一个系统,平时的负载比较高,大约在约为75-85%。有时系统会突然变慢,活跃会话数量猛增。由于应用没有做流量限制,因此某些模块速度变慢时,由于排队效应(关于排队效应,可以参考老白在本公众号早期发布的《探谈系统优化中的排队效应》)会有大量排队的业务流量涌入。该问题暂时无法通过应用优化来解决,希望数据库层面进行优化。一个共性问题是,故障发生时,V$SESSION_WAITS里可以看到大量的ENQ:TT-CONTENTION等待事件。这样一个问题我们该如何入手进行分析呢?应用架构缺乏流量控制,会导致某个应用变慢,就会有更多的会话涌入,从而消耗更多的系统资源,导致系统更慢。故障发生时V$SESSION_WAIT中发现大量enq: TT - contention 。第一步就需要分析是哪些会话在产生该等待,这些会话都在执行什么样的SQL。通过分析发现所有等待TT锁的都在执行同一个SQL,进一步检查发现正在执行该SQL的会话超过100个,故障发生时,活跃会话数是平时的数倍。进一步分析问题之前,我们需要了解一个知识点,那就是什么情况下会出现TT锁争用。enq: TT - contention等待最常见的场景有两个,一个是临时表访问,一个是排序等操作。一般临时表访问会话间相互影响不会很严重,出现TT锁争用的机会相对较小。我们先来看等待事件。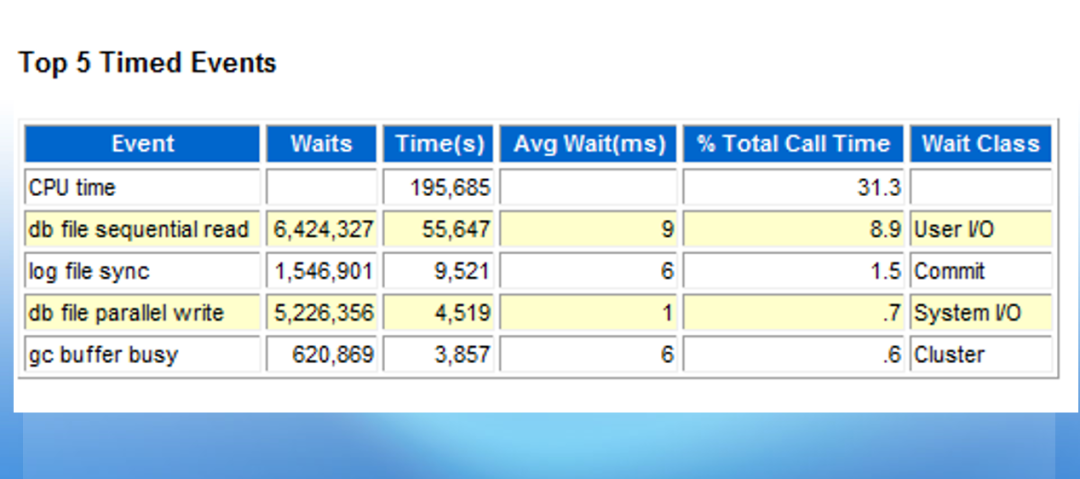
似乎TOP 5 event没有太大问题,TT锁等待也没有出现在TOP 5等待事件中。于是直接去查看锁的情况: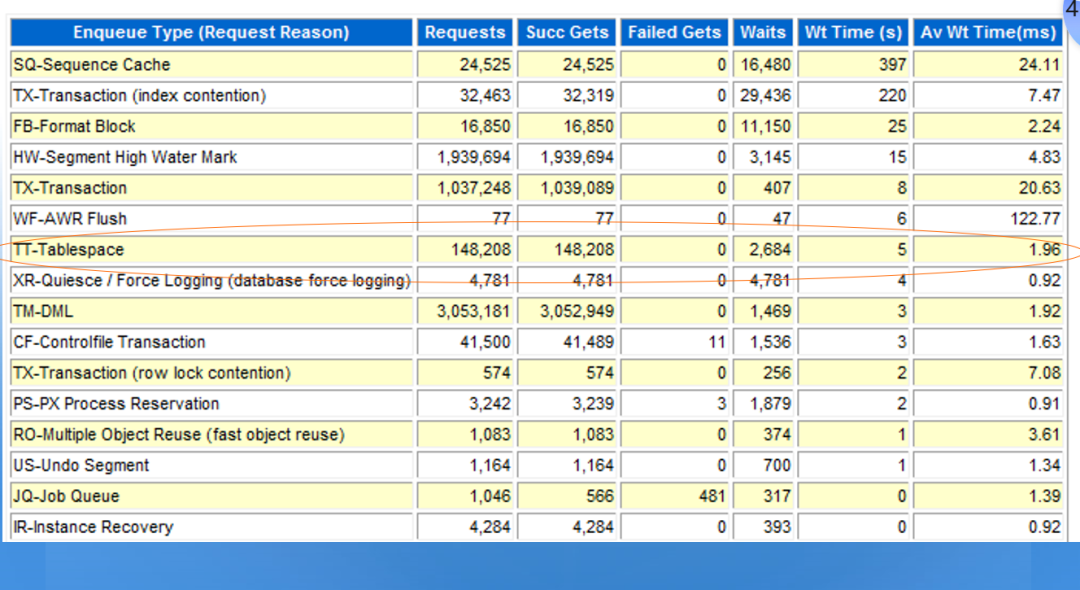
发现TT-TABLESPACE等待,TT锁主要集中在表空间上。这样和我们前面的推断有些关系了。排序操作会和临时表空间有关,出现类似的问题。于是我们可以直接去看PGA相关的章节,确认相关问题。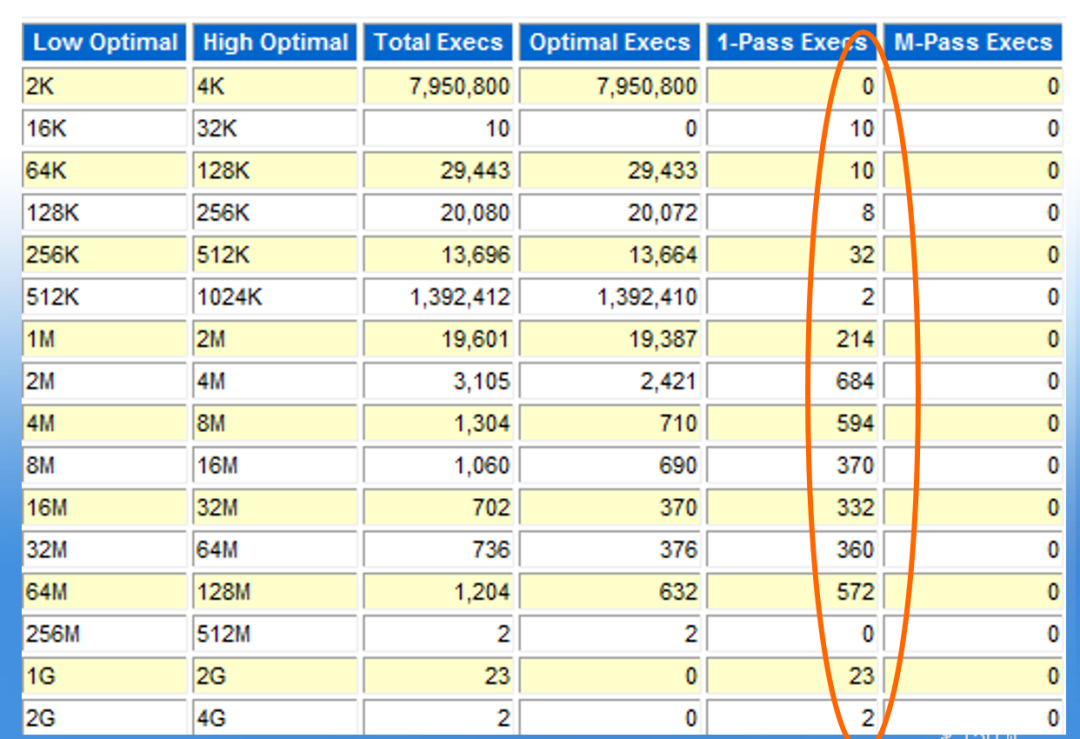
从上面我们可以看到,存在大量的1-pass的大排序操作。特别值得注意的是,很多十分小的排序也使用了硬盘排序,这是十分让人疑惑的。难道是出问题的SQL导致了这个问题?下一步我们就需要去分析相关的SQL语句了。
通过AWR报告对有问题时段和无问题时段的SQL进行分析,发现该语句在故障期间执行时间从100毫秒上升为400毫秒,CPU消耗变化不大。经过分析发现由于connect by子句导致优化器在估算排序区的时候无法准确预估,因此分配的排序区无法存放整个排序所需的数据,导致大量小排序使用磁盘排序。既然定位了问题,那么下一步如何解决这个问题就有点麻烦了。PGA自动管理是十分好的特性,可以有效的解决以前8I时sort_area_size设置的难题。但是这个特性的在当前版本的数据库上的缺陷导致了这个问题。直接关闭PGA自动管理并不是十分好的方法,有可能会引起一些其他的问题。幸亏workarea_size_policy可以会话级设置,于是我们建议开发商在执行类似SQL之前设置workarea_size_policy未手动管理,并在系统中设置合理的SORT_AREA_SIZE参数。开发商根据此建议修改了应用后,该问题彻底解决了。
最后修改时间:2020-05-12 08:13:56
文章转载自
白鳝的洞穴,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





