





MySQL复制的模式分为异步复制、全同步复制及半同步模式。下面将针对不同复制模式下出现数据一致性问题进行详细分析。
主库在执行完客户端提交的事务后,会立即提交并将结果返给客户端,并不关心从库是否已经接收日志并处理,如果此时主库上已经提交的事物因为某些原因未传送到备库,同时主库发生宕机,并在此时从库提升为主,这样就会导致新主库数据缺失,从而造成主从数据不一致的情况发生。该复制模式下,这种情况是必然会发生的。过程如下图:
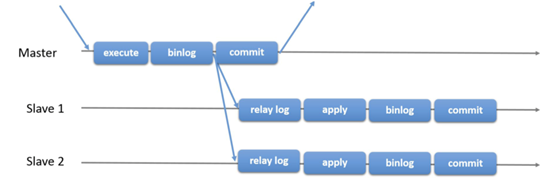
主库将事务写入到Binlog 文件中,并通知 Dump 线程发送这些新的 Binlog,然后主库就会继续处理提交操作,所以此时无法保证这些 Binlog已经成功传到任何一个从库节点上。
指当主库执行完一个事务,且所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以主库完成一个事务的时间会被拉长,从而全同步复制的性能必然会受到较大的影响。
全同步是在MySQL NDB Cluster上采用的复制方式,该集群在中国大陆使用极少,早些年曾在某行有过应用,不过据说坑很多,不建议采用。全复制会严重影响主库的事物提交性能,对网络要求非常严格,不适合同城、异地的架构场景。
NDB是分布式存储引擎,无共享架构,严格来说NDB节点不是复制,而是2pc,确保事务提交的强一致。
3.半同步复制(Semisynchronous replication)
是介于全同步复制与全异步复制之间的一种复制方式。当执行完一个事务后,主库需要等待至少一个从库节点收到日志事件并刷新Binlog 到 Relay Log 文件中的ACK确认消息后,才能提交并返回给客户端确认信息,主库一般不需要等待所有从库的ACK。这里需要说明返回的确认信息是确保日志传送到备库并写入到中继日志(备库还需要通过sql线程重放后才真正将数据写入到备库),而不是在备库已经完全完成并且提交、已将真正数据写入。理论上只要日志传送到备库并写入到中继日志,那么就可以保证数据一致性,只是会有一定的延迟。
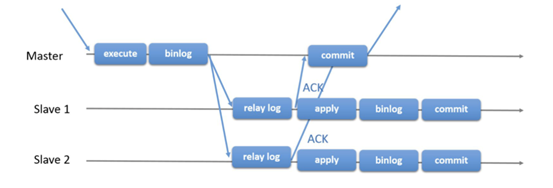
相对于异步复制,半同步复制提高了数据的安全性,同时它也带来了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
一般在实际生产中,我们把同城或同机房,网络延迟小的(2ms内)设置为半同步,对于异地延迟在10ms以上的,采用异步复制的方式。
架构图:
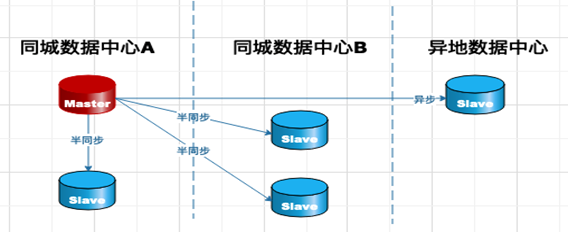
一般将rpl_semi_sync_master_wait_for_slave_count 设置为1(该参数用于设置从库返回ACK的数量,达到多少后主库就可以提交返回给客户端。设置为1,代表只要有一个从库接收到日志并返回ACK确认信息给主库后,主库就可以提交返回给客户端),在保证数据一致性的情况下而不影响主库事务处理的性能。
MySQL官方称该复制模式为无损复制,从复制机制上看的确会保证数据的不丢失。但真实情况是这样吗?下面我们从半同步的两种形式进行分析。
半同步有两种形式:
复制过程如下:
1 > session 发出commit请求
2 > flush binlog and sync binlog
3 > InnoDB 引擎层 commit
4 > MASTER发送binlog到SLAVE,等待SLAVE返回ACK确认信息
5 > SLAVE接收binlog写入relay log ,刷盘完成发送ACK确认包给MASTER
6 > MASTER接收到ACK信息后返回 commit ok 信息给session
首先要理解第三步引擎层提交的含义。第三步完成后,虽然由于主库还未收到从库返回的确认信息,因此当前会话一直无法完成并返回给客户端,但是主库的其他会话已经可以看到执行的结果了,(如果按照事务隔离级别理解的话,我们可以把它看成对主库的读取,出现了脏读现象)。
例如:

此时就会出现两种情形:
1.数据层不一致。主库宕机重启后,依然有之前转帐100元的记录,由于从库未接收到日志,并提升为主库后是无法再同步这部分数据的。(主库重启后数据库会跳过ACK验证,引擎层会将事务提交(其实已经提交了),就会比新主库多一条记录)。
2.应用层不一致。前后看到的结果不一样。
最致命的是应用层不一致,数据层不一致我们可以通过数据补偿或应用重做的方法解决,但应用层不一致就是逻辑错误,是不能容忍的!
复制过程如下:
1 > session 发出commit请求
2 > flush binlog and sync binlog
3 > MASTER发送binlog到SLAVE,等待SLAVE发送ACK确认
4 > SLAVE 接收binlog写入relay log ,刷盘完成发送ACK确认包给MASTER
5 > MASTER接收到ACK信息后,InnoDB 引擎层 commit
6 > MASTER返回 commit ok 信息给session
可以理解增强半同步是接收从库返回ACK信息后再做引擎层提交,而普通半同步是先做引擎层提交再接收从库返回ACK信息,虽然只是改变了顺序,但却解决了普通半同步的脏读、应用层不一致的问题。
例如:
你给小王转账100元,在步骤五完成后(和上述的步骤三一样,引擎层提交),小王查询自己的余额多了100元,小王很满意的给你回了一条信息,钱已收到!但如果这个时候(在第五步完成后发生异常,主库宕机,并且发生了主从切换),这个时候备库提升为主库,由于之前的转账100元信息已经发送到备库,那么小王依然可以查看到之前转账的100元!
如果在步骤5之前发生异常,由于主库引擎层未提交,那么其他会话也是无法查看到最新的记录的。
这个时候就不会出现上述的应用层数据不一致问题,应用层是一致的(或者是最终一致的),前后看到的结果是一样的!
数据库层是否会一致呢?第五步完成后数据是一致的,但如果第4步之前发生异常就会出现数据不一致的现象(数据层的不一致可以很容易通过一些手段解决),但应用层是一致的,不会出现脏读的现象,因为还未做引擎层的提交。
由此可见,增强半同步才是真正的无损复制,相对于普通半同步而言的确更加有效地保证了数据的一致性。确切地说是避免了应用层的不一致,避免了脏读的发生。
1. 第一种情况,日志丢失,主从切换
不管是增强半同步、还是普通半同步,如果出现日志未同步到备库的,或备库接收后未写入relay log,且这个时候发生主从切换就会导致日志丢失。如果不切换,主库启动后依然可以把之前的日志再次发送到备库并应用,也就不会出现数据不一致的现象。
所以出现主从数据不一致要具备2个条件:1)主库日志未同步到备库;2)同时发生主从切换。
举例:
应用客户端向主库发起请求Insert into t1 values(100);插入一条记录Commit;开始提交,如果这个时候网络中断,日志未发送到备库,也就无法接收备库的ACK返回确认信息,于是提交无法进行,处于hang状态。这个时候如果主库宕机,就会发生主从切换。
应用客户端也会出现报错,记录未插入成功,新的主库同样也没有这条记录,应用客户端连接新的主库后,重新发起一次请求,再次插入这条记录,应用逻辑没有破坏,就是所说的应用层数据是一致的。增强半同步是可以保证应用的数据的一致性。
但此时会出现数据库端的不一致,当原主库再次启动后,会跳过ACK验证,对PendingBinlog进行引擎层面的提交,所以启动后原主库就会存在这条记录,而新主库并没有这条记录,就造成了数据库层面的不一致。
当应用连接新主库再次执行这条记录时,把这条记录发送给原主库,如果是主键就会报错或出现重复数据。这种情况发生时我们一般会对原主库进行处理后再建立复制关系。
由于篇幅问题本文不作展开,请参见下面的链接,模拟不一致的处理方法:
2. 第二种情况,日志未丢失,主从未切换
主库因为无法返回接收到备库的ACK信息而无法提交,这个时候主库宕机,如果主库启动后不切换,主库可以正常启动,那么这条记录同样会被提交。而应用层的反应是异常,该条记录并未成功,那么会出现应用层的不一致,应用层的不一致是比较麻烦的,这个时候需要2种解决方法:
1)让应用确认该记录已经正常插入,无需重复执行;
2)数据库删除该记录,应用重新执行。
主库等待ACK返回的默认时间是60s,超过60s会降级成异步并提交事务。有的时候因为网络问题从库一直没有响应,为了确保主库可用性,我们会牺牲一致性的要求,这个是符合我们生产场景的。对一致性要求极高的环境下会将ACK返回时间设置的无限大,这样就会影响可用性,但保证了最终的一致性。
有一种极端情况下,会出现数据层和应用层的数据不一致,如下图:
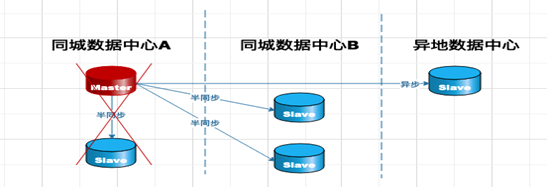
在一主多从的情况下rpl_semi_sync_master_wait_for_slave_count 设置为1,同城数据中心A机房的从库首先接收到日志并返回ACK给主库,主库就可以正常提交,如果同城数据中心A的主库和从库均出现宕机现象,而这个时候日志均未发送给数据库中心B、异地中心的从库,并且发生了主从切换,那么同城数据中心B、异地数据中心就会在数据层和应用层均出现和原主库数据不一致的现象。
1)可以在同城数据中心A增加从库数量,并增加
2)不增加设备,增加rpl_semi_sync_master_wait_for_slave_count的值,确保同城数据中心B的从库接收并返回ACK主库再提交,但这样会对性能有一些影响,取决于网络延迟和稳定度。
普通半同步会出现数据层和应用层的数据不一致,所以普通半同步在生产中是不建议使用的。5.7以后增强半同步是默认的。5.6版本只能采用普通半同步的方式,但相比较异步复制,在保证数据一致性上也是很大的进步。
不管是after commit和after sync ,只要发生日志未发送到从库,或从库未接收,且这个时候发生主从切换,都会出现数据不一致的情况。增强半同步真正解决的是应用层的不一致,即不同会话的脏读问题。
那么,究竟该如何避免数据不一致的情况呢?既然我们已经了解了发生不一致的各种条件,那么只要尽量避免这些条件的发生就可以了:
1)增加从库数量,增大rpl_semi_sync_master_wait_for_slave_count的值。
2)使用第三方插件MHA、keepalived设置主库切换策略,当发生宕机后不马上切换,尝试N次重启后再切换,另外从库提升为主库后尝试从原主库拉取日志补齐(系统正常,MySQL数据库无法启动的情况)。
3)使用成熟的开源或商业软件,这些产品都有成熟的切换策略、数据校验和补齐机制。
4)采用较高版本的MySQL数据库产品,至少5.7及以上,启用增强半同步。
5)回退掉PendingBinlog,个人认为官方应该完善自动回退PendingBinlog的功能。
6)双1参数,ROW格式,开启gtid。
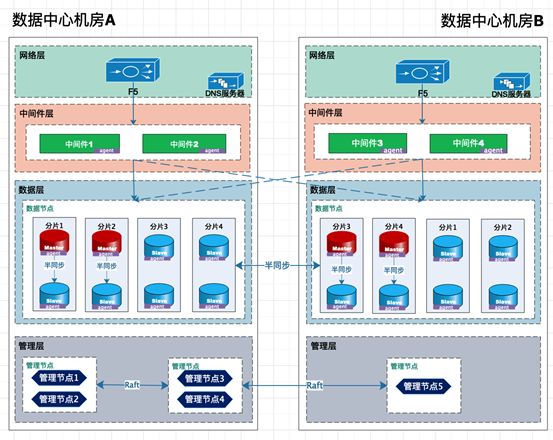
下图为某银行信息系统的实际案例,数据库版本为MYSQL5.7,采用了以下措施提高数据一致性保障。
1. 采用了一主三从模式,其中一个主库和一个从库在A机房,另两个从库在同城B机房;
2. 采用了增强半同步,rpl_semi_sync_master_wait_for_slave_count参数设置为1,即只要有一个从库返回成功,主库即可提交;
3. 采用了国产成熟数据库管理软件,该软件在数据一致性上提供成熟的切换策略、数据校验和补齐机制功能。
由于篇幅有限,笔者将在下一篇文章将介绍MGR是如何保证数据复制的一致性的。
参考文献:
MySQL官方手册(5.7,8.0)
MySQL运维内参
https://blog.csdn.net/xihuanyuye/article/details/81220524
https://cloud.tencent.com/developer/article/1042773
https://www.linuxidc.com/Linux/2018-04/151851.htm
