





学习 探索 分享数据库前沿知识和技术 共建数据库技术交流圈
上篇图文,我们分享了AI技术——智能索引推荐的相关精彩内容,本篇将详细介绍AI技术——指标采集、预测与异常检测的相关内容。
8.5 指标采集、预测与异常检测
8.5.1 使用场景
8.5.2 实现原理
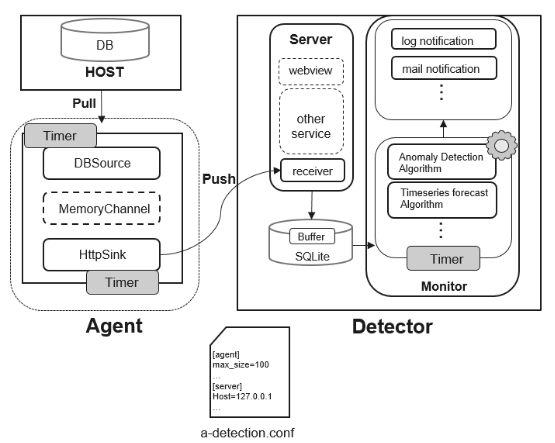
图1 Anomaly-Detection框架
(1) 收集Agent端采集的数据并进行转储。
(2) 对收集到的数据进行特征分析与异常检测。
(3) 将检测出来的异常信息推送给运维管理人员。
1. Agent模块的组成
(1) DBSource作为数据源,负责定期去收集数据库指标数据并将数据发送到数据通道MemoryChannel中。
(2) MemoryChannel是内存数据通道,本质是一个FIFO队列,用于数据缓存。HttpSink组件消费MemoryChannel中的数据,为了防止MemoryChannel中的数据过多导致OOM(out of Memory,内存溢出),设置了容量上限,当超过容量上限时,过多的元素会被禁止放入队列中。
(3) HttpSink是数据汇聚点,该模块定期从MemoryChannel中获取数据,并以Http(s)的方式将数据进行转发,数据读取之后从MemoryChannel中清除。
2. Detector 模块组成
(1) Server是一个Web服务,为Agent采集到的数据提供接收接口,并将数据存储到本地数据库内部,为了避免数据增多导致数据库占用太多的资源,我们将数据库中的每个表都设置了行数上限。
(2) Monitor模块包含时序预测和异常检测等算法,该模块定期从本地数据库中获取数据库指标数据,并基于现有算法对数据进行预测与分析,如果算法检测出数据库指标在历史或未来某时间段或时刻出现异常,则会及时的将信息推送给用户。
8.5.3 关键源码解析
1. 总体流程解析
def forecast(args):…# 如果没有指定预测方式,则默认使用’auto_arima’算法if not args.forecast_method:forecast_alg = get_instance('auto_arima')else:forecast_alg = get_instance(args.forecast_method)# 指标预测功能函数def forecast_metric(name, train_ts, save_path=None):…forecast_alg.fit(timeseries=train_ts)dates, values = forecast_alg.forecast(period=TimeString(args.forecast_periods).standard)date_range = "{start_date}~{end_date}".format(start_date=dates[0],end_date=dates[-1])display_table.add_row([name, date_range, min(values), max(values), sum(values) / len(values)])# 校验存储路径if save_path:if not os.path.exists(os.path.dirname(save_path)):os.makedirs(os.path.dirname(save_path))with open(save_path, mode='w') as f:for date, value in zip(dates, values):f.write(date + ',' + str(value) + '\n')# 从本地sqlite中抽取需要的数据with sqlite_storage.SQLiteStorage(database_path) as db:if args.metric_name:timeseries = db.get_timeseries(table=args.metric_name, period=max_rows)forecast_metric(args.metric_name, timeseries, args.save_path)else:# 获取sqlite中所有的表名tables = db.get_all_tables()# 从每个表中抽取训练数据进行预测for table in tables:timeseries = db.get_timeseries(table=table, period=max_rows)forecast_metric(table, timeseries)# 输出结果print(display_table.get_string())# 代码远程部署def deploy(args):print('Please input the password of {user}@{host}: '.format(user=args.user, host=args.host))# 格式化代码远程部署指令command = 'sh start.sh --deploy {host} {user} {project_path}' \.format(user=args.user,host=args.host,project_path=args.project_path)# 判断指令执行情况if subprocess.call(shlex.split(command), cwd=SBIN_PATH) == 0:print("\nExecute successfully.")else:print("\nExecute unsuccessfully.")…# 展示当前监控的参数def show_metrics():…# 项目总入口def main():…
2. 关键代码段解析
(1) 后台线程的实现。
class Daemon:"""This class implements the function of running a process in the background."""def __init__(self):…def daemon_process(self):# 注册退出函数atexit.register(lambda: os.remove(self.pid_file))signal.signal(signal.SIGTERM, handle_sigterm)# 启动进程@staticmethoddef start(self):try:self.daemon_process()except RuntimeError as msg:abnormal_exit(msg)self.function(*self.args, **self.kwargs)# 停止进程def stop(self):if not os.path.exists(self.pid_file):abnormal_exit("Process not running.")read_pid = read_pid_file(self.pid_file)if read_pid > 0:os.kill(read_pid, signal.SIGTERM)if read_pid_file(self.pid_file) < 0:os.remove(self.pid_file)
(2) 数据库相关指标采集过程。
def agent_main():…# 初始化通道管理器cm = ChannelManager()# 初始化数据源source = DBSource()http_sink = HttpSink(interval=params['sink_timer_interval'], url=url, context=context)source.channel_manager = cmhttp_sink.channel_manager = cm# 获取参数文件里面的功能函数for task_name, task_func in get_funcs(metric_task):source.add_task(name=task_name,interval=params['source_timer_interval'],task=task_func,maxsize=params['channel_capacity'])source.start()http_sink.start()
(3) 数据存储与监控部分的实现。
# 通过时间戳获取最近一段时间的数据def select_timeseries_by_timestamp(self, table, period):…# 通过编号获取最近一段时间的数据def select_timeseries_by_number(self, table, number):…
class AlgModel(object):"""This is the base class for forecasting algorithms.If we want to use our own forecast algorithm, we should follow some rules."""def __init__(self):pass@abstractmethoddef fit(self, timeseries):pass@abstractmethoddef forecast(self, period):passdef save(self, model_path):passdef load(self, model_path):pass
8.5.4 使用示例
模式名称 | 说明 |
start | 启动本地或者远程服务 |
stop | 停止本地或远程服务 |
forecast | 预测指标未来变化 |
show_metrics | 输出当前监控的参数 |
deploy | 远程部署代码 |
python main.py start –role collector
python main.py stop –role collector
python main.py start --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
python main.py stop --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
python main.py show_metrics
python main.py forecast –metric-name io_read –forecast-periods 60S –save-path predict_result
python main.py deploy –user xxx –host xxx.xxx.xxx.xxx –project-path xxx
8.5.5 演进路线
(1) Agent模块收集数据太单一。目前Agent只能收集数据库的资源指标数据,包IO、磁盘、内存、CPU等,后续还需要在采集指标丰富度上作增强。
(2) Monitor内置算法覆盖面不够。Monitor目前只支持两种时序预测算法,同时针对异常检测额,也仅支持基于阈值的简单情况,使用的场景有限。
(3) Server仅支持单个Agent传输数据。Server目前采用的方案仅支持接收一个Agent传过来的数据,不支持多Agent同时传输,这对于只有一个主节点的openGauss数据库暂时是够用的,但是对分布式部署显然是不友好的。
以上内容为AI技术中指标采集、预测与异常检测的详细介绍,下篇图文将分享“AI查询时间预测”的相关内容,敬请期待!


最后修改时间:2022-02-24 18:40:19
文章转载自Gauss松鼠会,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
