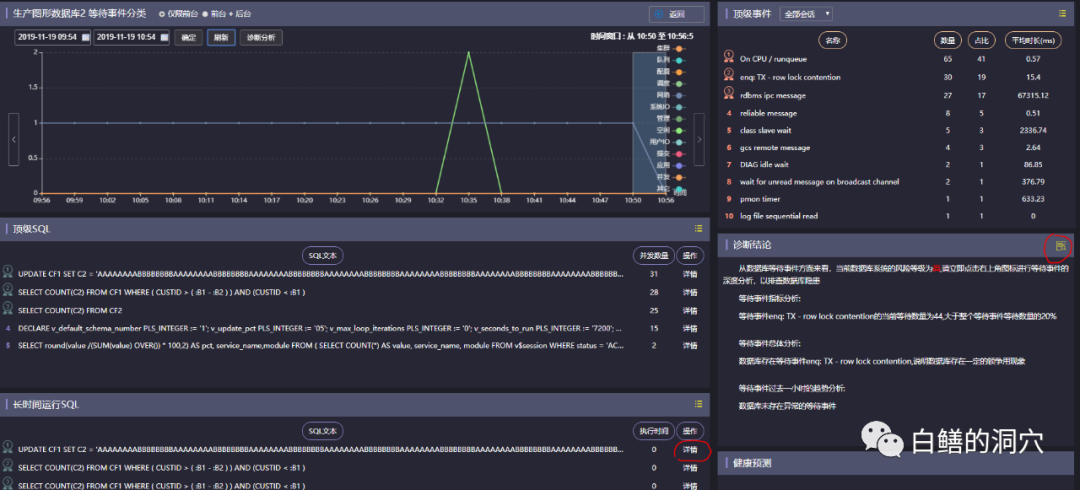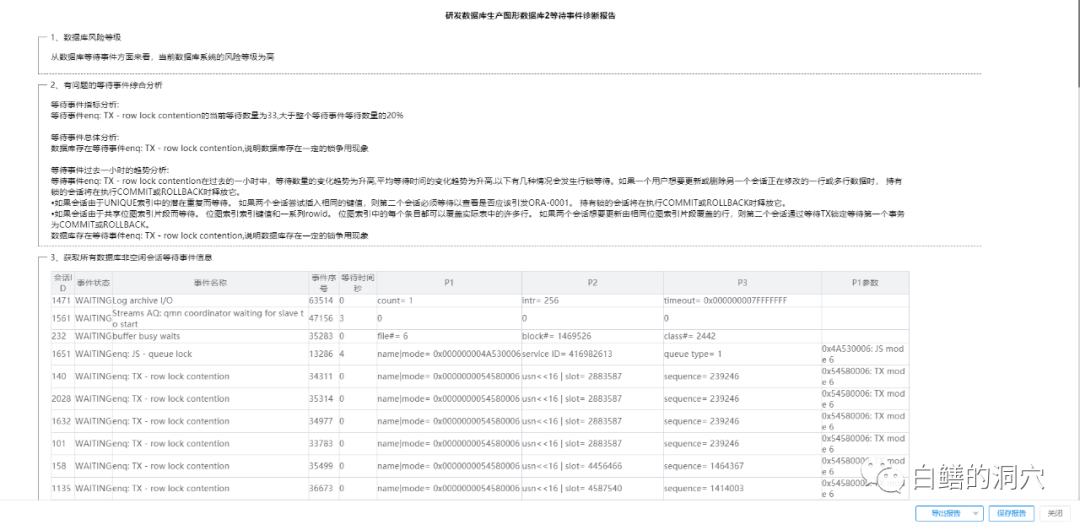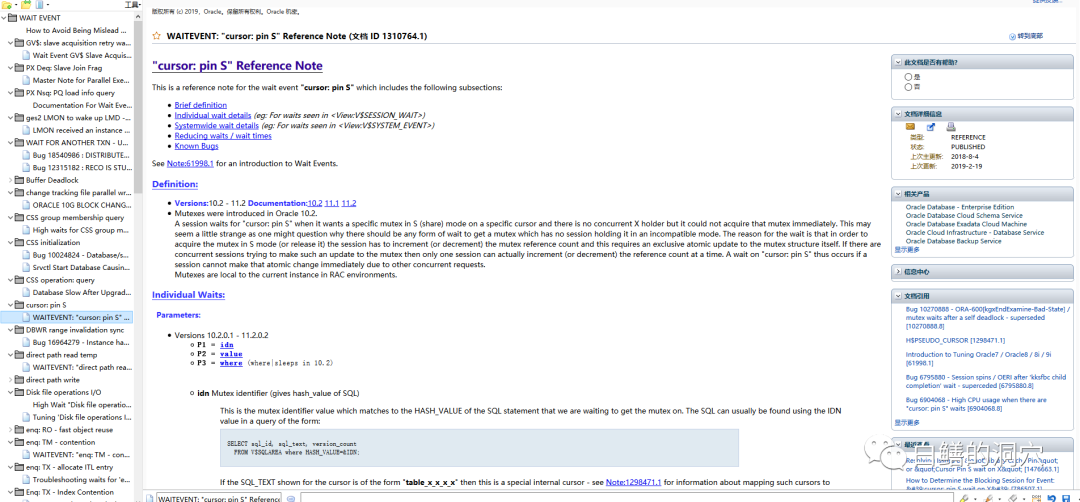
dbfile sequential read:单块读,如果平均响应时间超过20毫秒,基本上可以确定是过高,超过10毫秒就应该关注。存储系统比较好的环境,这个指标应该在4毫秒以内
dbfile scattered read:单块读,和全表扫描,全索引快速扫描相关,如果平均响应时间超过20毫秒,基本上可以确定是过高,超过10毫秒就应该关注。存储系统比较好的环境,这个指标应该在4毫秒以内
db file parallel write:数据文件写延时,一般存储系统比较好的环境中应该在2毫秒以内,超过10毫秒说明系统的写IO性能不是很好
log file parallel write:日志文件写延时,一般负载不是很大的系统应该在1-2毫秒,负载较大的不超过10毫秒,超过10毫秒说明日志写性能不是很好
和事务提交有关的等待事件:
log file sync:日志同步等待时间,会话提交后,等待日志记录从log buffer 写入到redo log文件的时间,一般比log file parallel write略大,如果该延时比log file parallel write大很多,说明存在Log buffer性能存在问题或者应用提交过于频繁等问题
Ave global cache get time (ms):一个GLOBAL CACHE的获取时间,一般来说应该小于5毫秒,如果这个指标超过20毫秒,对系统的性能影响将十分大。
Ave global cache convert time (ms):这个指标是对一个DATA BUFFER的访问权限转换所需要的平均时间,这个指标一般来说应该在4毫秒左右,超过20毫秒说明RAC的性能可能存在问题。
Ave time to process CR block request (ms):这个指标统计一个CR BLOCK请求的时间,包含生成CR BLOCK、刷新CR BLOCK和发送CR BLOCK的时间,在Oracle 10G的AWR报告里,这个指标被分解为三个部分(Avg global cache cr block build time、 Avg global cache cr block flush time、Avg global cache cr block send time),正常范围是在0.1毫秒到1毫秒,超过10毫秒,对系统的性能有较大的影响。
Ave receive time for CR block (ms):一个CR BLOCK从发起请求到收到的时间,一般来说这个指标在0.3毫秒-4毫秒之间,这个指标超过12毫秒,我们就需要关注
Ave time to process current block request (ms): 处理一个CURRENT状态的BLOCK请求的处理时间。一般情况下指标在3毫秒左右,大于20毫秒的时候就需要关注了。
Ave receive time for current block (ms):一个CURRENT的BLOCK从发起请求到收到的时间。这个指标一般情况下在8毫秒左右,负载较轻的系统可能会小于1毫秒,负载较重的系统,这个指标可能偏高,不过一般情况下,这个指标应该小于30毫秒。