




一. 安装前的准备工作
| 序号 | 步骤名称 | 步骤内容 |
|---|---|---|
| 1 | 硬件环境检查 | 检查硬件环境是否满足数据库安装要求 |
| 2 | 软件依赖检查 | 检查软件是否满足数据库安装要求 |
| 3 | 介质检查 | 检查数据库安装包准备情况 |
| 4 | License检查 | 检查license准备情况 |
1.1 安装系统环境检查
[root@localhost ~]# lsb_release -a //查看操作系统

[root@localhost ~]# getconf LONG_BIT // 查看操作系统位数

[root@localhost ~]# rpm -aq|grep glibc //查看包

[root@localhost ~]# cat /proc/cpuinfo //查看cpu
[root@localhost ~]# cat /proc/cpuinfo | grep -E “physical id|core id|cpu cores|siblings|cpu MHz|model name|cache size”|tail -n 7
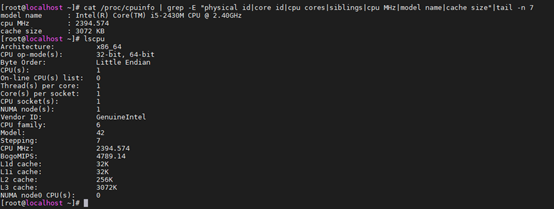
[root@localhost ~]# fdisk -l //查看磁盘信息
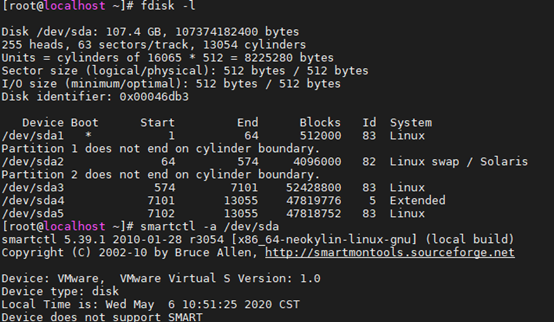
[root@localhost ~]# df -h //查看空间大小
[root@localhost ~]# free –g //查看内存大小

1.2 申请匹配的版本
根据以上硬件和操作系统平台信息找达梦商务人员申请匹配的版本,或达梦官网下载开发版进行学习测试。
http://www.dameng.com/
二. 安装前规划工作
2.1 安装路径
根据数据库服务器配置规划安装路径、数据路径、备份路径。
安装路径:建议放在本地盘
数据路径:建议放在存储性能最好的地方,如磁盘阵列的挂载点下
归档路径:建议放在数据路径下,避免误删
备份路径:建议放在和数据不同的盘上
2.2 规划数据库初始化参数
达梦数据库初始化实例后初始化参数无法修改,如果要调整必须重新初始化库,所以为 了移植、开发、维护的方便,根据应用特征合理规划初始化参数尤为重要,确定后形成安装 规范项目组成员保持一致,如果初始化参数不一致不同库间的物理备份、逻辑备份将不能还原,切记下面对一些重要的初始化参数进行详细说明:
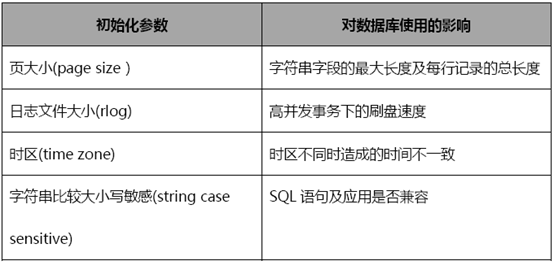
2.2.1 页大小
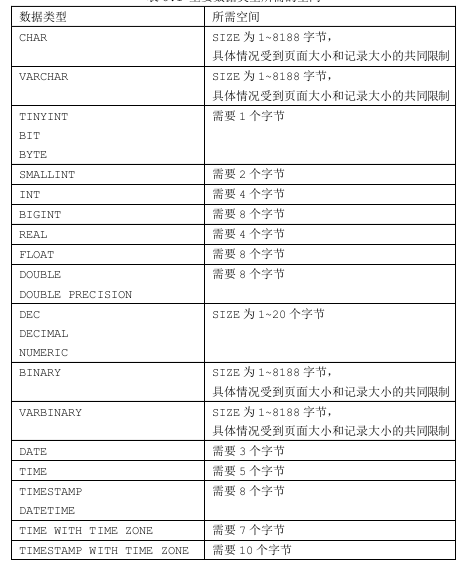
在 DM 数据库中,页大小可以为 4KB、8KB、16KB 或者 32KB,用户在创建数据库时可以指定,默认大小为 8KB,一旦创建好了数据库,在该库的整个生命周期内,页大小都不能够改变。页大小对字符数据类型实际最大长度及每行记录的影响如下表所示(不同的数据库版本略有差异):

除了每个字段的最大长度限制外,每条记录总长度不能大于页面大小的一半。如果系统中存在或者以后可能存在含有较长的字符串类型的表,建议该参数设置为16或者32.
2.2.2 曰志文件大小
每个DM数据库实例必须至少有2个重做日志文件,默认两个日志文件为 DAMENG01.log、DAMENG02.log ,这两个文件循环使用,日志文件在初始化实例后可以增加和扩大,小型OA系统建议设置为2个256M在线大型交易系统建议设置为4个2048M。
2.2.3 时区
选择时区前需要确认操作系统时区和数据库时区相同以避免时间差异,建议使用北京时间+ 8:00。
2.2.4 字符串比较大小写敏感
达梦为了兼容不同的数据库,在初始化数据库的时候有一个参数字符串比较大小写敏感,用于确定数据库对象及数据是否区分大小写,默认为区分,不可更改。建议MYSQL 和SQLSERVER迁移过来的系统,使用大小写不敏感,ORACLE迁移过来的系统,使用大小写敏感,以便和原来系统匹配。
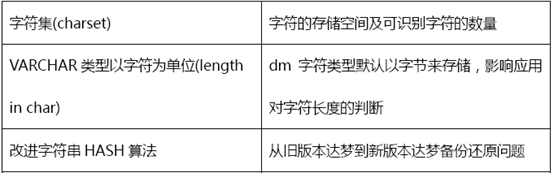
2.2.5 字符集
建议采用默认值GB18030 ,如果需要国际字符可以采用Unicode , GB18030数字字母占1个字节,普通汉字占2个字节,部分繁体及少数民族文字占4字节,Unicode在达 梦中采用UTF-8编码格式,欧洲的字母字符占1到2个字节,亚洲的大部分字符占3个字 节,附加字符为4个字节。如果只存储中文和字母数字,一般来说GB18030更节省空间。
下面是这四种字符集的包括关系:GB2312 < GBK < GB18030 < UTF8
2.2.6 修改主机名称
hostname 用于临时修改主机名;
/etc/sysconfig/network用于本地主机名永久生效;
/etc/hosts/用于网络中主机名永久生效
[root@localhost ~]# more /etc/sysconfig/network
[root@localhost ~]# more /etc/hosts
2.2.7 操作系统参数配置
2.2.7.1 配置操作系统LIMITS
[root@localhost network-scripts]# more /etc/security/limits.conf
添加如下:
dmdba soft fsize unlimited
dmdba hard fsize unlimited
dmdba soft nproc 131072
dmdba hard nproc 131072
dmdba soft nofile 131072
dmdba hard nofile 131072
dmdba soft core unlimited
dmdba hard core unlimited
dmdba soft data unlimited
dmdba hard data unlimited
2.2.7.2 配置操作系统内核参数
[root@localhost network-scripts]# more /etc/sysctl.conf
cat >>/etc/sysctl.conf <<EOF
##############操作系统信号量
kernel.sem = 50100 64128000 50100 1280
##############释放time_wait链接
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
#net.ipv4.tcp_tw_recycle = 1
#net.ipv4.tcp_tw_timestamps=1
net.ipv4.tcp_fin_timeout = 30
##############TCP端口使用范围
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.ip_local_port_range = 10000 65000
net.ipv4.tcp_max_syn_backlog = 8192
net.ipv4.tcp_max_tw_buckets = 6000
##############记录的那些尚未收到客户端确认信息的连接请求的最大值
net.ipv4.tcp_max_syn_backlog = 65536
############每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目
net.core.netdev_max_backlog = 32768
net.core.wmem_default = 8388608
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syn_retries = 2
net.ipv4.route.gc_timeout = 100
net.ipv4.tcp_wmem = 8192 436600 873200
net.ipv4.tcp_rmem = 32768 436600 873200
net.ipv4.tcp_mem = 94500000 91500000 92700000
net.ipv4.tcp_max_orphans = 3276800
EOF
配置后sysctl -p 重新加载生效(查看是否有错误,有错误的重新修正注销掉)
2.2.8 检查时间和时区
[root@localhost ~]# date
[root@localhost ~]# date -s “20200607 12:00:00”
2.2.9 规划用户并修改密码
[root@localhost ~]# groupadd dinstall
[root@localhost ~]# useradd -g dinstall -m -d /home/dmdba -s /bin/bash dmdba
[root@localhost ~]# passwd dmdba
2.2.10 创建DM_HOME
[root@localhost ~]# mkdir /dm7
[root@localhost ~]# chown -R dmdba:dinstall /dm7
2.2.11 设置用户环境变量
[dmdba@localhost ~]$ vim /home/dmdba/.bash_profile
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/dm7/bin"
export DM_HOME="/dm7"
export PATH=$DM_HOME/bin:$DM_HOME/tool:$PATH:$HOME/bin
[dmdba@localhost ~]$ source /home/dmdba/.bash_profile
三. 安装达梦数据库
3.1 安装软件
[root@localhost xiaoke]# mount -o loop -t iso9660 dm7_setup_rh6_64_ent_20180717.iso /mnt
[root@localhost xiaoke]# su - dmdba
[dmdba@localhost ~]$ /mnt/DMInstall.bin -i
[root@localhost ~]# /dm7/script/root/root_installer.sh
3.2 初始化数据库
[dmdba@dbserver ~]$ dminit path=/dm7/data/ PORT_NUM=5236 UNICODE_FLAG=0 PAGE_SIZE=16 EXTENT_SIZE=16 CASE_SENSITIVE=1
3.3 实例注册及自动启动设置
[root@localhost root]# cd /dm7/script/root
[root@localhost root]# ./dm_service_installer.sh -t dmserver -i /dm7/data/DAMENG/dm.ini -p DAMENG
[root@localhost root]# chkconfig --list |grep Dm
[root@localhost root]# service DmServiceDAMENG status
[root@localhost root]# service DmServiceDAMENG start
四. 数据库常规创建
4.1 创建表空间
表空间是由一个或多个数据文件构成的,表空间是数据库的一个容器,存放数据库中的数据对象(表,索引等)。
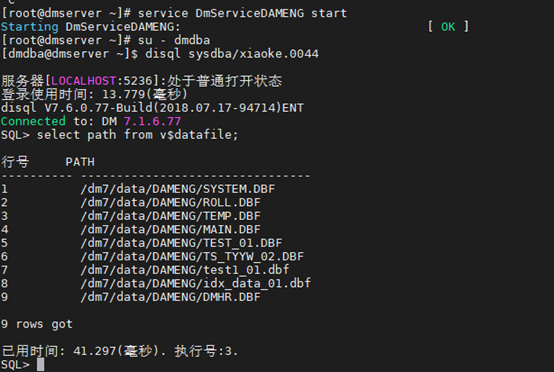
[dmdba@localhost ~]$ disql sysdba/xiaoke.0044@127.0.0.1:5236
SQL> select tablespace_name,status from dba_tablespaces;

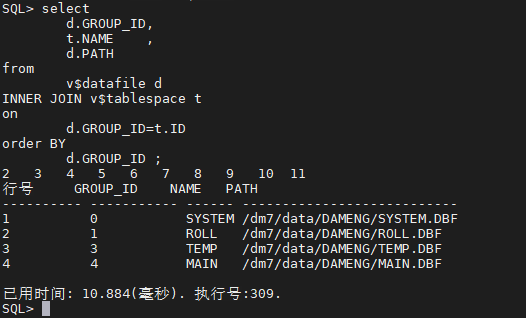
System:数据字典和全局的系统数据。
Roll:存放了数据库运行过程中产生的回滚记录。
Temp:临时表空间
Main:数据库默认表空间,创建数据对象的时候,如果不指定存放的位置,默认存放在该表空间。
HMAIN:huge表空间
#数据表空间
SQL> select path,CLIENT_PATH,CREATE_TIME from v$datafile;
SQL> CREATE TABLESPACE TS_TYY DATAFILE ’ TS_TYY_01.DBF’ SIZE 50 autoextend on maxsize 10240;
SQL> ALTER TABLESPACE TS_TYY ADD DATAFILE ‘TS_TYY_02.DBF’ SIZE 50 autoextend on maxsize 10240;
#undo表空间
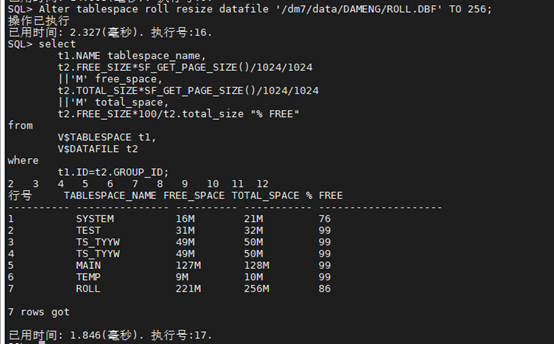
SQL> select path,CLIENT_PATH,CREATE_TIME, TOTAL_SIZE from v$datafile;
SQL> Alter tablespace roll resize datafile ‘/dm7/data/DAMENG/ROLL.DBF’ TO 256;
4.2 删除表空间
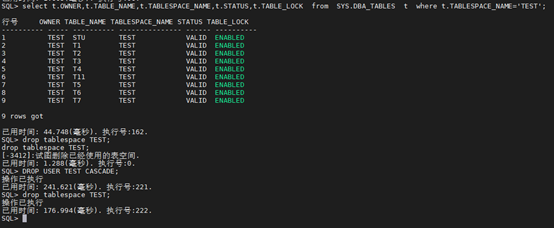
SQL> drop tablespace TEST;

SQL> select t.OWNER,t.TABLE_NAME,t.TABLESPACE_NAME,t.STATUS,t.TABLE_LOCK from SYS.DBA_TABLES t where t.TABLESPACE_NAME=‘TEST’;
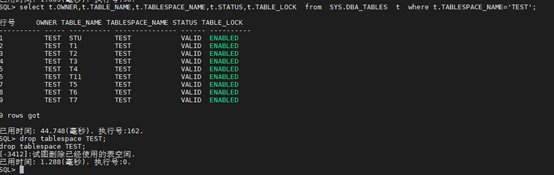
SQL> DROP USER TEST CASCADE;
SQL> drop tablespace TEST;
4.3 用户管理
在dm数据库中用户管理主要涉及到三块:用户,权限,角色
权限:执行特定类型sql或是访问其他模式对象的权利。
系统权限:数据库对象的创建,删除,修改等等
对象权限:对数据库对象的数据的操作权限。
角色:是将具有相同权限的用户组织在一起,这一组具有相同权限的用户称为角色。角色是一组权限的集合,一个权限可以赋给不同的角色。
数据库预定义角色有三个,DBA,PUBLIC,RESOURCE
三权分立和四权分立
三权分立:
数据库管理员(sysdba)
数据库安全员(syssso)
数据库审计员(sysauditor)
四权分立:
数据库管理员(sysdba)
数据库安全员(syssso)
数据库审计员(sysauditor)
数据库对象操作员(sysdbo)
所有账号的默认口令都与用户名大写一致。
Syssso:安全员
Sysdba:数据库管理员
Sys:数据库内置管理账号(不能登录数据库)
Sysauditor:审计员
4.3.1 规划用户
名字:字母开头,a-z,0-9,#_
位置:对应的表空间
密码:口令策略
0:无策略
1:禁止与用户名相同
2:口令长度不小于9
4:至少包含一个大写字母
8:至少包含一个数字
16:至少包含一个标点符号(英文的状态下输入 除空格和“”)
口令可以单独使用,也可以组合使用。比如说:要求口令策略禁止用户名相同,并且口令长度不小于9,则设置口令策略为3:
创建用户语句password policy 子句来指定口令策略,用户密码最长为48个字节。
Faild_login_attemps:密码尝试登录次数
Password_lock_time:密码失败后锁定时间
Password_life_time:密码过期时间
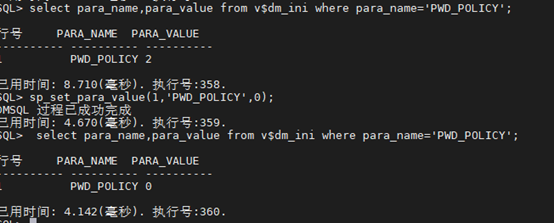
SQL> select para_name,para_value from vdm_ini where para_name=‘PWD_POLICY’;
SQL> sp_set_para_value(1,‘PWD_POLICY’,0);
案例1:建立用户test,用户可以创建自己的表,有属于自己的表空间,用户密码要求每60天变更一次。
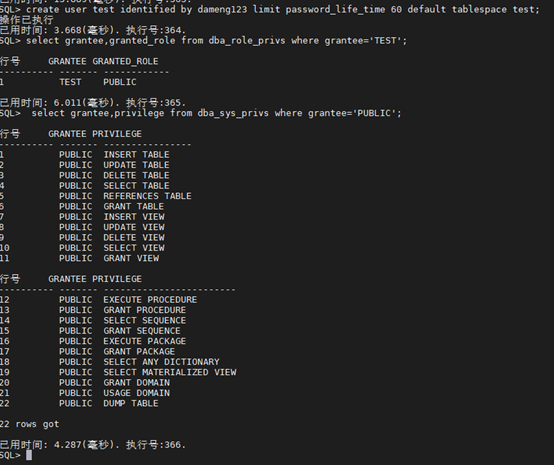
SQL> create user test identified by dameng123 limit password_life_time 60 default tablespace test;
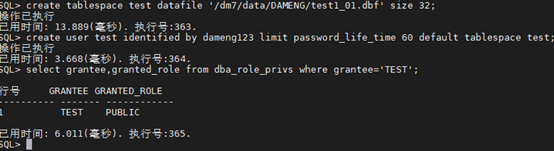
SQL> select grantee,granted_role from dba_role_privs where grantee=‘TEST’;
SQL> select grantee,privilege from dba_sys_privs where grantee=‘PUBLIC’;
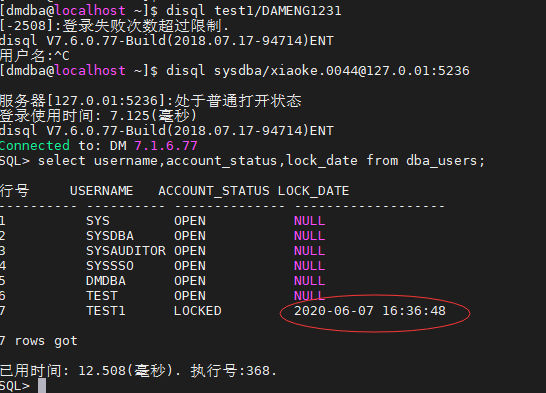
案例2:规划一个用户test1,用户每60天变更一次密码,密码尝试连接2次失败,账号锁定5分钟,用户能查询dmhr.employee表。
SQL> create user test11 identified by dameng123 limit password_life_time 60,failed_login_attemps 2,password_lock_time 5;
//尝试登录2次后
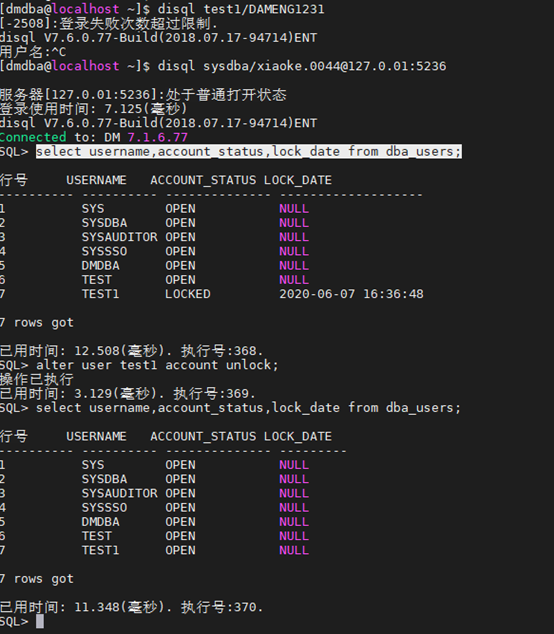
SQL> select username,account_status,lock_date from dba_users;
SQL>alter user test1 account unlock;
操作已执行
已用时间: 17.614(毫秒). 执行号:1856.
SQL> select username,account_status,lock_date from dba_users;
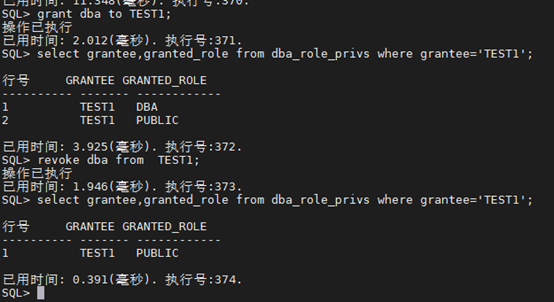
4.3.2 分配权限
SQL> grant dba to TEST1;
SQL> select grantee,granted_role from dba_role_privs where grantee=‘TEST1’;
SQL> revoke dba from TEST1;
4.3.3 用户维护
收回权限:revoke
SQL> revoke select on dmhr.employee from test1;
赋权限:
SQL> grant references any table to test2;
修改用户密码
SQL> alter user test identified by 123456789;
锁定用户
SQL> alter user test account lock;
解锁用户
SQL> alter user test account unlock;
删除用户:
SQL> drop user test;
SQL> drop user test cascade;-------慎重,最好先备份
删除角色:
SQL> drop role r1;
SQL> alter user test limit password_life_time 61;
4.4 创建重做日志
SQL> select * from v$rlogfile;
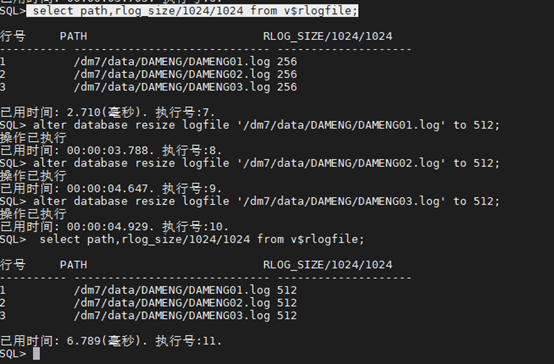
SQL> select path,rlog_size/1024/1024 from v$rlogfile;
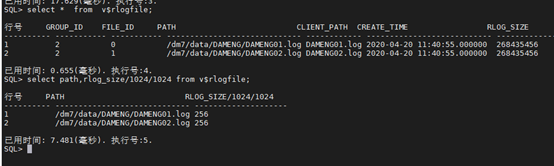
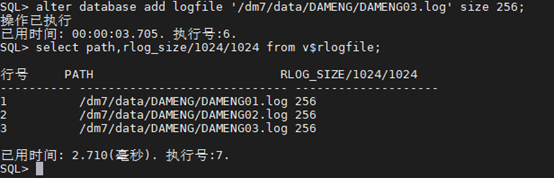
SQL> alter database add logfile ‘/dm7/data/DAMENG/DAMENG03.log’ size 256;
SQL> alter database resize logfile ‘/dm7/data/DAMENG/DAMENG01.log’ to 512;
操作已执行
已用时间: 00:00:03.788. 执行号:8.
SQL> alter database resize logfile ‘/dm7/data/DAMENG/DAMENG02.log’ to 512;
操作已执行
已用时间: 00:00:04.647. 执行号:9.
SQL> alter database resize logfile ‘/dm7/data/DAMENG/DAMENG03.log’ to 512;
五. 模式对象管理
模式是所有对象的集合(表,视图,索引,列,同义词,自增列)
DM在创建用户的时候,会默认的创建一个同名的模式。如果你创建的用户,模式名已存在,用户无法创建。
5.1 模式管理
SQL> CREATE SCHEMA “DAMENG1” AUTHORIZATION “SYSDBA”;
SQL> select t.NAME from SYSOBJECTS t where TYPE$=‘SCH’;
5.2 表的管理
达梦支持默认的表索引组织表,支持堆表,临时表,分区表,外部表等等。
5.2.1 如何去规划表
1、命名:字母开头,a-z,0-9,$#_
2、数据类型int、char、 varchar、 date、 clob、 blob、 number等等。

3、存储位置:自己规划的表空间,如果没有指定表空间,则会存储到main表空间。
4、约束(5大约束)非空约束,唯一约束,主键,检查约束,外键约束
5、注释:comment;
案例1:规划一张学员信息表。
表名:STU
学号:id char(10)
姓名:sname varchar(20) not null
性别:sex char(1)
年龄:age int
电话:tel varchar(15) not null
家庭住址:address varchar(50)
表空间 STU
约束 主键列----学号,非空-----姓名和电话。
备注:student info
create table “TEST”.“STU”
(
“ID” CHAR(10) not null ,
“SNAME” VARCHAR(20) not null ,
“SEX” CHAR(1),
“AGE” INT,
“TEL” VARCHAR(15) not null ,
“ADDRESS” VARCHAR(50),
primary key(“ID”)
);
SQL>comment on table “TEST”.“STU” is ‘STUDENT INFO’;
SQL> comment on column “TEST”.“STU1”.“ID” is ‘THIS IS ID’;
SQL>SELECT * FROM SYS.DBA_COL_COMMENTS WHERE DBA_COL_COMMENTS.TABLE_NAME=‘STU’
SQL>SELECT * FROM SYS.DBA_TAB_COMMENTS WHERE DBA_TAB_COMMENTS.TABLE_NAME=‘STU’
5.2.2 创建表的时候指定约束
5.2.2.1 非空约束
SQL> create table test.t1(id int);
SQL> alter table test.t1 modify id int not null;
SQL> create table test.t11(id int not null);
SQL> CALL SP_TABLEDEF(‘TEST’, ‘T1’);

5.2.2.2 唯一约束
SQL> create table test.t2(id int unique);
唯一约束遇到null,忽略,可录入多个。
5.2.2.3 主键约束
(一张表只能有一个主键约束)
SQL> create table test.t3(id int primary key);
SQL> create table test.t4(id int);
SQL> alter table test.t4 add constraint t4_pri primary key(id);
5.2.2.4 检查约束
SQL> create table test.t5(id int check(id>=5));
5.2.2.5 外键约束
(可以有多个外键,外键是另一张表的主键)
SQL>create table test.t6(sid int primary key,pid int);
SQL> create table test.t7(id int primary key,sid int foreign key references test.t6(sid));
5.2.2.6 对列加备注
SQL> comment on column test.t6.sid is ‘编号’;
SQL>select TABLE_NAME,COLUMN_NAME,COMMENTS from dba_col_comments where table_name=‘T6’;
SQL> select * from dba_tab_comments where OWNER=‘TEST’;
5.2.2.7 执行sql脚本导入数据
[dmdba@localhost ~]$ more /home/dmdba/a.sql
insert into test.t1 values (1);
insert into test.t1 values (2);
insert into test.t1 values (3);
insert into test.t1 values (4);
insert into test.t1 values (5);
insert into test.t1 values (6);
insert into test.t1 values (7);
5.3 视图的管理
视图分类:简单视图,复杂视图,物化视图
注意:简单视图和复杂视图不占磁盘空间,物化视图占磁盘空间。
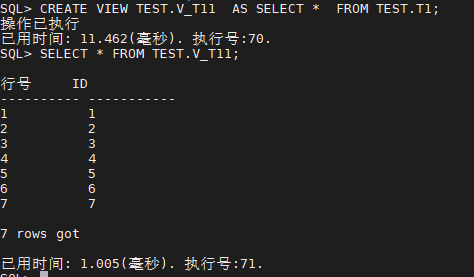
SQL> CREATE VIEW TEST.V_T11 AS SELECT * FROM TEST.T1;
SQL> SELECT * FROM SYS.DBA_VIEWS WHERE DBA_VIEWS.OWNER=‘TEST’;

SQL> drop view “TEST”.“V_T11” restrict;
5.4 索引管理
索引的作用:加快表的查询,增加数据库的查询性能,对数据库做DML操作的时候,数据库会自动维护索引。
索引是一棵倒置的树,使用索引,就是对这棵树做遍历。
达梦支持的索引:二级索引,位图索引,唯一索引,复合索引,函数索引,分区索引等。
建立索引的规则:
适合建索引的情况:
1、经常查询的列
2、连接条件列
3、谓词经常出现的列(where)
4、查询是返回表的一小部分数据。
…
不适合建索引的情况
1、列上有大量的null
2、列上的数据有限
5.4.1 创建索引
规划索引表空间:表的数据是无序的,索引的数据是有序的。
创建索引表空间。
SQL> create tablespace idx_data datafile ‘/dm7/data/DAMENG/idx_data_01.dbf’ size 32;
SQL>grant select on SYS.DBA_VIEWS to test;
SQL> create table test.v1 as select * from SYS.DBA_VIEWS;
SQL>create index test.idx_v1_name on test.v1(view_name) tablespace idx_data;
搜集信息
SQL> begin dbms_stats.gather_table_stats(‘TEST’,‘V1’); end;


5.4.2 维护索引
SQL> SELECT * FROM SYS.DBA_INDEXES WHERE DBA_INDEXES.OWNER=‘TEST’
重建:
SQL> ALTER INDEX TEST.IDX_V1_NAME REBUILD;
SQL> ALTER INDEX TEST.IDX_V1_NAME REBUILD ONLINE;
删除索引:
SQL> DROP INDEX TEST.IDX_V1_NAME;
注意:达梦默认不会自动收集统计信息,需要手动收集。
5.5 序列管理
预分配的一组内存空间,可以将序列作为自增列。
SQL>create sequence test.seq11
start with 1 -----序列的起始
increment by 1 ------自增多少
maxvalue 5 ----- 最大值
nocache ----- 是否缓存
nocycle; ----是否循环
SQL> create table test.t10(id int primary key);
SQL> insert into test.t10 values(test.seq11.nextval);
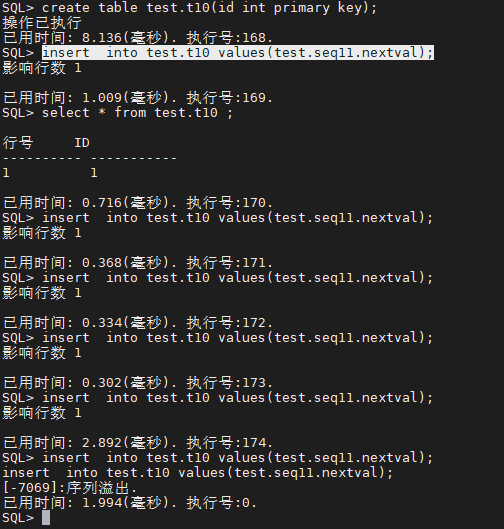
SQL> alter sequence test.seq11 maxvalue 10;
SQL> select test.seq11.nextval;
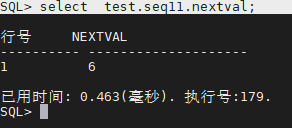
删除序列:
SQL> drop sequence test.seq11;
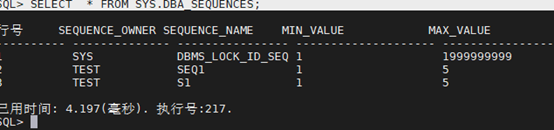
SQL> SELECT * FROM SYS.DBA_SEQUENCES;
5.6 同义词管理
同义词是对象的别名,可以替换模式下的表,视图,序列,函数,存储过程等对象。
同义词分为公共同义词,普通同义词。
公共同义词:所有用户都可以使用的,使用的时候不用加上任何的模式名。
普通同义词:在某个模式下定义的同义词,引用的时候需要加上模式名。
创建同义词
普通:SQL> create synonym test.sy1 for dmhr.employee;
公共:SQL> create public synonym sy3 for dmhr.city;
查询同义词:
SQL> select table_name, synonym_name from dba_synonyms where synonym_name in (‘SY1’,‘SY3’);
删除同义词:
SQL> drop synonym test.sy1;
SQL> drop public synonym sy3;
5.7 自增列
一个有序的数列,一个表只能有一个自增列。
语法:identity[(种子,增量)]
参数:
种子:装载到表中的第一个行所使用的值。
增量:增量值,可以为正数,也可为负数,但不能为0
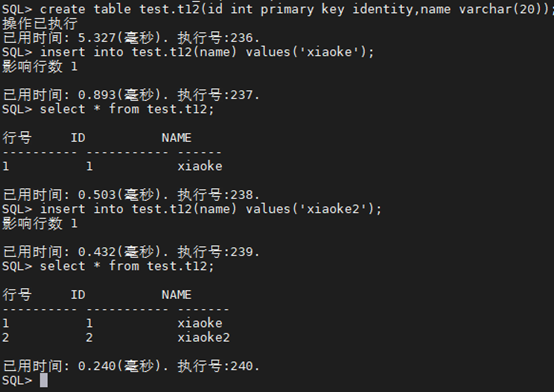
SQL> create table test.t12(id int primary key identity,name varchar(20));
SQL> create table “TEST”.“t12”
(
“id” INT identity(1, 1) not null ,
“name” CHAR(10)
);
SQL>alter table “TEST”.“t12” add constraint primary key(“id”);
SQL> insert into test.t12(name) values(‘xiaoke’);
六. DMSQL
DMSQL基于sql92,部分sql99
Sql:结构化的查询语言
DDL:定义 create drop alter truncate
DML:管理 select update delete insert
DCL:控制 grant revoke
TCL:事务控制:commit rollback
6.1 简单查询
start /dm7/samples/instance_script/dmhr/CREATESCHEMA.sql
start /dm7/samples/instance_script/dmhr/REGION.sql
start /dm7/samples/instance_script/dmhr/LOCATION.sql
start /dm7/samples/instance_script/dmhr/DEPARTMENT.sql
start /dm7/samples/instance_script/dmhr/JOB_HISTORY.sql
start /dm7/samples/instance_script/dmhr/JOB.sql
start /dm7/samples/instance_script/dmhr/EMPLOYEE.sql
SQL> start /dm7/samples/instance_script/dmhr/CITY.sql
语法:select () from ()
第一个括号:* ,column_name,alias, expr || distinct
第二个括号:table_name
Select * from dmhr.city;
Select city_name,city_id from dmhr.city
Select city_name cn from dmhr.city
SQL>select employee_name||’的工资是:’||salary as desc1 from test.emp limit 10;
SQL>select distinct department_id from test.emp;
6.2 过滤查询
Where 子句常用的查询条件由谓词和逻辑运算符组成,谓词指一个条件,结果为一个布尔值,真,假或未知
逻辑运算符 and or not
比较为谓词:< > <= >= <>
Between\ in \like \null \exists
LIKE % _
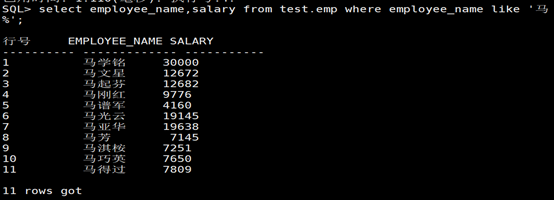
SQL> select employee_name,salary from test.emp where employee_name like ‘马%’;
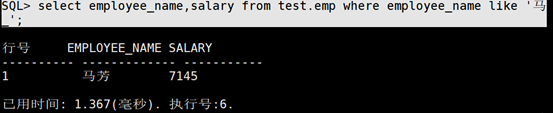
SQL> select employee_name,salary from test.emp where employee_name like ‘马_’;
SQL> select employee_name,salary from test.emp where salary between 20000 and 30000;
In 枚举
SQL> select employee_name,salary from test.emp where employee_name in(‘李慧军’,‘陈仙’,‘郑成功’,‘葛明霞’,‘周峰’);
SQL> select employee_name,salary from test.emp where employee_name=‘李慧军’ or employee_name=‘陈仙’ or employee_name=‘郑成功’ or employee_name=‘葛 明霞’ or employee_name=‘周峰’;
集函数:
1、count(*)
2、字符串集函数: listagg/listagg2 lower() upper()
3、首行函数:first_value
4、求区间范围内最大值:area_max
5、AVG,MAX,MIN,SUM
案例1:求各个部门的最高工资
SQL> select department_id,max(salary) from test.emp group by department_id
案例2:找出部门平均工资大于10000的所有部门。
SQL> select department_id, avg(salary) av1 from test.emp group by department_id having avg(salary)>10000;
注意:having 表示分组后的数据进行过滤,having不能单独使用,一定是和group by 一起使用的。
Select 后出现的列(聚合函数除外),一定要出现在group by 之后。
排序 升序 asc 降序 desc 默认升序
SQL> select department_id, avg(salary) av1 from test.emp group by department_id having avg(salary)>10000 order by av1;
SQL> select department_id, avg(salary) av1 from test.emp group by department_id having avg(salary)>10000 order by av1 desc;
单行函数
数值函数
Round(), trunc(), asb(),mod()
字符串函数
Upper 大写
Lower 小写
Initcap 首字母大写
Instr 查子字符串
Substr 截取子字符串
Lpad ,rpad 补齐空格
Trim 删除空格
Concat ||
SQL> select substr(email,1,(instr(email,’@’)-1)),employee_name from test.emp limit 10;
日期函数
Sysdate 系统当前时间
Add_days /weeks/months
SQL> select add_days(sysdate,10);
SQL> select last_day(sysdate);
SQL> select next_day(sysdate,5);
日期和字符的转换
SQL> select to_char(sysdate,‘yyyy-mm-dd hh24:mi:ss’);
SQL> select to_date(‘2020-01-01 00:00:00’,‘yyyy-mm-dd hh24:mi:ss’);
6.3 多表联接查询
语法:select() from () join() on()
第三个括号:表名
第四个括号:关联字段
1、内连接:结果集显示全部满足连接条件的记录
SQL> select employee_name,department_name from dmhr.employee e join dmhr.department d on e.department_id=d.department_id limit 10;
2、外连接
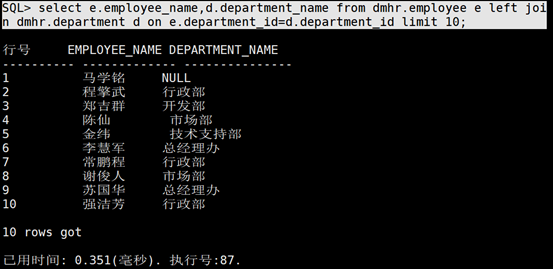
左外连接:把写在left join 左边的全部显示出来,右边的只显示满足条件的,不满足条件的用null代替
update dmhr.employee set department_id=null where employee_id=1001;
SQL> select e.employee_name,d.department_name from dmhr.employee e left join dmhr.department d on e.department_id=d.department_id limit 10;
右外连接:把写在right join右边的全部显示出来,左边的只显示满足条件,不满足条件的用null代替
SQL> select e.employee_name,d.department_name from dmhr.employee e right join dmhr.department d on e.department_id=d.department_id limit 10;
全外连接:返回所有的记录,包括不满足条件的。
SQL> select e.employee_name,d.department_name from dmhr.employee e full join dmhr.department d on e.department_id=d.department_id limit 10;
全外连接=左外连接 union 右外连接
总结:
1、查询两个表的关联列相关的数据用内连接
2、Col_l是col_r的子集的时候用右外连接
3、Col_r是col_l子集的时候用左外连接
4、Col_r和col_l 彼此有交集的时候,但是彼此不互为子集的时候,用全外连接。
6.4 子查询
子查询是一个查询sql嵌套在主查询中,并且其结果为主查询的条件,子查询先于主查询运行。
1、结果集返回值是唯一的:
Select () from () where()=(子查询结果)
查询金纬所在部门的所有人员
SQL> select employee_name,department_id from dmhr.employee where department_id=(select department_id from dmhr.employee where employee_name=‘金纬’);
2、结果集返回值是多行的
Select() from () where ()>|any|all(子查询)
ALL: >ALL (MAX) <ALL(MIN)
ANY:>ANY(MIN) <ANY(MAX)
找出比1105部门的所有人工资都高的人
SQL> select employee_name,department_id,salary from dmhr.employee where salary >all (select salary from dmhr.employee where department_id=1105);
找出比1105部门任意一个人工资都高的人
SQL> select employee_name,department_id,salary from dmhr.employee where salary >any(select salary from dmhr.employee where department_id=1105);
IN EXISTS
SQL>select employee_name,salary from test.emp where employee_name in(‘李慧军’,‘陈仙’,‘郑成功’,‘葛明霞’,‘周峰’);
SQL> select employee_name,salary from dmhr.employee where exists(select employee_name from dmhr.employee where department_id=‘104000’);
IN:把子查询运行完,再运行主查询
Exists:先运行子查询,如果有满足条件的,再运行主查询。
七. 备份还原
7.1 备份的作用
1、防止误操作
2、软硬件故障,做恢复
3、防止天灾。
备份的方式,物理备份和逻辑备份
备份的介质:磁盘,磁带,光盘
集群:数据守护 ,dsc (rac)
也支持第三方的备份软件:上海爱数,鼎甲。
7.1.1 物理备份
7.1.1.1 冷备
冷备:dmap服务是打开的,数据库实例是关闭的。
方式:
1、利用控制台工具去备
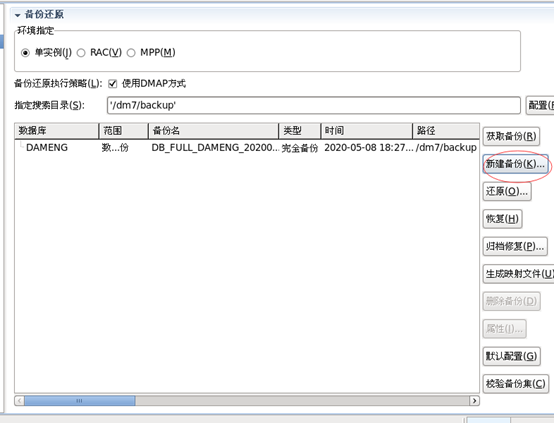
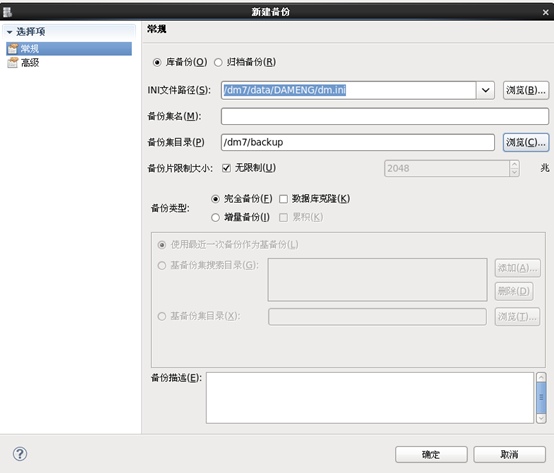
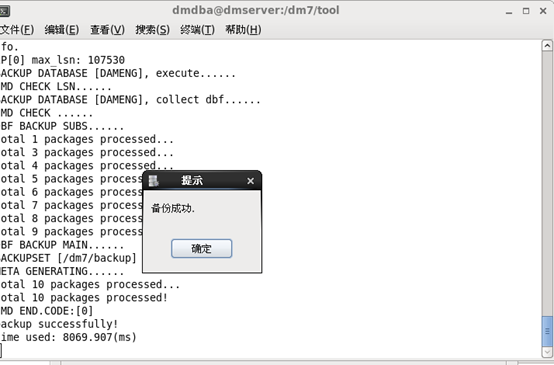
2、利用命令去备份
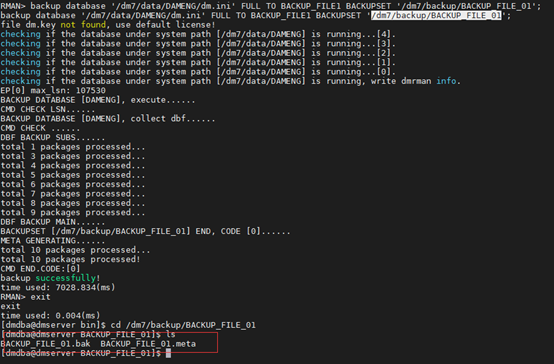
[dmdba@dmserver ~]$ cd /dm7/bin
[dmdba@dmserver bin]$ ./dmrman
RMAN> backup database ‘/dm7/data/DAMENG/dm.ini’ FULL TO BACKUP_FILE1 BACKUPSET ‘/dm7/backup/BACKUP_FILE_01’;
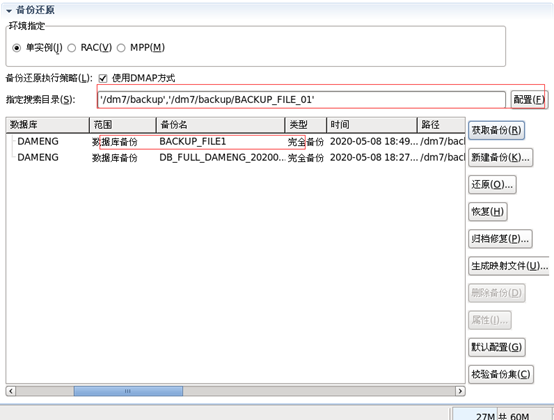
7.1.1.2 热备份
注意:dmap服务是打开的,数据库实例是打开的,数据库是归档模式。
[dmdba@dmserver ~]$ disql sysdba/xiaoke.0044
SQL> ALTER DATABASE MOUNT;
SQL> ALTER DATABASE ARCHIVELOG;
SQL> ALTER DATABASE ADD ARCHIVELOG ‘DEST=/dm7/arch,TYPE=LOCAL,FILE_SIZE=256,SPACE_LIMIT=204800’;
SQL> ALTER DATABASE OPEN;
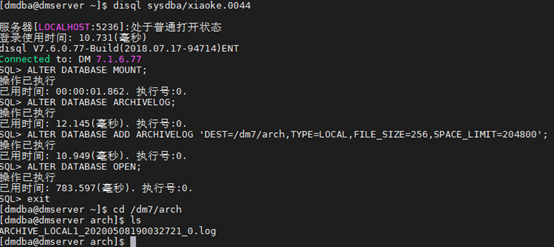
1、利用命令去备份
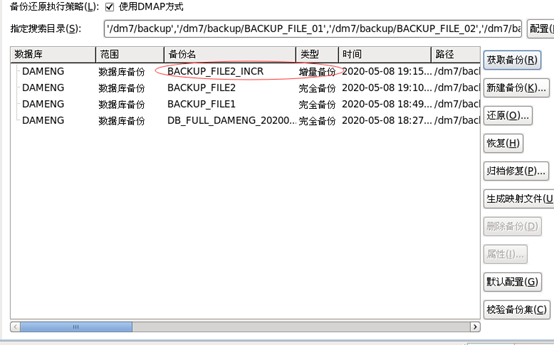
SQL> backup database full TO BACKUP_FILE2 BACKUPSET ‘/dm7/backup/BACKUP_FILE_02’;


#增量备份
SQL> backup database increment TO BACKUP_FILE2_INCR BACKUPSET ‘/dm7/backup/BACKUP_FILE_02_INCR’;

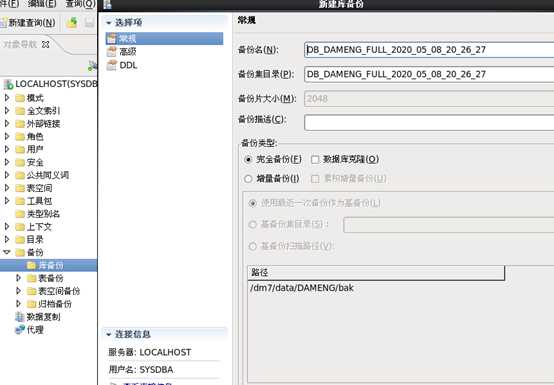
2、利用管理工具去备份
7.1.1.3 还原
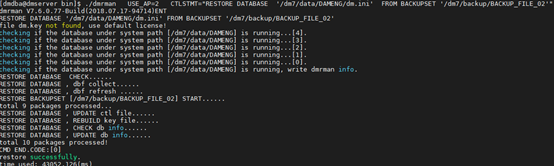
[dmdba@dmserver bin]$ ./dmrman USE_AP=2 CTLSTMT=“RESTORE DATABASE ‘/dm7/data/DAMENG/dm.ini’ FROM BACKUPSET ‘/dm7/backup/BACKUP_FILE_02’”
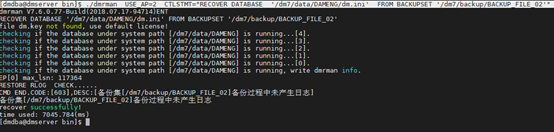
[dmdba@dmserver bin]$ ./dmrman USE_AP=2 CTLSTMT=“RECOVER DATABASE ‘/dm7/data/DAMENG/dm.ini’ FROM BACKUPSET ‘/dm7/backup/BACKUP_FILE_02’”
[root@dmserver ~]# service DmServiceDAMENG start
7.2 逻辑备份
导入导出(DEXP ,DIMP)
分为四种级别:分别独立,互斥不能同时存在。
数据库级别:导出或导入整个数据库的访问对象。
用户:导入或导出一个或多个用户所拥有的所有对象
模式:导入或导出一个或多个模式下所有的对象。
表级:导出或导入一个或多个指定表或表分区。
7.2.1 全库\用户备份
[dmdba@dmserver bin]$ ./dexp sysdba/xiaoke.0044 file=/dm7/backup/DAMENG_FULL20200509.dmp log=/dm7/backup/DAMENG_FULL20200509.log full=y
//用户备份
[dmdba@dmserver bin]$ ./dexp sysdba/xiaoke.0044 file=/dm7/backup/DAMENG_test_20200509.dmp log=/dm7/backup/DAMENG_FULL20200509.log owner=TEST
7.2.2 全库还原
[dmdba@dmserver bin]$ ./dimp sysdba/xiaoke.0044 file=/dm7/backup/DAMENG_FULL20200509.dmp log=/dm7/backup/DAMENG_FULL202005091.log full=y
7.2.3 用户还原
SQL> DROP USER TEST CASCADE;
SQL> create user test identified by “xiaoke.0044”;
[dmdba@dmserver bin]$ ./dimp sysdba/xiaoke.0044 file=/dm7/backup/DAMENG_FULL20200509.dmp log=/dm7/backup/DAMENG_FULL202005091.log owner=TEST
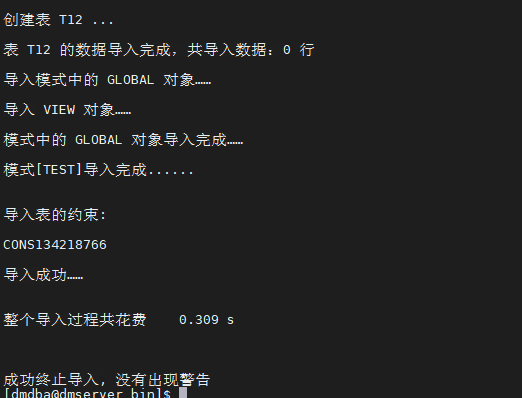
[dmdba@dmserver bin]$ ./dimp sysdba/xiaoke.0044 file=/dm7/backup/DAMENG_test_20200509.dmp log=/dm7/backup/DAMENG_FULL20200509.log owner=TEST
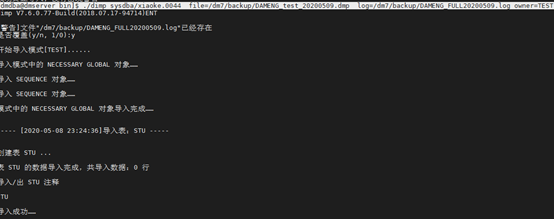
八. 作业
定时去执行的一组任务
8.1 定期去备份
1、创建代理环境(会自动创建一个sysjob模式)
2、创建作业
第一步:DM管理工具–创建代理环境
第二步:创建备份目录/dm7/backup
第三步:执行如下脚本
call SP_CREATE_JOB(‘DB_FULL_BAK’,1,0,’’,0,0,’’,0,‘定时全库备份’);
call SP_JOB_CONFIG_START(‘DB_FULL_BAK’);
call SP_ADD_JOB_STEP(‘DB_FULL_BAK’, ‘S1’, 6, ‘01040000/dm7/backup’, 1, 2, 0, 0, NULL, 0);
call SP_ADD_JOB_SCHEDULE(‘DB_FULL_BAK’, ‘S2’, 1, 1, 1, 0, 0, ‘22:00:00’, NULL, ‘2020-05-09 07:00:00’, NULL, ‘每天 22:00:00 做一次全备’);
call SP_JOB_CONFIG_COMMIT(‘DB_FULL_BAK’);
第四步:开启依赖dmap服务
[dmdba@localhost dm7]$ service DmAPService start
第五步:定时删除30天前的备份
call SP_CREATE_JOB(‘DEL_DB_FULL_BAK’,1,0,’’,0,0,’’,0,‘定时删除全库备份’);
call SP_JOB_CONFIG_START(‘DEL_DB_FULL_BAK’);
call SP_ADD_JOB_STEP(‘DEL_DB_FULL_BAK’, ‘S1’, 0, ‘SP_DB_BAKSET_REMOVE_BATCH(NULL,SYSDATE-30);’, 1, 2, 0, 0, NULL, 0);
call SP_ADD_JOB_SCHEDULE(‘DEL_DB_FULL_BAK’, ‘S2’, 1, 1, 1, 0, 0, ‘01:00:00’, NULL, ‘2020-05-09 15:14:18’, NULL, ‘’);
call SP_JOB_CONFIG_COMMIT(‘DEL_DB_FULL_BAK’);
第六步:删除30天前的归档日志文件
call SP_CREATE_JOB(‘DEL_ARCH’,1,0,’’,0,0,’’,0,‘定时删除归档’);
call SP_JOB_CONFIG_START(‘DEL_ARCH’);
call SP_ADD_JOB_STEP(‘DEL_ARCH’, ‘S1’, 0, ‘SF_ARCHIVELOG_DELETE_BEFORE_TIME(SYSDATE - 30);’, 1, 2, 0, 0, NULL, 0);
call SP_ADD_JOB_SCHEDULE(‘DEL_ARCH’, ‘S2’, 1, 1, 1, 0, 0, ‘02:00:00’, NULL, ‘2020-05-09 15:30:33’, NULL, ‘’);
call SP_JOB_CONFIG_COMMIT(‘DEL_ARCH’);
九. 配置ODBC
Linux 环境中配置ODBC环境
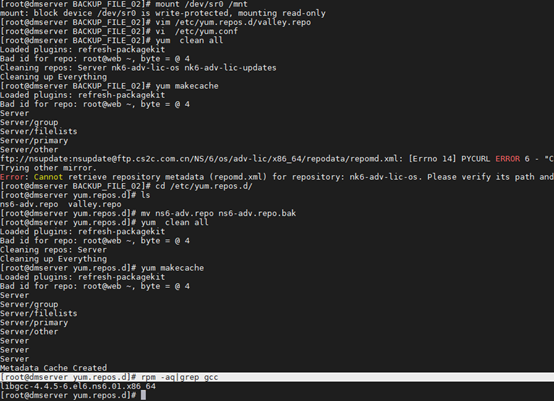
检查:rpm -aq|grep gcc 有没有gcc包,如果没有,配置yum源去装
[root@dmserver yum.repos.d]# rpm -aq|grep gcc
[root@dmserver yum.repos.d]# yum install gcc*
[root@dmserver yum.repos.d]# rpm -qa |grep unixODBC
[root@dmserver yum.repos.d]# yum install unixODBC
查看odbc的版本
[root@dmserver yum.repos.d]# odbc_config –version
查看ODBC配置文件的路径
[root@dmserver yum.repos.d]# odbc_config --odbcini
[root@dmserver yum.repos.d]# odbcinst –j
配置ODBC.INI 和odbcinst.ini
[root@dmserver yum.repos.d]# more /etc/odbc.ini
[dm7]
Desription = DM ODBC DSND
Driver = DM7 ODBC DRIVER
SERVER = localhost
UID = SYSDBA
PWD = xiaoke.0044
TCP_PORT = 5236
[root@dmserver yum.repos.d]# more /etc/odbcinst.ini
[root@dmserver yum.repos.d]# more /etc/odbcinst.ini
Example driver definitions
Driver from the postgresql-odbc package
Setup from the unixODBC package
[PostgreSQL]
Description = ODBC for PostgreSQL
Driver = /usr/lib/psqlodbc.so
Setup = /usr/lib/libodbcpsqlS.so
Driver64 = /usr/lib64/psqlodbc.so
Setup64 = /usr/lib64/libodbcpsqlS.so
FileUsage = 1
Driver from the mysql-connector-odbc package
Setup from the unixODBC package
[MySQL]
Description = ODBC for MySQL
Driver = /usr/lib/libmyodbc5.so
Setup = /usr/lib/libodbcmyS.so
Driver64 = /usr/lib64/libmyodbc5.so
Setup64 = /usr/lib64/libodbcmyS.so
FileUsage = 1
[DM7 ODBC DRIVER]
Description = ODBC DRIVER FOR DM7
Driver = /dm7/bin/libdodbc.so
[root@dmserver yum.repos.d]# su - dmdba
[dmdba@dmserver ~]$ isql dm7

