最近一直在讨论基线,AWR报告等。前面几天都在讨论理论,最近几天老白来讲解几个案例。看看如何使用AWR报告分析与定位问题。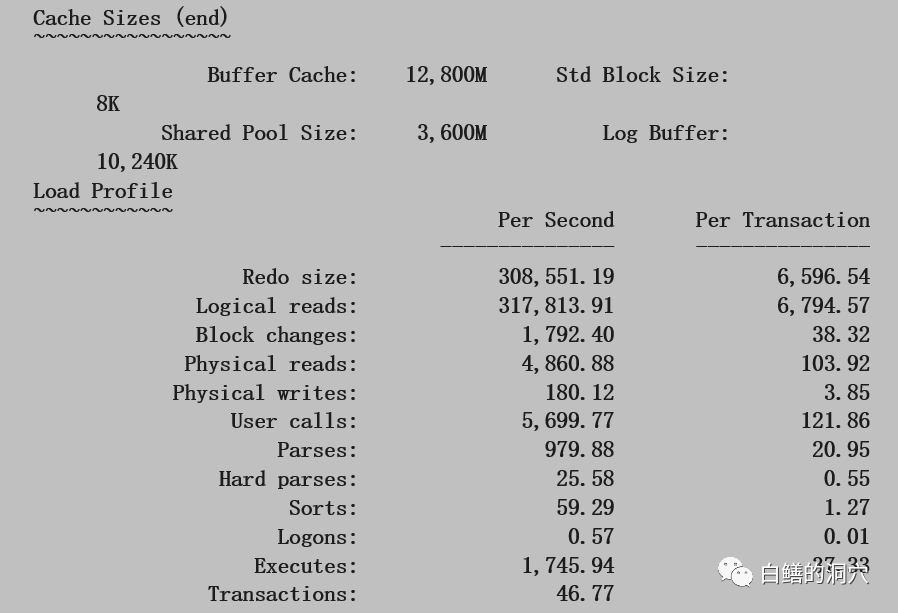
这是一个十分古老的案例,大约是在2003年左右的时候,数据库也是9i,报告是STATSPACK报告,当时还没有AWR。不过STATSPACK报告和AWR是一脉相承的,分析方法十分类似。我们首先来看这个系统,对于2003年的系统,每秒31万逻辑读,4860物理读,1745个执行,46.77个事务,这种系统也算比较大的了,不过还不算很大,因为后端的服务器和存储的能力都一般。下面我们来看看命中率的情况: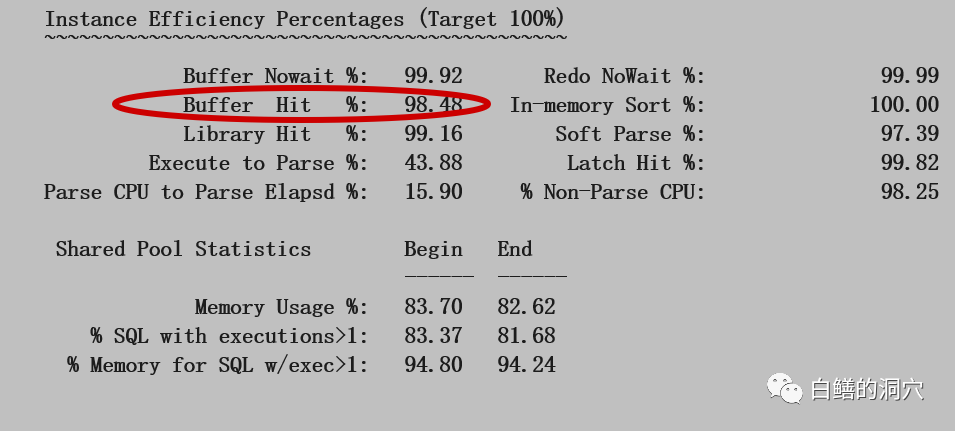
我标红的部分是因为我们在分析一个和IO相关的案例,因此DB CACHE的命中率是十分要注意的。为什么分析IO要看DB CACHE的命中率呢?如果命中率不是特别高,而且服务器的物理内存还有空闲,那么加大DB CACHE可以减少IO的总量,从而缓解IO系统的负载(如果IO系统是因为负载过高导致的性能问题,这招十分有用,如果IO系统负载没达到极限,这招的效果要打折扣了)。从这里我们看出命中率98.48,不算低,也不算特别高,在现在内存不值钱的年代,我们可以看看周边的数据库,极少有DB CACHE命中率低于99%的OLTP系统。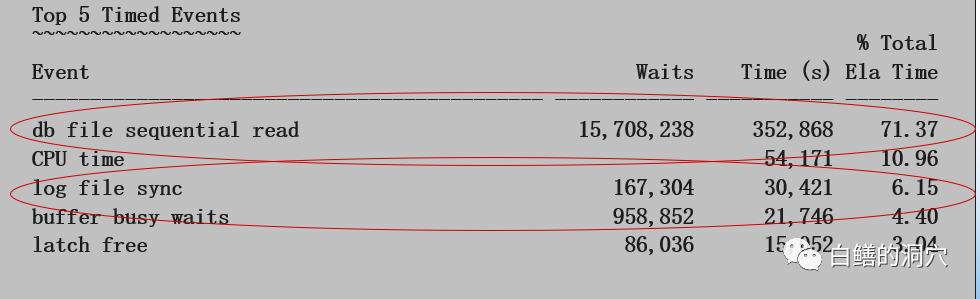
再来看看TOP 5 TIMED EVENT,除了CPU TIME和LATCH FREE外,其他几个都是和IO相关的。因为是STATSPACK报告,所以看不出平均等待时间,我们需要到后面的前台进程等待事件统计里去看相关的数据: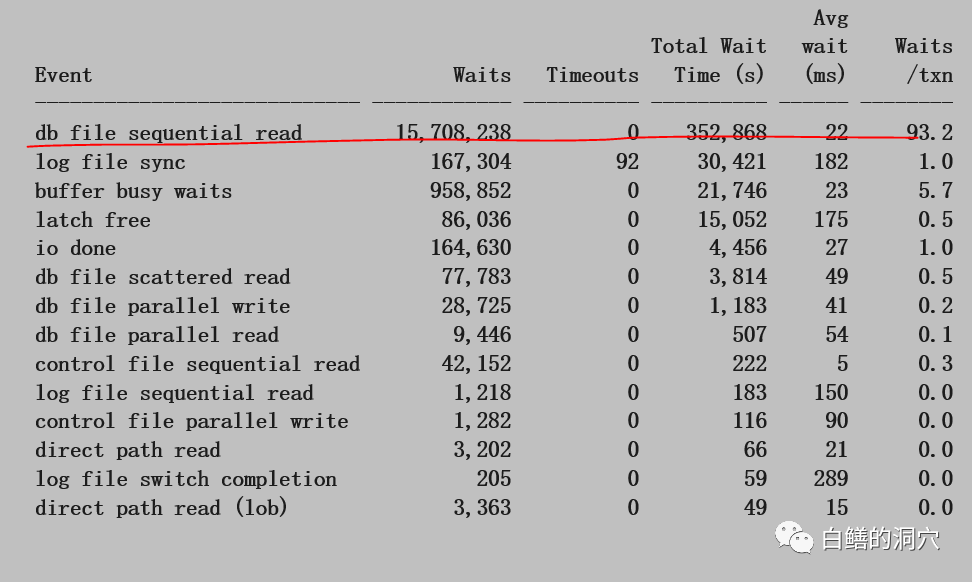
单块读的等待时间占整个等待的71%,在一个小时里达到352868秒,平均每秒将近100,对于一个只有8核的系统来说,这个算是很高了。平均延时也达到了22毫秒,已经超出了我们所说的基线了。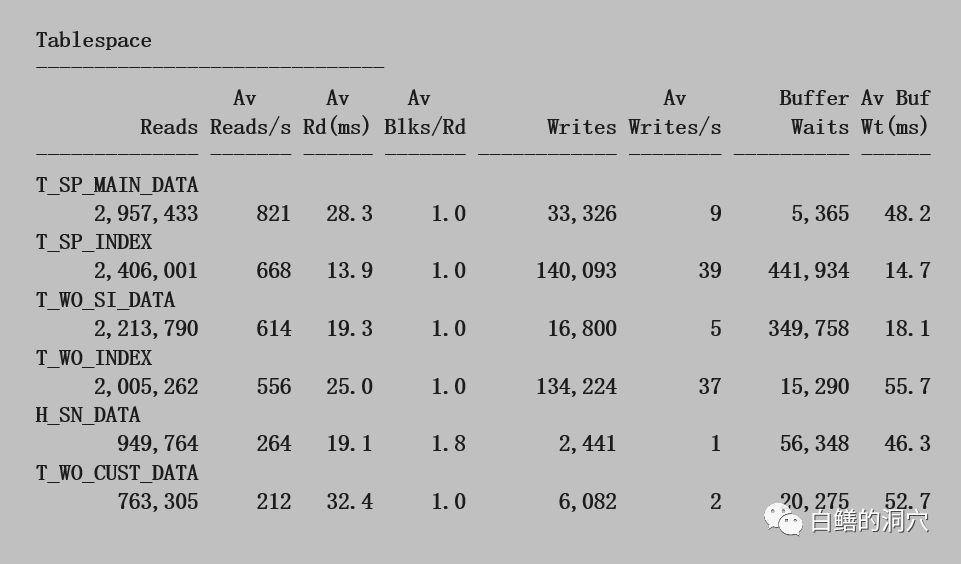
我们继续往下看表空间的IO延时,发现表空间的平均读等待时间差不多能印证db file sequential read等待的问题。和业务相关的几个表空间都存在IO延时过高的问题。具体到数据文件情况也差不多。
到这里我们已经十分明确,IO问题确实影响了我们的数据库性能。那么需要采取哪些措施来缓解呢?我们先要看看OS的IO情况,从sar -d的数据看,大多数设备的AVSERV的时间都超出了20毫秒,AVWAIT的时间也超过了10毫秒,说明后端存储已经出现了负载过高,性能不足的问题。于是我们需要进一步分析物理读较高的SQL的情况: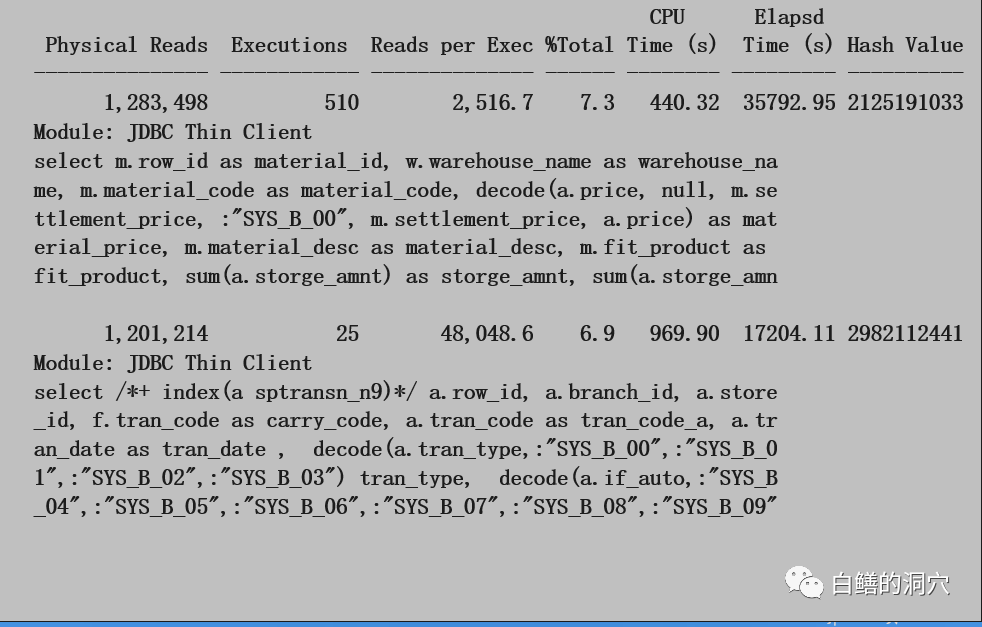
如果能够优化几条SQL,降低IO负载,可以立即达到缓解IO问题的效果。不过开发商的反馈是优化SQL需要大约1个月的时间。在此之前我们还需要采取一些措施来临时缓解问题。于是我们需要进一步分析DB CACHE的情况: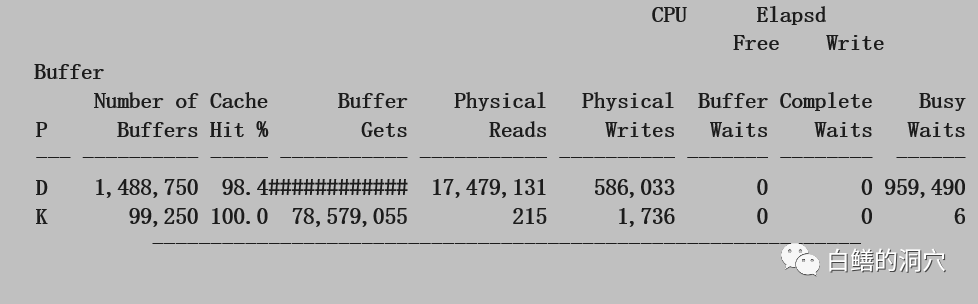
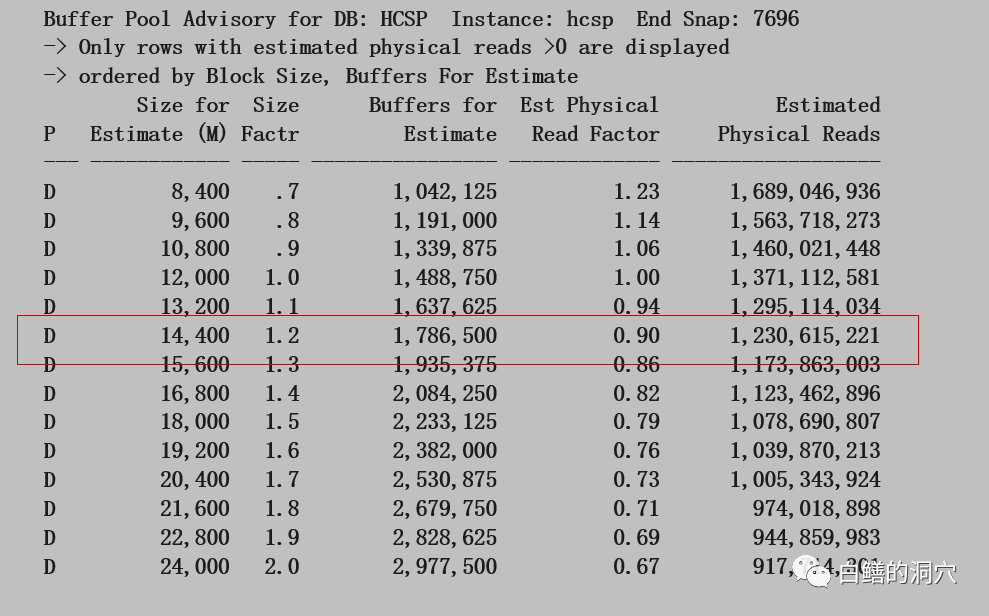
从这个直方图我们可以看出,加大2G的DB CACHE可以减少10%左右的物理IO,当前物理内存还可以再挤出2G空间来,于是我们给客户的建议如下:系统负载较高,存储能力不足
部分SQL需要优化
临时扩大2G DB CACHE可以改善IO情况
长远考虑需要对存储能力进行扩容
用户采纳了我们的建议,扩大2G DB CACHE后,IO情况与系统总体性能情况都有所好转。那两条SQL开发商认为已经无法优化,最后在我们的协助下,通过归档部分数据减少了IO开销。系统性能基本恢复正常。半年后,客户扩容了24块磁盘,至此,IO性能问题彻底解决了。
最后修改时间:2020-05-09 09:25:17
文章转载自
白鳝的洞穴,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





