




灾难描述
周日收到同事求助:线上某个业务线TiDB集群不可用了。简单询问下集群环境以及目前情况。
1、TiDB/PD混合部署
2、PD有3个节点组成集群,其中只剩一个PD节点“存活”,从tiup cluster display xxx-tidb-cluster可以看出,整个集群已经不可用。触目惊心、详见下图
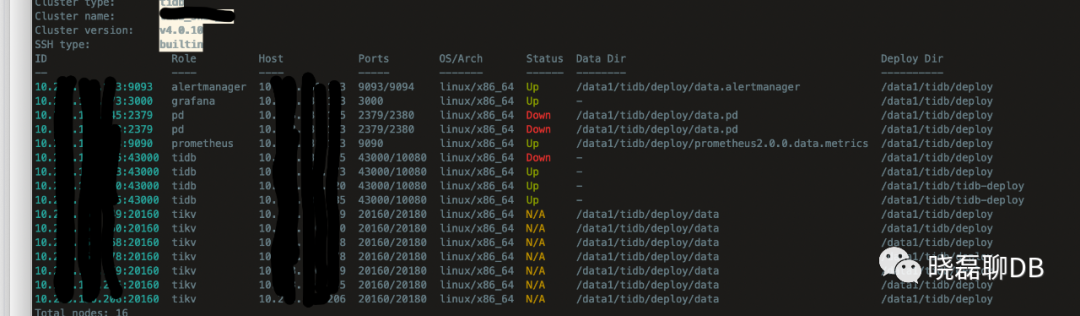
看到这么多PD/TiDB Down+TiKV N/A,作为多年的老司机,我也轻轻的吸了一口凉气。
3、整个集群宕机已经有一段时间,小伙伴可能有些慌乱,并且中间尝试集群restart、--force下线PD、扩容PD等操作,具体细节以及顺序已经忘却。
需要我做的就是恢复集群
查看现场
只有PD1能ping且PD进程运行,PD2都ping不通,PD3可以登录,但是启动服务(Tiup启动卡死,登录服务器手动启动报错)失败。
分析问题
3个PD节点的集群,只要保证多数PD节点存活即可,所以我需要解决的是将PD2和PD3其中的一台服务启动。所以我需要采用2条腿走路:
(1)那我先让小伙伴提交ping不通的PD2服务器的自动重启任务,也就是希望能通过另一台PD的启动使得实现3个PD中多数PD存活,从而恢复PD集群的可用性。

(2)看下能否恢复PD3上的PD服务,虽然之前被tiup salce-in --force清理过,不过以当时PD集群状态,好在data.pd还没有被干掉,pd-server bin和启动script都还在。这就需要执行./run_pd.sh启动PD,然后看PD的日志并且排错了,发现有如下的报错日志:

PD 启动报错:etcd cluster ID mismatch的解决方案:
PD 启动参数中的 --initial-cluster 包含了某个不属于该集群的成员。遇到这个错误时请检查各个成员的所属集群,剔除错误的成员后即可正常启动。
我正在修改启动脚本时,小伙伴传来了好消息,PD2启动成功了。
“解决问题”
事情到这里就解决了,那有人说了,你不就是”重启大法“好么,这篇文章也太草草了事了,朋友们不要着急,不要着急,好戏在👇
PD集群恢复杀器之PD-RECOVER
上面说到重启大法好,那假如PD2和PD3由于硬件故障就是启动不起来怎么办?
pd-recover了解下?大家都在想还有这最后救命的利器,就跟官网介绍时说的:PD Recover 是对 PD 进行灾难性恢复的工具,用于恢复无法正常启动或服务的 PD 集群。
我今天用测试环境复盘+模拟了下pd-recover的使用。看我的集群图:3tidb/pd,4tikv,其中PD和tidb公用服务器。
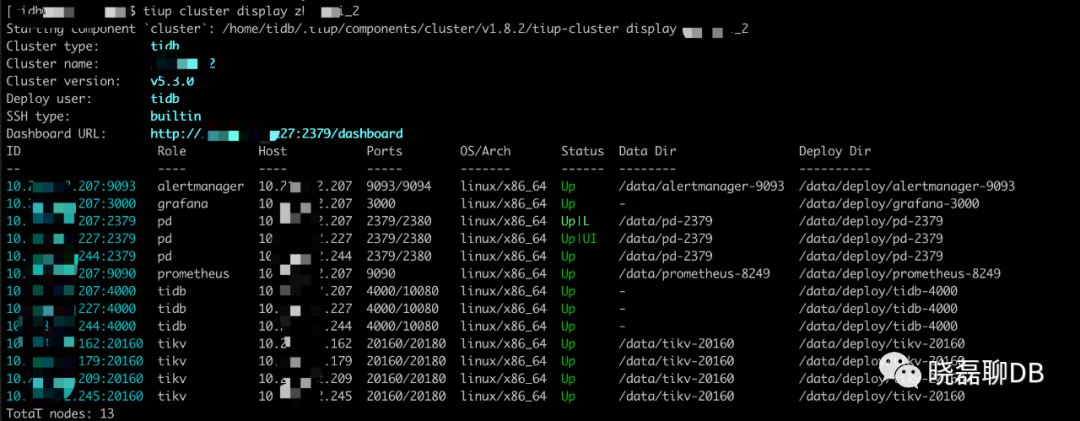
我对一个正常运行的测试TiDB集群,暴力rm -rf data.pd删除了PD1和PD2的数据(看到rm -rf时,刺激不刺激?)。然后整个集群就是下面的状态了。
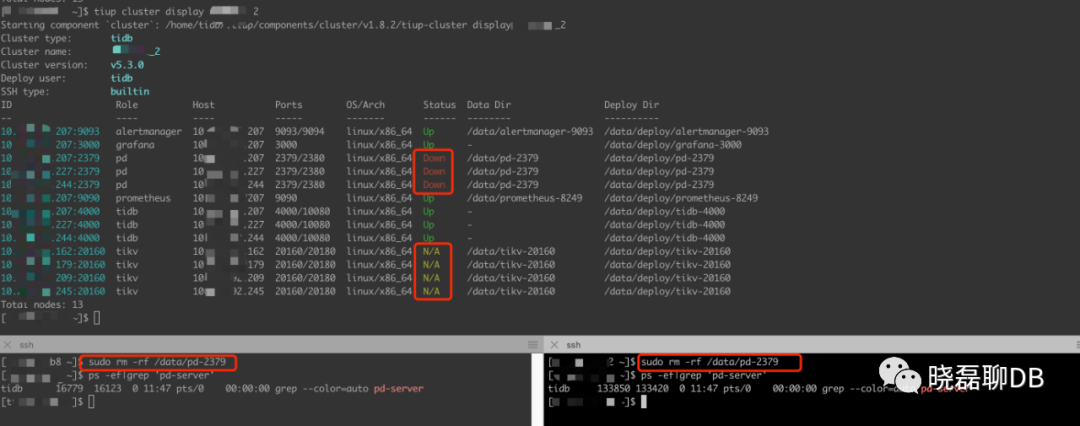
就算是测试环境,看到上面的这种情况也是需要“心动”一下的,不过是“悸动”。
OK,开始恢复
部署安装 PD Recover
下载跟 TiDB 集群版本适配的官方pd-recover安装包,测试集群是5.3.0,那么执行下面的命令:
wget https://download.pingcap.org/tidb-v5.3.0-linux-amd64.tar.gz
解压安装包:
tar -zxvf tidb-v5.3.0-linux-amd64.tar.gz
进入到bin目录,找到pd-recover
cd tidb-v5.3.0-linux-amd64/bin/
使用 PD Recover 恢复 PD 集群 本小节详细介绍如何使用 PD Recover 来恢复 PD 集群。
获取 Cluster ID
一般在 PD、TiKV 或 TiDB 的日志中都可以获取最早的 Cluster ID。你可以直接在服务器上查看日志以获取 Cluster ID。
建议从 PD 日志获取 Cluster ID,使用以下命令,从 PD 日志中获取 Cluster ID,首先进入到PD的日志目录,然后执行下面的命令:
cat pd.log | grep "init cluster id"
[2021/12/09 10:48:16.451 +08:00] [INFO] [server.go:357] ["init cluster id"] [cluster-id=6917597403461510168]
[2022/01/25 11:15:08.748 +08:00] [INFO] [server.go:357] ["init cluster id"] [cluster-id=6917597403461510168
对了,有人说了假如PD1和PD2机器都无法启动,所以我可以从PD3的日志中获取。那又有人说了假如PD3也挂了,整个PD集群就没有可以查看的日志怎么办?别着急,还可以通过tidb和tikv的日志获取Cluster id,方式如下:
从 TiDB 日志获取 Cluster ID cat tidb.log | grep "init cluster id"
从 TiKV 日志获取 Cluster ID
cat tikv.log | grep "connect to PD cluster"
获取已分配 ID
使用 pd-recover 恢复 PD 集群时,需要指定 alloc-id。alloc-id 的值是一个比当前已经分配的最大的 Alloc ID 更大的值。
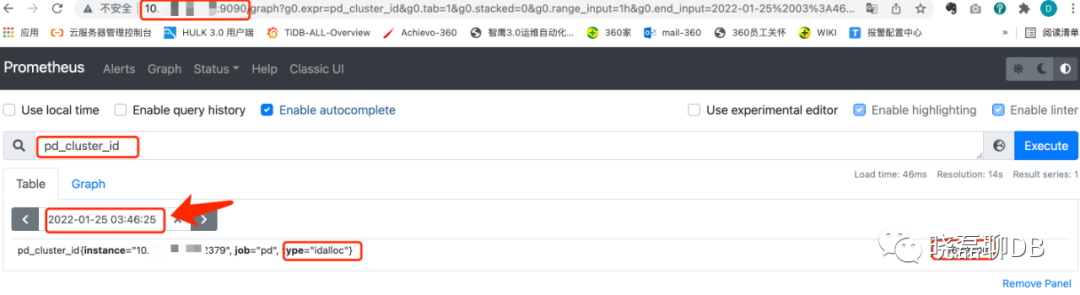
(1)访问prometheus地址获取alloc-id
访问 TiDB 集群的 Prometheus 访问页面。在输入框中输入 pd_cluster_id 并点击 Execute 按钮查询数据,获取查询结果中的最大值。
另外一种获取alloc-id的方式是:在3台PD服务器上执行下面的命令查看当前alloc ID最大值
cat pd*.log| grep "idAllocator allocates a new id" | awk -F'=' '{print $2}' | awk -F']' '{print $1}' | sort -r -n | head -n 1
1609000
将查询结果中的最大值乘以 100,也就是1609000*100=160900000,作为使用 pd-recover 时指定的 alloc-id。
”部署一套新的 PD 集群“
官网文档的名字叫:部署一套新的PD集群,这个名称非常容易让人误解,你说我PD多数都挂了,你还让我tiup scale-out去扩容新PD?所以我在此特别的跟大家讲清楚:如果原来的3台PD节点服务器都没有问题,你完全可以使用老的PD集群,只是需要先把PD的数据删除,这样重新启动PD集群,PD内部会重新生成数据,也就是说重新生成的数据相对于之前的集群来讲相当于“部署了一套新的PD集群”。
OK,本次测试集群还有PD3存活,所以我要停止PD3,并且将PD3的data.pd目录mv走(相当于删除)。
systemctl stop pd-2379.service
mv /data/pd-2379 /data/bakpd2379
注意:上文提到本次模拟就是先删除了PD1和PD2的PD数据,另外PD3的数据删除用的是mv而不是rm,这样也有个PD数据备份,哈哈。
这一步是删除旧的数据目录,现在所有PD集群节点都已经down,并且数据目录都已经被我删除。
tiup cluster start zhanshi_2 -R pd
重启完毕PD,一定要tiup cluster display看下集群状态,尤其看看PD集群是否已经start成功。下面就是最最重要的环节,pd- recover恢复了
使用 pd-recover 恢复集群
./pd-recover -endpoints http://pd-id:2379 -cluster-id 6917597403461510168 -alloc-id 160900000
recover success! please restart the PD cluster
重启整个集群
当出现 recovery success 的提示信息时,重启整个集群。现在看下集群的状态已经恢复:
常见问题
获取 Cluster ID 时发现有多个 Cluster ID
新建 PD 集群时,会生成新的 Cluster ID。可以通过日志判断旧集群的 Cluster ID,因为pd-recover用的就是最早的集群id。
没有重启PD集群导致的pd-recover修复失败
执行 pd-recover 时返回错误 Error while dialing dial tcp XXX:2379: connect: connection refused+context deadline exceeded,因为执行 pd-recover 时需要 PD 提供服务,请先“部署”并启动 PD 集群。
{"level":"warn","ts":"2022-01-25T13:36:48.549+0800","caller":"clientv3/retry_interceptor.go:61","msg":"retrying of unary invoker failed","target":"endpoint://client-76c8e2dd-954b-4257-89ff-694380d760c0/XXXX:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = latest balancer error: all SubConns are in TransientFailure, latest connection error: connection error: desc = "transport: Error while dialing dial tcp XXX:2379: connect: connection refused""}
context deadline exceeded
问题反思
1、其实还听“小伙伴”说周日的下午其实集群状态出现过“恢复”,后来又死了,在这里需要给看文章的小伙伴们提个醒,如果由于SQL导致的集群阻塞,可以通过上游的VIP限流或者下线,max_execution_time是个在集群有问题时很好的一个SQL“杀器”,动态配置后立刻生效,至少可以让集群缓口气。
2、出问题慌乱是没用的,在慌乱的基础上做的操作可能是错上加错。
3、冷静思考,别着急操作,多套方案,找出最优解(周日的方案其实就靠重启物理服务器实现多PD节点存活,集群自动恢复的例子)。
4、记录所有对集群的操作保存记录,以便事后复盘。
5、未雨绸缪,慢SQL啥的平常需要按周或者周月report给业务负责人优化,还有一些SQL上线前的审核(是否用到索引,执行效率如何)等等
6、上文有模拟“其他人”问日志都找不到的问题,这时我就想说了,其实真的是非常非常核心的tidb集群的话,建议通过ETL将日志落到S3上,这时就不怕因为集群问题没法查看日志了。对了这也是我之前一篇TiDB生态文章给大家讲到的,凡事要考虑周全。
写在最后,这篇文章讲的是多数PD不可用的时候的恢复方案,大家有没有想过,当tikv的region在多数副本不可用时怎么搞?哈哈,下篇文章有的写了。
