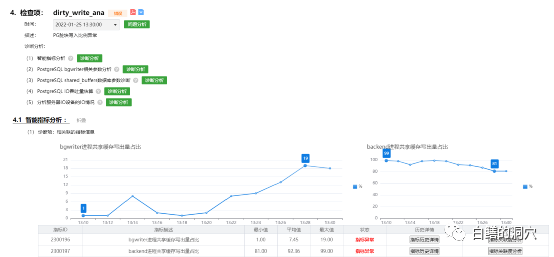
实际上,在D-SMART中,在没有等待事件分析的知识库的时候,我们是通过backend写脏块的比例来发现shared buffers的性能问题的。不过由于PG独特的架构设计,这种分析还是存在一定的误判可能,因此只能从一定角度发现问题,但是不能比较明确的确认问题。
而从上面的等待事件分析的效果来看,对于同一时段的数据分析,等待事件反映出来的问题更为精准。
下面再做一个测试,我们修改了和一个CHECKPOINT有关的配置,同时把MAX_WAL_SIZE从4GB调小到1GB。再重新初始化,进行同样的压测:
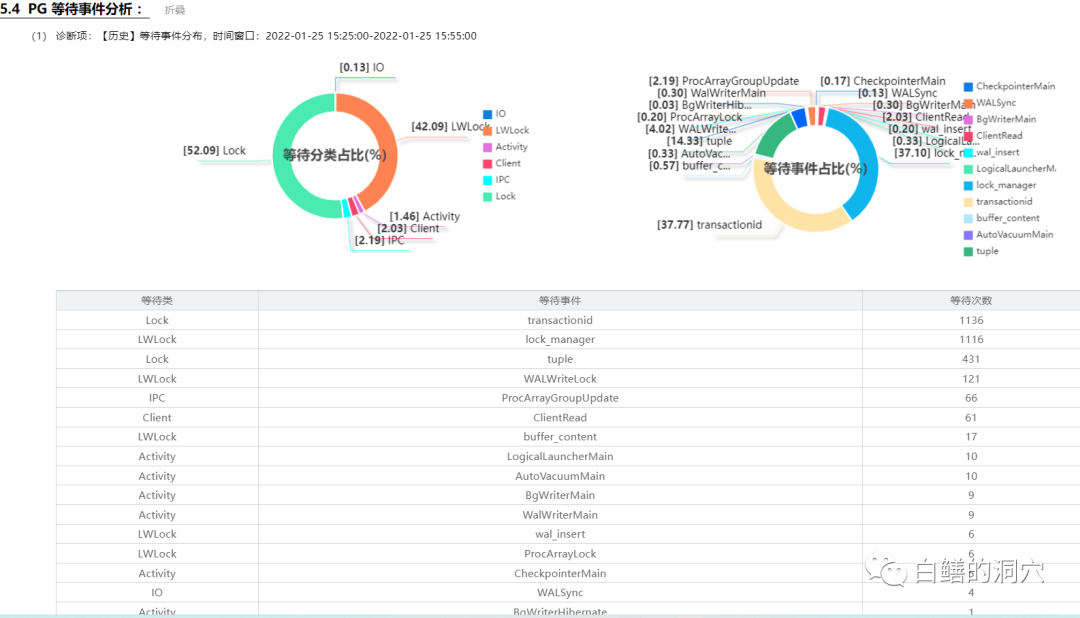
可以看出,WALWritLock以及其他的WAL相关的等待多了一些,CHECKPOINT也出现了更多的等待。同时buffer_content也出现了少量的等待。这些等待的行为和CKPT存在瓶颈是十分一致的。通过一个30分钟的抽样等待事件分析同样可以发现这里存在的一些问题。从TPMC上看,也略有下降。在这个测试用例中,等待事件仍然感受到了数据库系统的一些细微的变化。
上面的图表界面是最近在D-SMART中新添加的等待事件分析工具,目前只是利用采集的等待事件数据进行展示。目前还只能够提供分析数据给有经验的专家看,智能化分析的能力需要等知识图谱构建完成才能具备。届时,这个工具不仅仅能对等待事件进行罗列和排序,而且能直接告诉我们,从等待事件上看,当前系统存在的主要问题有哪些,风险有哪些。今年春节在家里的时间比较长,我想应该能够把PG等待事件相关的知识图谱梳理清楚。相对于有差不多2000个等待事件的Oracle来说,PG的等待事件数量不到1/10,相对来说还是比较简单的。有了当年分析Oracle等待事件的思想,也把PG等待事件梳理的速度大大提高了。
今天的分析就到这里吧。从这个例子看,如果我们能够精准的解读等待事件,将获得一个更为优秀的PG性能分析工具,为PG数据库运维与故障预警提供更为准确的信息。
