




这是"大内存服务GC实践"的第三篇文章,前面两篇文章分别系统地介绍了"ParNew+CMS"组合垃圾回收器的原理以及FullGC的一些排查思路。分别见:
【大内存服务GC实践】- 一文看懂”ParNew+CMS”垃圾回收器
【大内存服务GC实践】- “ParNew+CMS”实践案例 : HiveMetastore FullGC诊断优化
本篇文章重点结合生产线上NameNode RPC毛刺这个现象,分析两起严重的YGC问题。NameNode是HDFS服务最核心的组件,大数据任务读写文件都需要请求NameNode,该服务一旦出现RPC处理毛刺,就可能会引起上层大数据平台离线、实时任务的延迟甚至异常。公司内部NameNode采用"ParNew+CMS"组合垃圾回收器。
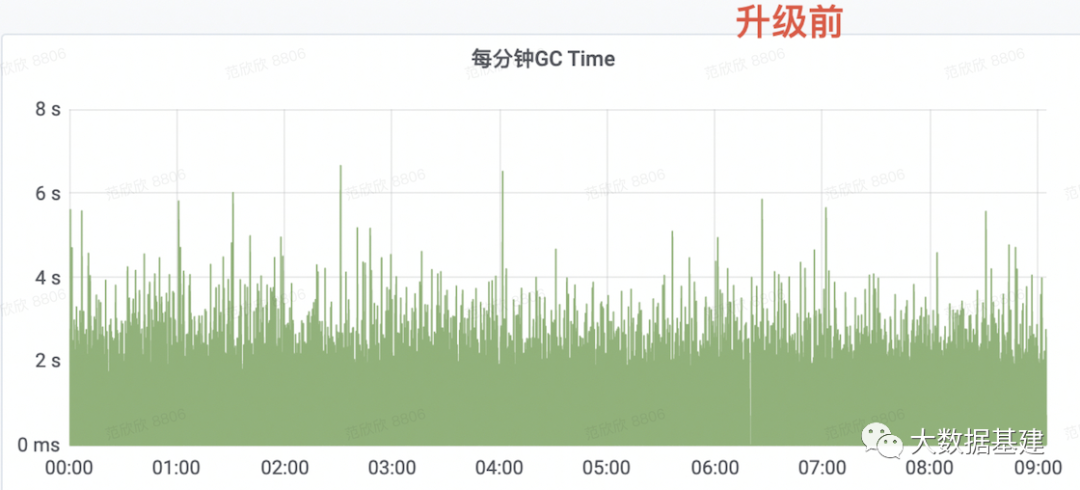
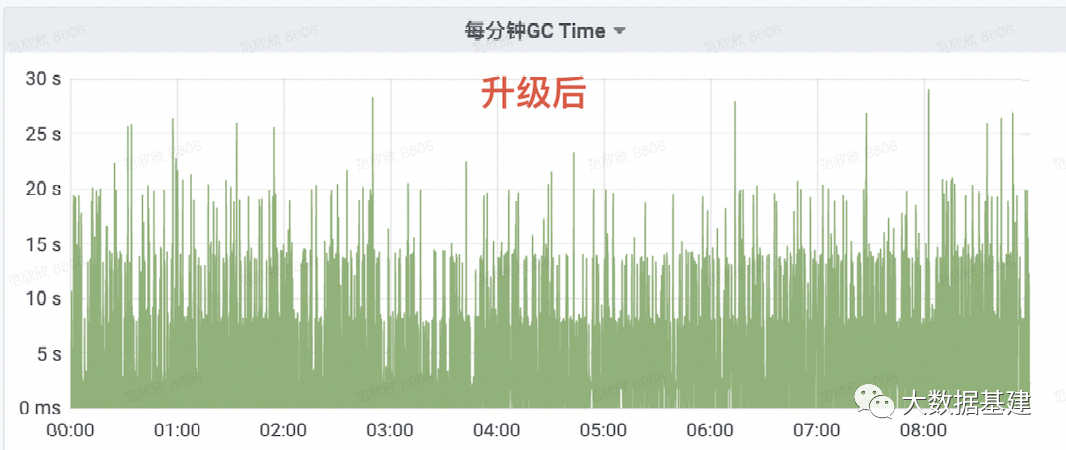
案例一 NameNode升级之后RPC大毛刺问题探究
问题背景
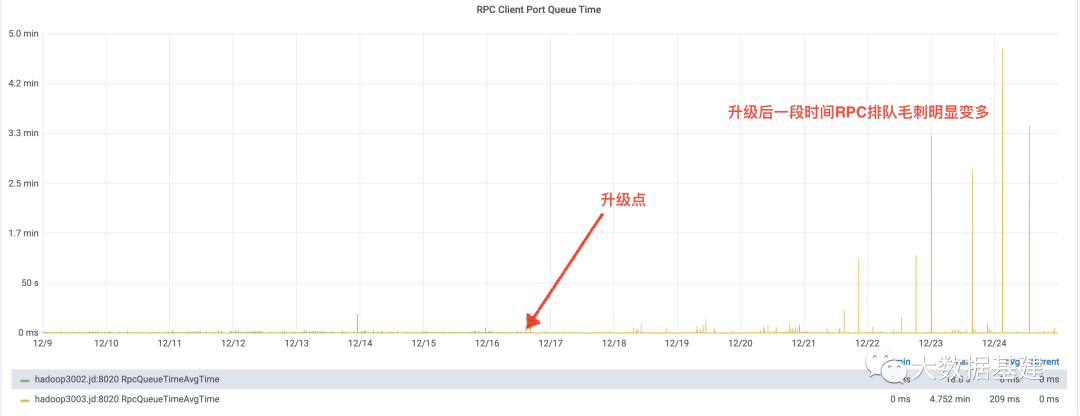
问题分析
为什么RPC排队毛刺会出现?
大规模文件删除导致NameNode卡住。 大目录getContentSummary接口调用。 大GC影响。
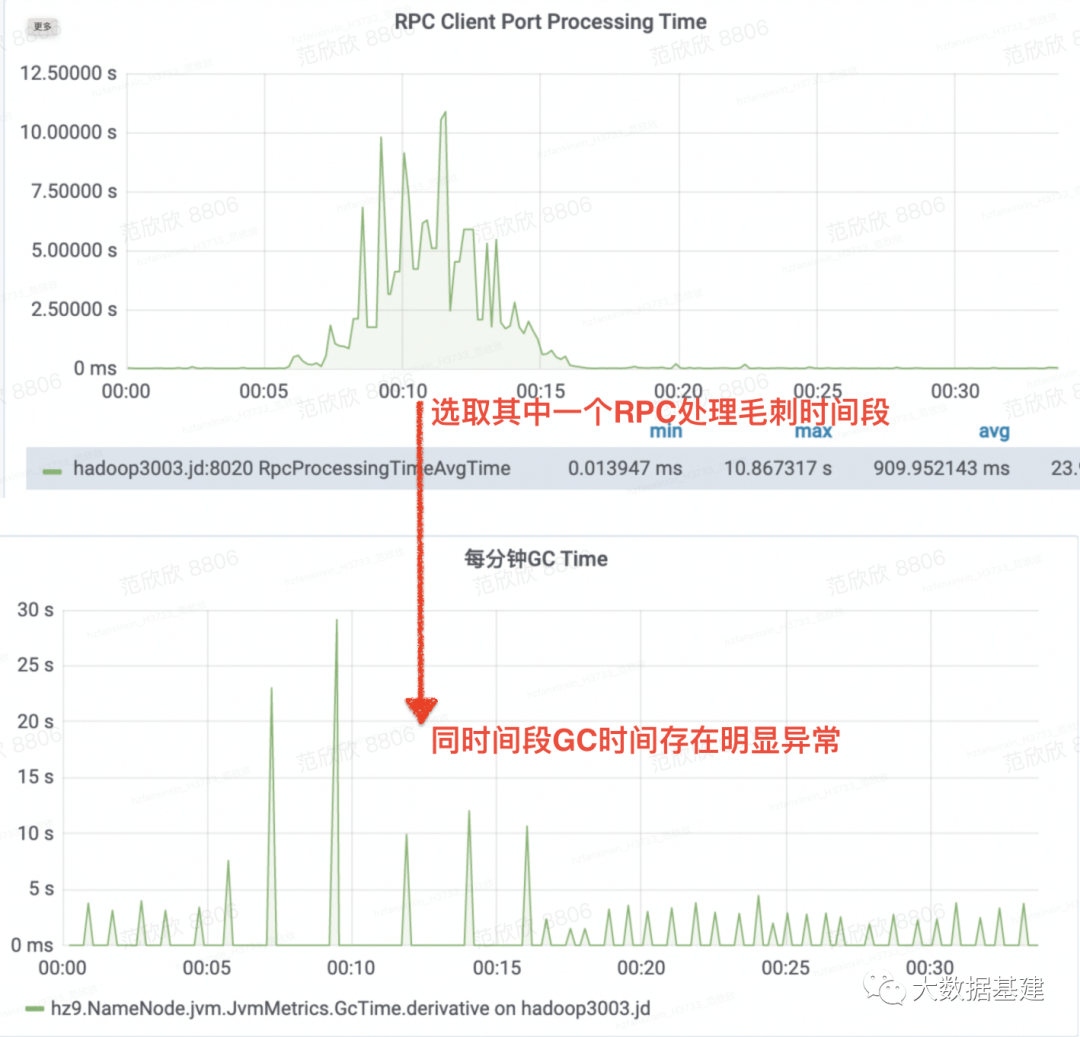
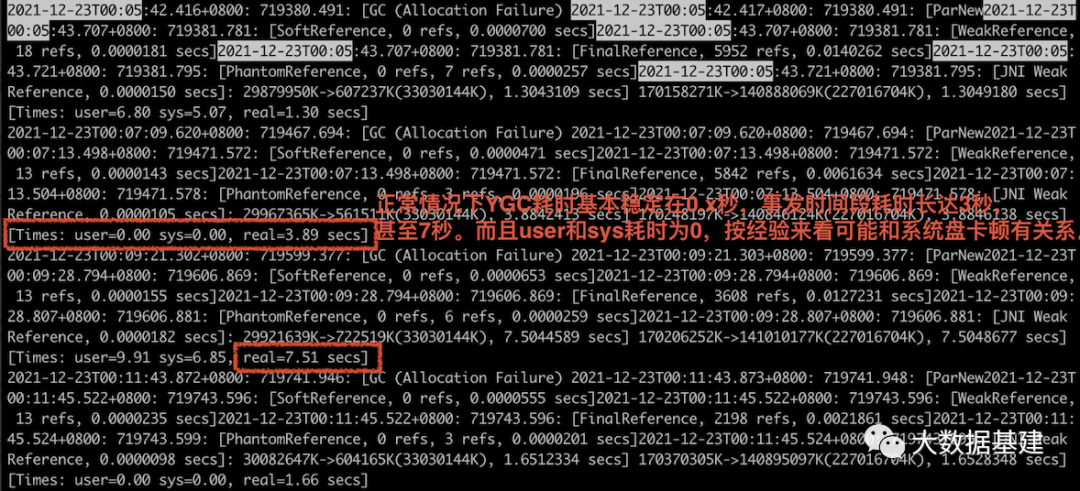
为什么YGC耗时卡顿这么长时间?
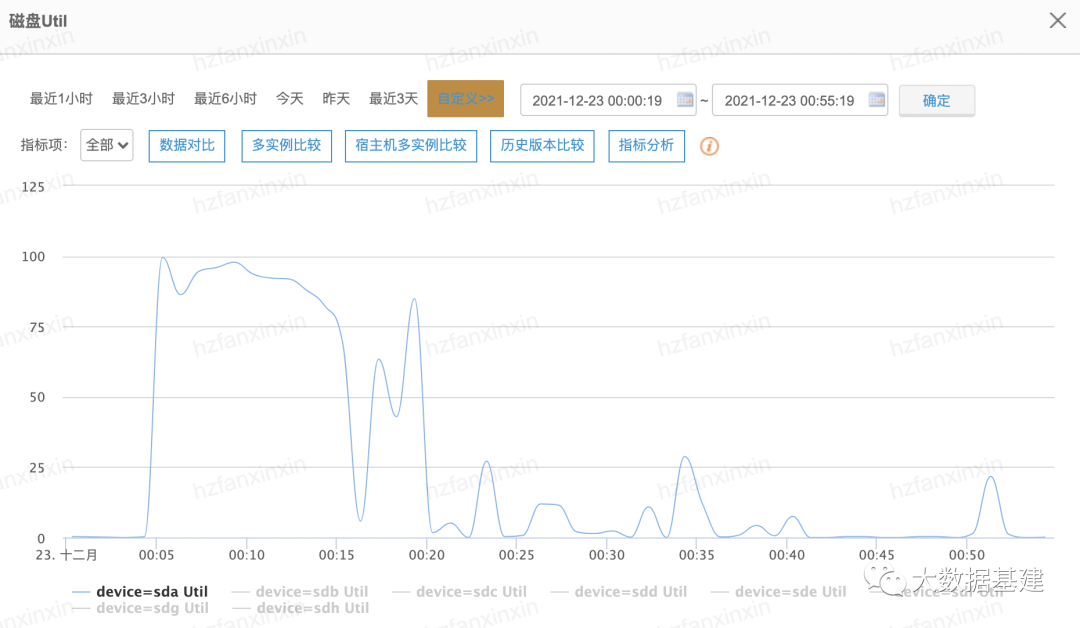
为什么系统盘IO会被打满?
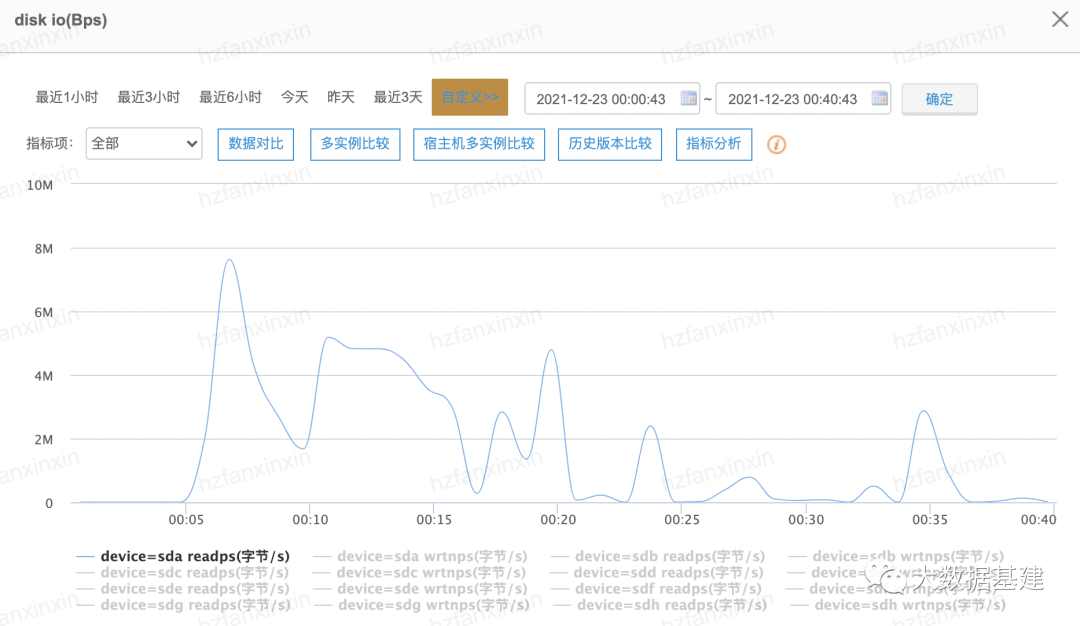
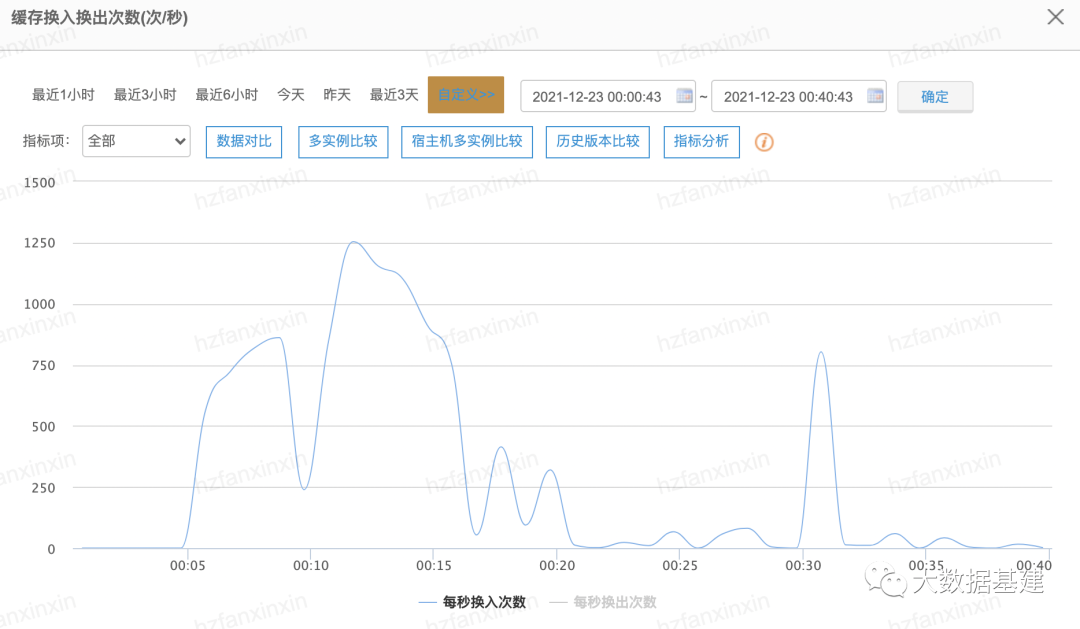
为什么新版本上线后会频繁触发缓存换入呢?
案例二. Ranger插件升级之后NameNode RPC大毛刺问题探究
问题背景
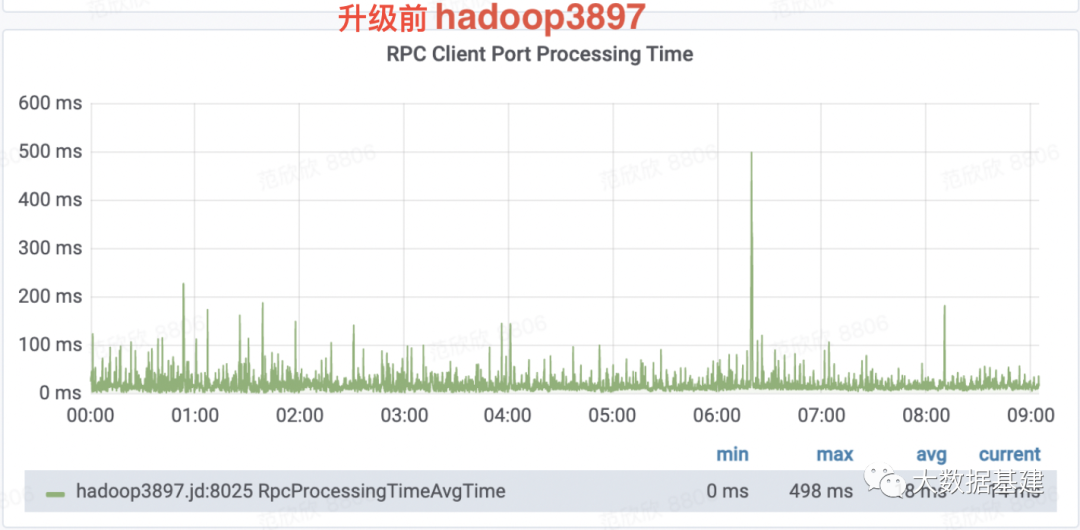
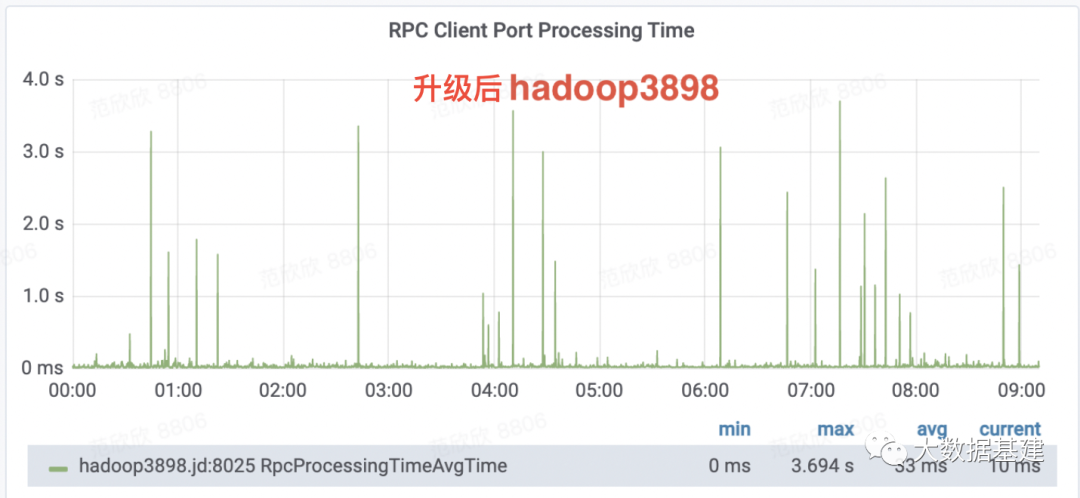
问题分析
为什么PRC处理毛刺会出现?
Desired survivor size 5368709120 bytes, new threshold 15 (max 15)- age 1: 845855096 bytes, 845855096 total- age 2: 315664752 bytes, 1161519848 total- age 3: 6367320 bytes, 1167887168 total- age 4: 389355792 bytes, 1557242960 total- age 5: 9163192 bytes, 1566406152 total- age 6: 37404216 bytes, 1603810368 total- age 7: 930872 bytes, 1604741240 total- age 12: 96928 bytes, 1604838168 total- age 15: 3352 bytes, 1604841520 total: 42842835K->1874036K(52428800K), 3.3199043 secs] 458215362K->417246566K(618659840K), 3.3203978 secs][Times: user=15.94 sys=3.41, real=3.32 secs]
2021-11-17T18:33:09.820+0800: 179227.136: [Rescan (parallel) , 0.4236529 secs]2021-11-17T18:33:10.244+0800: 179227.560: [weak refs processing, 93.3276296 secs]2021-11-17T18:34:43.571+0800: 179320.888: [class unloading, 0.0895056 secs]2021-11-17T18:34:43.661+0800: 179320.977: [scrub symbol table, 0.0107147 secs]2021-11-17T18:34:43.671+0800: 179320.988: [scrub string table, 0.0025554 secs][1 CMS-remark: 415575980K(566231040K)] 416281199K(618659840K), 94.1390159 secs][Times: user=107.70 sys=10.29, real=94.14 secs]至此基本可以确认NameNode请求延迟毛刺是因为Ranger升级之后导致NameNode进程YGC
频率增多,且单次耗时增多导致。
为什么YGC和CMS GC Remark耗时变长了呢?
2021-11-17T18:33:10.244+0800: 179227.560: [weak refs processing, 93.3276296 secs]...2021-11-17T18:34:43.671+0800: 179320.988: [scrub string table, 0.0025554 secs][1 CMS-remark: 415575980K(566231040K)] 416281199K(618659840K), 94.1390159 secs][Times: user=107.70 sys=10.29, real=94.14 secs]
为什么weak refs processing耗时这么长?
2022-01-17T14:51:26.616+0800: 2061.131: [GC (Allocation Failure)2022-01-17T14:51:26.617+0800: 2061.131: [ParNew2022-01-17T14:51:27.115+0800: 2061.630: [SoftReference, 0 refs, 0.0000930 secs]2022-01-17T14:51:27.115+0800: 2061.630: [WeakReference, 156 refs, 0.0000494 secs]2022-01-17T14:51:27.115+0800: 2061.630: [FinalReference, 1348 refs, 10.2301307 secs]2022-01-17T14:51:37.345+0800: 2071.860: [PhantomReference, 0 refs, 95 refs, 0.0000758 secs]2022-01-17T14:51:37.346+0800: 2071.860: [JNI Weak Reference, 0.0000177 secs]: 52844281K->5134129K(53476800K), 10.7291830 secs] 90304049K->43584416K(172316096K), 10.7294849 secs][Times: user=20.36 sys=0.17, real=10.73 secs]
为什么Ranger插件升级之后会导致FinalReference处理耗时变长?
[arthas@42668]$ sm org.apache.* finalize -n 10000org.apache.hadoop.hdfs.protocol.RollingUpgradeInfo finalize(J)Vorg.apache.ranger.plugin.policyengine.PolicyEngine finalize()Vorg.apache.ranger.plugin.policyengine.RangerPolicyRepository finalize()Vorg.apache.ranger.plugin.contextenricher.RangerAbstractContextEnricher finalize()Vorg.apache.log4j.AppenderSkeleton finalize()V
protected void finalize() throws Throwable {try {/*120*/ this.cleanup();}finally {/*122*/ super.finalize();}}
文章总结
文章转载自大数据基建,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
