搞ORACLE数据库的必须会看AWR报告,现在的AWR报告内容越来越详细,也越来越易懂了。无论你的水平多高,能力多强,都能从AWR报告中看到一些你能看懂的东西。实际上AWR报告所能表现出来的数据库的情况,远比我们能解读出的多。十多年前,老白经常通过AWR帮用户分析系统中可能存在的隐患,寻找优化改进方案(当然那时候AWR还比较少,更多的是STATSPACK报告,二者的内容差别不是很大)。那时候认真解读一份AWR报告大概需要4-8个小时,期间可能还会和客户要一些额外的数据,从而确定发现的问题。可能有朋友会觉得惊讶,一份AWR报告能看上一天,这是什么鬼?实际上,从报告的头开始,AWR里就蕴含了十分丰富的信息。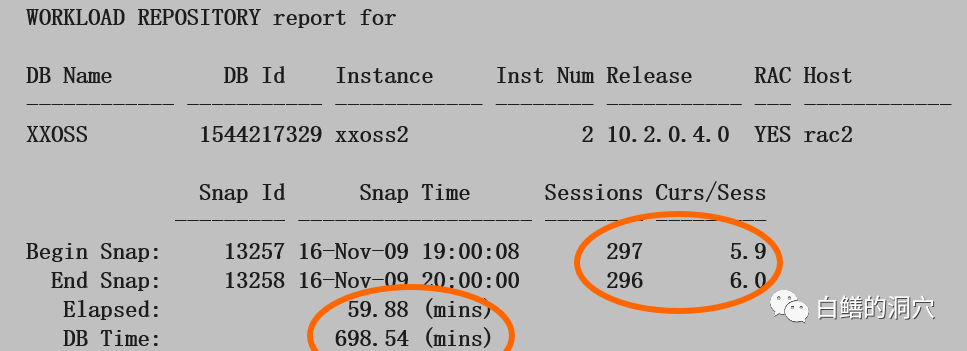
这仅仅是AWR的头,其中就蕴含了十分丰富的信息。不说前面的数据库版本,是否RAC,仅仅从老白画圈的这三个数据,就蕴含了十分丰富的内容。Sessions的数据是报告的两个采样点的会话数量,curs/sess是每个SESSION平均打开的CURSOR的数量。从这两个指标的绝对值以及两个SNAP之间的变化就可以看出会话变化的一些细节。会话数是高是低,变化趋势等信息。而每个会话打开的CURSOR数量则说明会话执行SQL的情况,以及可能对共享池产生的影响,同时可以用于分析OPEN_CURSOR参数与session_cached_cursors参数是否合理。DB Time是另外一个十分重要的指标,DB TIME与ELAPSED的比值可以看出系统的负载或者等待事件的情况。这个值的高低和活跃会话的数量也有十分大的关系。老白贴出的案例中大概是10左右。到底这个值是多少才是合理的?这个恐怕要和你的系统的基线有一定的关系了。如果你是经常维护这套系统,那么你可以每天都关注下业务最高峰时候这个指标的情况,如果这个比值出现了较大的偏差,那么你就需要认真的阅读这份报告,找到为什么会出现这样的异常了。我们再继续看看下面的数据,关于CACHE的数据,大家可能觉得没那么重要。实际上我们看看buffer cache和shared pool size在BEGIN END两个SNAP的差异,也能发现一些问题:
上面的案例是没变化,从中看不出异常来,如果BEGIN/END有差异,而且差异比较大,那么我们就要关注SGA的性能是否存在问题了,是否存在SGA抖动了。11g以后的版本的AWR报告中就有SGA RESIZE的情况,你可以在后面去查看,如果是10g的数据库,那么,可以到相关的视图中国去查看SGA RESIZE的情况。
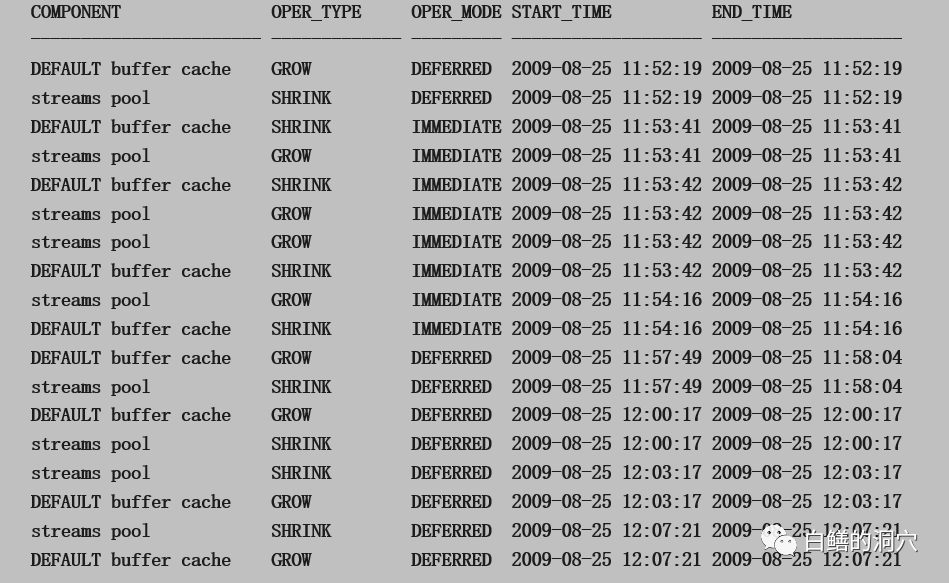
你就要注意了,要查查SGA出现这样的变化的原因是什么。上面的例子很可能是由于STREAMS复制,EXPDB等操作导致的STREAMS POOL的增长。今天我们没办法完整的介绍如何去解读一份AWR报告,不过在这里,老白也表达了一个观点,就是要通过我们所掌握的基线去分析某个指标是不是合理的,如果某个指标不合理,那么就需要把这个指标相关的AWR数据都找出来,进行仔细的分析,验证这个问题,或者更深入的去查找指标异常的原因。D-SMART大师问诊工具就是根据这个思路开发的,不过D-SMART并不基于AWR的数据(AWR的采样点为1小时或者30分钟,采样周期太长),而是基于一些1分钟,3分钟,5分钟的采样数据进行分析,同时把类似AWR的数据对数据库的总体评价分为了操作系统、IO、并发、负载、性能、集群、总体健康等数个维度建立了一个健康模型,通过健康模型来提醒运维人员系统可能存在隐患,然后针对发现隐患的维度,收集相关的数据进行综合分析和问题溯源。无论怎么做,这里都基于一个基线,这个基线可能在DBA的心里,实际上,更好的做法是在一个数据库中,这样我们可以通过统计学的方法去计算各种统计值,比如最小,最高,平均,方差,标准差,稳定性等。通过同一个数据库实例的基线数据对比,就能更好的反映出系统存在的问题。如果当前没有某个实例的历史数据,那么我们就需要根据“常识基线”来确定某个指标是否正常。比如下面的数据: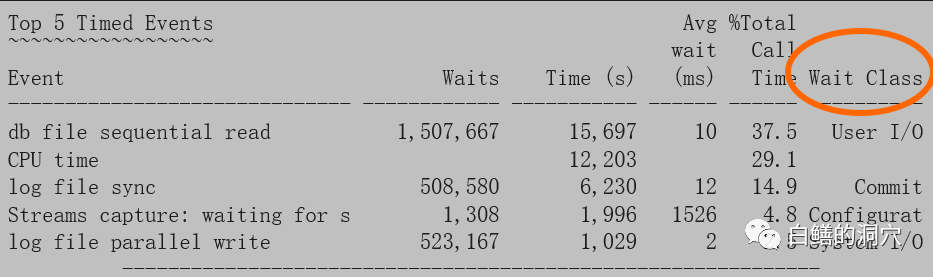
我们可以看出,db file sequential read的平均值是10毫秒,有点高,但是还算正常,是处于正常值的高值,可能IO对数据库有一定的影响,但是不一定致命。而中间的Streams capture:waiting for 这个指标是异常的,这个数据与上面的SGA RESIZE出于同一份AWR报告,也就说明了,当时可能是STREAMS捕获进程存在一些问题,导致了SGA RESIZE,抑或是SGA RESIZE导致了STREAMS捕获进程产生了一些不必要的等待。这样我们就又有了一个相对明确的分析方向了。
最后修改时间:2020-05-07 08:03:53
文章转载自
白鳝的洞穴,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





