




2022.1.18 Oracle DG服务器扩容,cpu从8核扩到32核,内存从32G扩到64G。
2022.1.19 发现zabbix告警了,会话数超过20
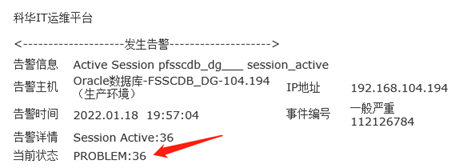
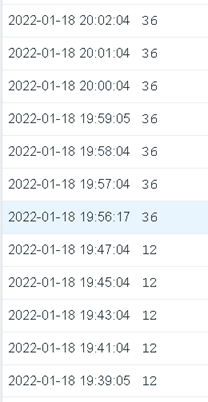
通过zabbix触发器得到语句:
select * from v$session where
TYPE!='BACKGROUND' and status='ACTIVE';
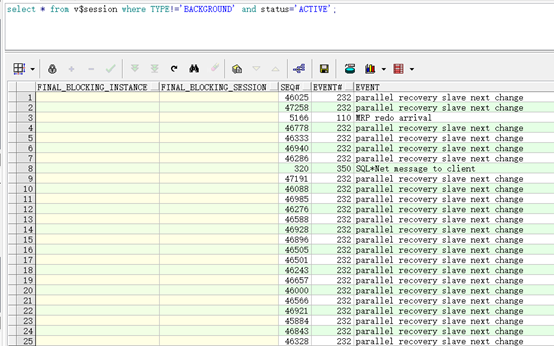
为啥这么多parallel recovery salve next change
情急之下,杀了一个进程alter system kill session '1,2';
结果,所有的parallel recovery salve next change,全没了。告警消息。
总觉得不对劲。一看alert日志,发现
Errors in file
/u01/app/oracle/diag/rdbms/fsscdbadg/fsscdbadg/trace/fsscdbadg_pr00_18560.trc:
ORA-00448: normal completion of background
process
Managed Standby Recovery not using Real
Time Apply
Recovery interrupted!
Recovered data files to a consistent state
at change 10250462820644
MRP0: Background Media Recovery process
shutdown (fsscdbadg)
Wed Jan 19 09:26:48 2022
RFS[2]: Selected log 15 for thread 2
sequence 15579 dbid 180716809 branch 1029837451
在主库测试表插入一条数据,到备库一查,发现不同步了。
重启实例看看呢
shutdown immediate;
startup mount;
alter database open read only;
alter database recover managed standby
database using current logfile disconnect;
parallel recovery slave next change 到底是啥?

大概明白了,应该就是dg的recovery进程,都处于待命状态,因为cpu扩容了,所以,相应地分配更多的进程了
去ERP的DG库,试了一下:
select count(0) from v$session where TYPE!='BACKGROUND' and status='ACTIVE' and event = 'parallel recovery slave next change';
答案是15个,看来我的猜测应该没错了。
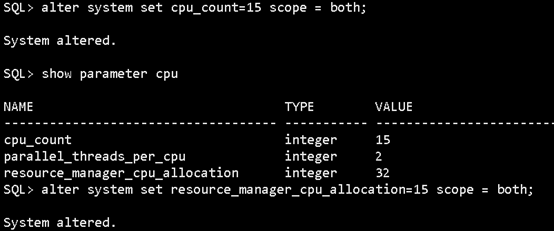
接下来就是把oracle的cpu_count改小一些:
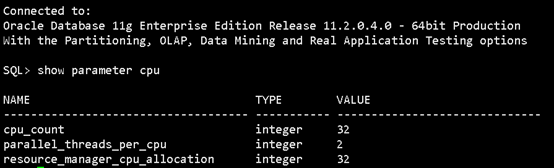
alter system set cpu_count=15
scope = both;
alter system set resource_manager_cpu_allocation=15
scope = both;
shutdown immediate;
startup mount;
alter database open read only;
alter database recover managed standby
database using current logfile disconnect;

一个报错非常显眼,他的提示是有些过期的参数正在使用。查看过期参数:
估计过期参数就是resource_manager_cpu_allocation;
这个参数应该是不用改的。
很快,收到zabbix恢复的消息了。
年前发生的事了,没空整理。今天初八,新年第一贴,请多支持!
