




本文将讨论数据库监控相关知识,详细介绍巨杉数据库的监控范畴及各项指标,并讲解如何与市面上流行的技术栈进行整合。希望通过阅读本篇文章,能帮助读者了解数据库监控的重要性以及实施要点,并且给读者在数据库监控实施中提供指导意见。

如果数据库系统没有监控,那么很难发现一些潜在的运行风险,无法保证数据库的持续稳定运行,等问题暴露出来再进行补救可能为时已晚。
有了数据库监控能够帮助数据库管理员(DBA)和系统管理员监控数据库环境,采集性能或状态等指标数据,当某些指标超过阈值时,生成告警通知管理员,帮助其快速排查故障问题以及了解数据库空间等使用情况,确保在问题发生前采取有效措施,保障数据的安全,保证服务的可靠。
操作系统
数据库系统是运行在操作系统之上的应用程序,操作系统与数据库密切相关。某些情况下数据库系统的问题是由操作系统引起的,不管是CPU负载过高、磁盘I/O过于繁忙或者内存不足,都会导致数据库服务性能下降,所以需要统一进行监控。
数据库状态
判断数据库是否正常的最基本方式就是看数据库状态,包括数据库服务进程是否存在、数据库能否正常提供服务等,可以通过连接测试判断能否对外服务,或通过简单增删改查操作判断能否提供正常服务。
数据库性能
数据库服务相对其它应用服务来说是比较消耗资源的,当操作不当或配置不合理时会导致资源占用严重,从而导致数据库性能下降。所以需要收集相关性能指标,明确指标的正常范围,设置不同级别的告警阈值,这些指标通常可以通过数据库快照、监控视图等采集,采集的频率要根据采集操作对数据库的影响以及系统的负载能力而定。
一、Prometheus + Grafana
Prometheus 是一套开源的系统监控报警框架。作为新一代的监控框架,Prometheus具有以下特点:
强大的多维数据模型(如时间序列数据通过metric名和键值对来区分)
灵活而强大的查询语句(PromQL)
不依赖与分布式存储,单个服务器节点是自治的
使用pull模式采集时间序列数据,使用push gateway方式推送时间序列数据
通过服务发现或静态配置发现目标
支持多种可视化图形界面
Prometheus组件与架构
Prometheus生态中包含多个组件,其中许多组件是可选的:
Prometheus server:用于采集和存储时间序列数据
Client library:用于生成metric并暴露给Prometheus server的客户端库
Push gateway:用于短期的jobs,这类 jobs可能在 Prometheus 来 pull 之前就消失了,所以需要向Prometheus server推送metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter
Exporters:用于暴露已有的第三方服务的metrics给Prometheus
Altermanager:主要实现告警功能。常见的方式有:电子邮件,webhook 等
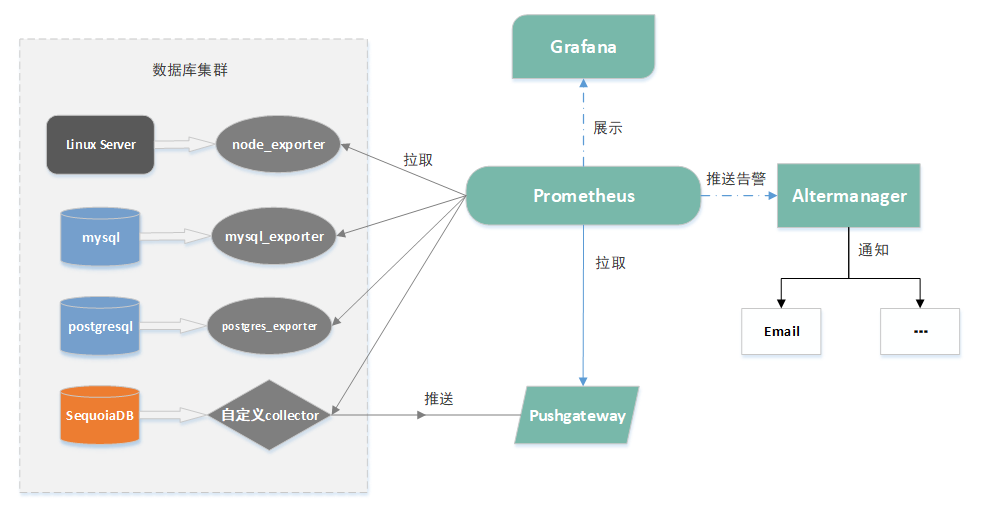
Prometheus定期从exporter中获取数据,要么直接获取,要么通过中介pushgateway获取短期。它在本地存储所有抓取的样本,并对这些数据运行定义好的规则,聚合和记录新的时间序列,或者生成警报。可以使用Grafana或其他API客户端来可视化收集的数据。
数据模型
Prometheus中每个时间序列是由metric名称和称为标签的键值对唯一标识的。
metric:指定被监控系统的一般特性(例如http_request_total,表示接收的http请求总数),metric名称可以包含ASCII字母和数字,以及下划线和冒号。且必须匹配正则表达式[a-zA-Z_:][a-zA-Z0-9_:]*。
标签:标识时间序列的不同维度(例如http_request_total{method=”Get”},表示http的GET请求数),查询语言允许基于这些维度进行过滤和聚合。
样本:实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。
格式:<metric name>{<label name>=<label value>, …},例如:api_http_requests_total{method="POST", handler="/messages"}
Metric类型
Prometheus提供了四种类型的度量:
Counter:一个累积度量,它表示一个单调递增的计数器,其值在重新启动时只能递增或重置为零。例如,您可以使用计数器来表示服务的请求、完成的任务或错误的数量。
Gauge:一个可以任意加减的度量值,用于测量当前内存使用情况或并发请求数量等。
Histogram:可理解为柱状图,可以对观察结果进行采样,分组及统计,通常用于请求持续时间、响应大小之类的指标。
Summary:与Histogram类似,它提供了观察值的count和sum功能,提供百分位的功能,即可以按百分比划分跟踪结果。
Exporter使用
$ cd home/sdbadmin$ wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.12.1/mysqld_exporter-0.12.1.linux-amd64.tar.gz$ tar -zxvf mysqld_exporter-0.12.1.linux-amd64.tar.gz
CREATE USER 'exporter'@'localhost' IDENTIFIED BY '123456' WITH MAX_USER_CONNECTIONS 3;GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
Note: 建议为用户设置一个最大连接限制,以避免在重负载情况下因为监控抓取使服务器超载。
3. 创建.my.cnf
[client]user=exporterpassword=123456
./mysqld_exporter --config.my-cnf=./.my.cnf
[sdbadmin@sdb1 ~]$ curl http://localhost:9104/metrics......# HELP mysql_global_status_connections Generic metric from SHOW GLOBAL STATUS.# TYPE mysql_global_status_connections untypedmysql_global_status_connections 13# HELP mysql_global_variables_max_connections Generic gauge metric from SHOW GLOBAL VARIABLES.# TYPE mysql_global_variables_max_connections gaugemysql_global_variables_max_connections 151......
6.修改Prometheus配置,prometheus.yml加入mysql节点
scrape_configs:- job_name: 'mysql'static_configs:- targets: ['192.168.23.11:9104']lables:instance: 'mysql_192.168.23.11'

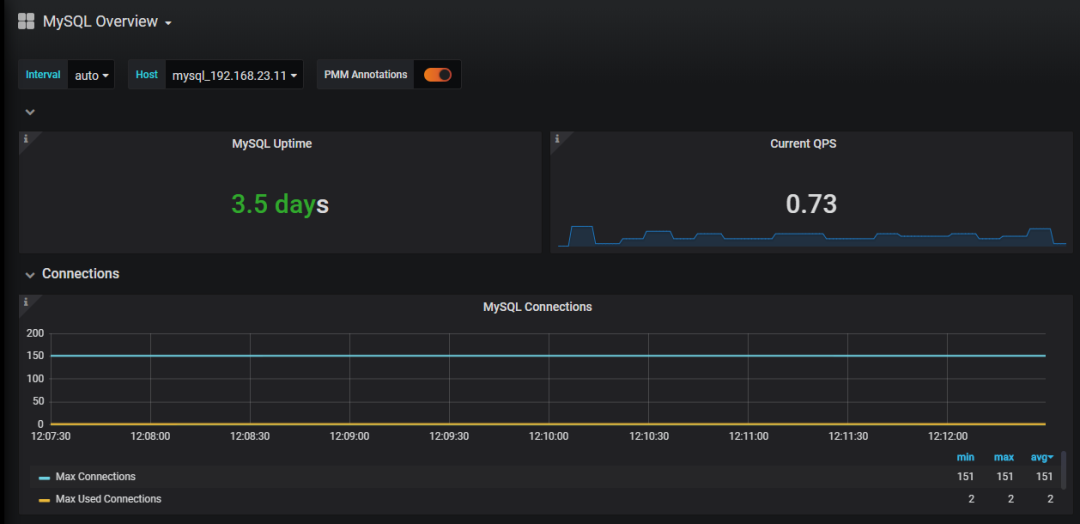
metrics已经被Prometheus采集到。
8. Grafana配置可视化
可以通过https://grafana.com/grafana/dashboards来查看已有的mysql仪表盘,选取合适的导入到grafana中。
自定义监控项与告警
自定义监控项
目前还没有公开可用的SequoiaDB_exporter,但我们可以借助Prometheus的客户端来实现自己的exporter,客户端语言支持Go、Java、Python、Ruby,本小节以Java客户端为例介绍如何自定义监控项。
1. 如果使用Maven,可以简单引入以下依赖:
<!-- The client --><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient</artifactId><version>0.8.1</version></dependency><!-- Exposition HTTPServer--><dependency><groupId>io.prometheus</groupId><artifactId>simpleclient_httpserver</artifactId><version>0.8.1</version></dependency><dependency><groupId>com.sequoiadb</groupId><artifactId>sequoiadb-driver</artifactId><version>3.0.1</version></dependency>
public class SdbNodeStatusCollector {public static void main(String[] args) throws IOException {// 自定义Collectornew Collector() {@Overridepublic List<MetricFamilySamples> collect() {List<MetricFamilySamples> mfs = new ArrayList<>();// metric名称为"sdb_node_status",并添加标签"host"和"port"来标识不同节点CounterMetricFamily statusMetric = new CounterMetricFamily("sdb_node_status", "SequoiaDB Node " +"Status", Arrays.asList("host", "port", "status"));mfs.add(statusMetric);// 连接巨杉数据库,访问节点健康快照Sequoiadb sequoiadb = null;try {sequoiadb = new Sequoiadb("192.168.23.10:11810", "", "");DBCursor snapCursor = sequoiadb.getSnapshot(Sequoiadb.SDB_SNAP_HEALTH, "", "", "");while (snapCursor.hasNext()) {BSONObject snap = snapCursor.getNext();if (snap.containsField("ErrNodes")) { // 挂掉的节点BasicBSONList errNodes = (BasicBSONList) snap.get("ErrNodes");for (Object errNode : errNodes) {String nodeFullName = (String) ((BSONObject) errNode).get("NodeName");String nodeHost = nodeFullName.split(":")[0];String nodePort = nodeFullName.split(":")[1];statusMetric.addMetric(Arrays.asList(nodeHost, nodePort, "Down"), -1);}} else {String nodeFullName = (String) snap.get("NodeName");String nodeHost = nodeFullName.split(":")[0];String nodePort = nodeFullName.split(":")[1];int statusVal = -1;String status = (String) snap.get("Status");// 四种节点状态,分别对应一个数值if ("Normal".equals(status)) {statusVal = 0;} else if ("Rebuilding".equals(status)) {statusVal = 1;} else if ("FullSync".equals(status)) {statusVal = 2;} else if ("OfflineBackup".equals(status)) {statusVal = 3;}statusMetric.addMetric(Arrays.asList(nodeHost, nodePort, status), statusVal);}}return mfs;} finally {if (sequoiadb != null) {sequoiadb.close();}}}}.register();// 通过1234端口导出metricsnew HTTPServer(1234);}}
# HELP sdb_node_status SequoiaDB Node Status# TYPE sdb_node_status countersdb_node_status{host="sdb4",port="11900",status="Down"} -1.0sdb_node_status{host="sdb1",port="11900",status="Down"} -1.0sdb_node_status{host="sdb1",port="11800",status="Normal"} 0.0sdb_node_status{host="sdb2",port="11800",status="Normal"} 0.0sdb_node_status{host="sdb3",port="11800",status="Normal"} 0.0......
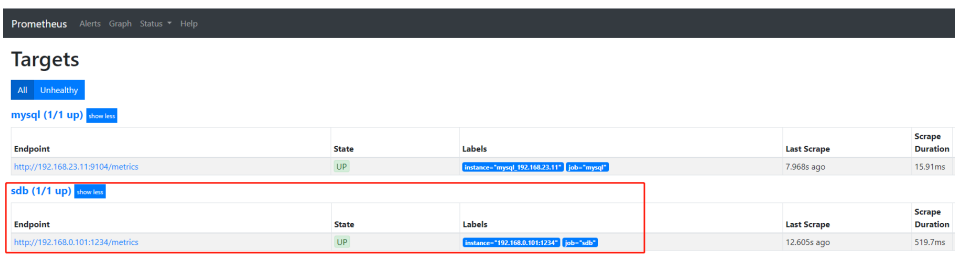
scrape_configs:...- job_name: 'sdb'static_configs:- targets: ['192.168.0.101:1234']
告警
Alertmanager 用于接收 Prometheus 发送的告警信息,它对告警信息进行去重、分组、路由到对应的接收端,包括邮箱、企业微信、钉钉等。这一节讲解利用AlertManager把节点状态异常的告警信息发送到邮箱。
1. 配置Altermanager,添加邮箱及路由信息:
$ cat alertmanager.ymlglobal:resolve_timeout: 5m# 邮箱SMTP服务器地址smtp_smarthost: 'smtp.xx.com:xxx'# 发送邮件的邮箱smtp_from: 'xxxx@xx.com'# 邮箱用户名smtp_auth_username: 'xxxx@xxx.com'# 邮箱密码或授权码smtp_auth_password: 'xxxxxxxxxxx'smtp_require_tls: falseroute:group_by: ['alertname']group_wait: 10sgroup_interval: 10srepeat_interval: 1hreceiver: 'default-receiver'receivers:- name: 'default-receiver'email_configs:# 接收邮件的邮箱地址- to: 'xxxx@xxx.com'
$ cat prometheus.ymlalerting:alertmanagers:- static_configs:- targets: ['localhost:9093']rule_files:- "node_status_rules.yml"
3.添加规则文件node_status_rules.yml:
groups:- name: test-rulerules:- alert: "节点状态异常报警"# 值非0,皆为异常状态expr: sdb_node_status != 0for: 1slabels:severity: warningannotations:summary: "节点名: {{$labels.host}}:{{$labels.port}}"description: "状态: {{ $labels.status }}"value: "{{ $value }}"
此时,告警相关配置已完成,调用altermanager和Prometheus的刷新接口使配置动态生效。
4. 观察Prometheus alter告警情况
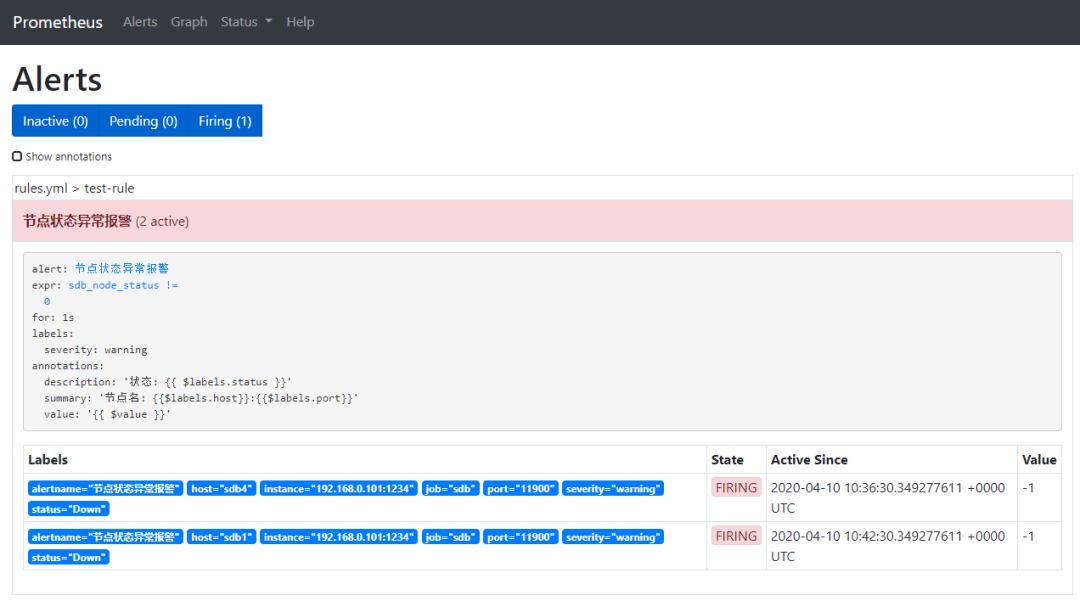
前面通过metrics的采集,我们已经知道有两个节点处于异常状态(sdb1:11900和sdb4:11900),Prometheus根据配置的告警规则,对这两个节点的异常情况发出了告警。
5. 邮件告警确认
登录接收告警信息的邮箱,可以看到已经收到了告警信息:
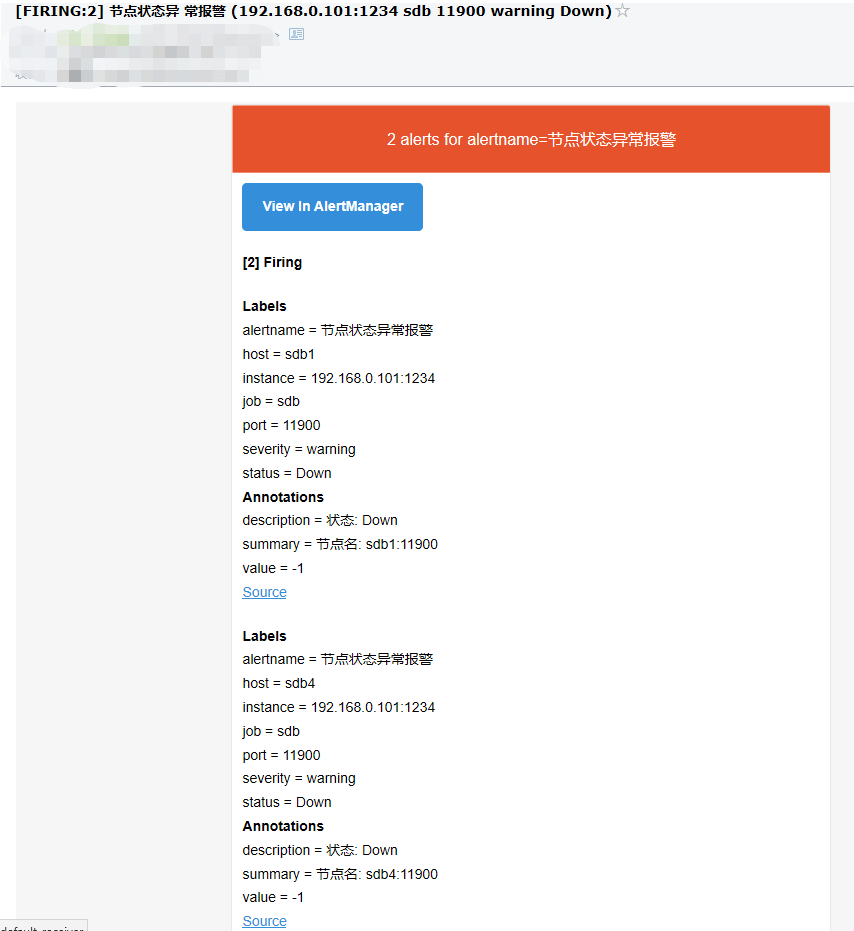
另外,Altermanager还支持定制化邮箱告警模板,用户可以根据需要调整内容格式,感兴趣的读者可以自行研究,此处不做介绍。
Zabbix是一个企业级的、开源的、分布式的监控套件,Zabbix可以监控网络和服务的监控状况,拥有灵活的告警机制,允许用户对事件发送基于Email等多种方式的告警。具备详细报表、图表的绘制等功能。监测对象可以是Linux或Windows服务器,也可以是路由器、交换机等网络设备,通过SNMP、Agent、JMX等方法提供对远程网络服务器监控、数据收集等功能。
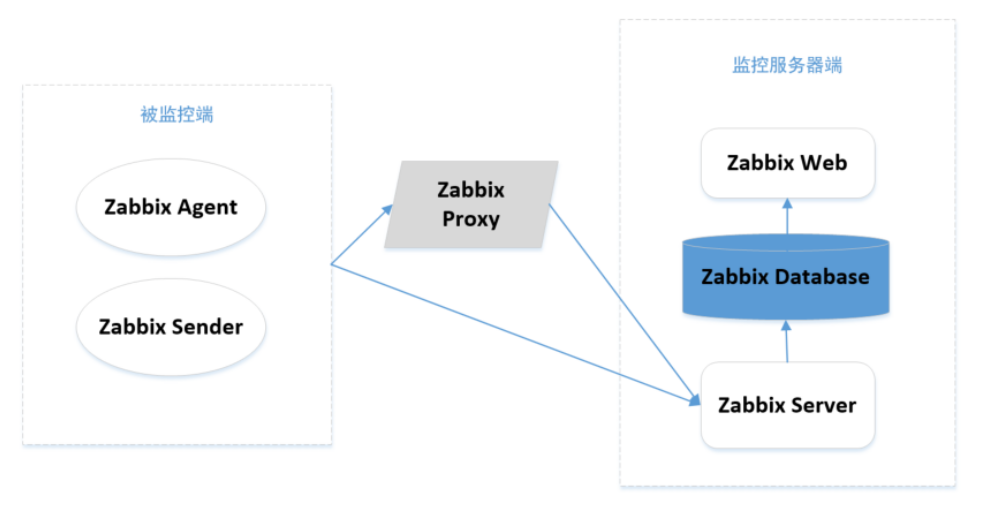
Zabbix组件与架构
zabbix agent:部署在被监控主机上,采集被监控主机的数据。 zabbix server:接收agent采集的数据,或者server主动去取数据。 zabbix database:提供数据存储功能,包括配置信息、采集的监控数据等。 zabbix web:提供web操作界面。 zabbix proxy:用于分布式监控环境,来减轻server端的压力,proxy收到数据最后统一发送给server。 zabbix_sender:用于主动发送数据给server或者proxy。
2. Zabbix的监控架构:
Zabbix采集监控项
<dependency><groupId>io.github.hengyunabc</groupId><artifactId>zabbix-sender</artifactId><version>0.0.5</version></dependency>
2. 下面代码以“节点状态”指标为例,描述了如何采集与发送指标:
public class ZabbixTest {public static void main(String[] args) throws IOException {//zabbix 服务器地址String zabbixHost = "192.168.23.10";//zabbix 服务器端口Integer zabbixPort = 10051;//指标名称String key = "sdb_node_status";//连接 zabbixZabbixSender sender = new ZabbixSender(zabbixHost, zabbixPort);// 连接巨杉数据库,访问节点健康快照Sequoiadb sequoiadb = null;try {sequoiadb = new Sequoiadb("192.168.23.10:11810", "", "");DBCursor snapCursor = sequoiadb.getSnapshot(Sequoiadb.SDB_SNAP_HEALTH, "", "", "");while (snapCursor.hasNext()) {BSONObject snap = snapCursor.getNext();if (snap.containsField("ErrNodes")) { // 挂掉的节点BasicBSONList errNodes = (BasicBSONList) snap.get("ErrNodes");for (Object errNode : errNodes) {String nodeFullName = (String) ((BSONObject) errNode).get("NodeName");String nodeHost = nodeFullName.split(":")[0];String nodePort = nodeFullName.split(":")[1];DataObject data = new DataObject(System.currentTimeMillis()/1000, nodeHost,key + "[" + nodePort + "]", "-1");//指标发送sender.send(data);}} else {String nodeFullName = (String) snap.get("NodeName");String nodeHost = nodeFullName.split(":")[0];String nodePort = nodeFullName.split(":")[1];int statusVal = -1;String status = (String) snap.get("Status");// 四种节点状态,分别对应一个数值if ("Normal".equals(status)) {statusVal = 0;} else if ("Rebuilding".equals(status)) {statusVal = 1;} else if ("FullSync".equals(status)) {statusVal = 2;} else if ("OfflineBackup".equals(status)) {statusVal = 3;}DataObject data = new DataObject(System.currentTimeMillis()/1000, nodeHost,key + "[" + nodePort + "]", String.valueOf(statusVal));//指标发送sender.send(data);}}} finally {if (sequoiadb != null) {sequoiadb.close();}}}}
添加主机
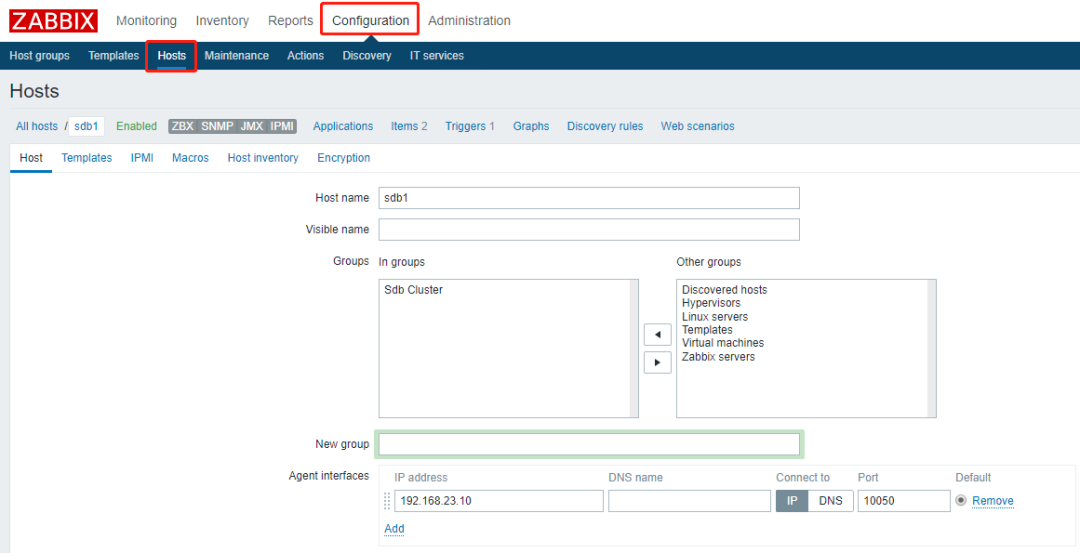
为主机添加监控项
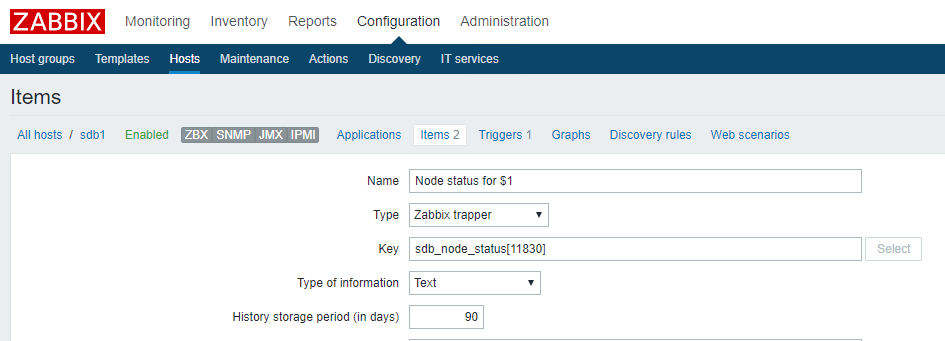
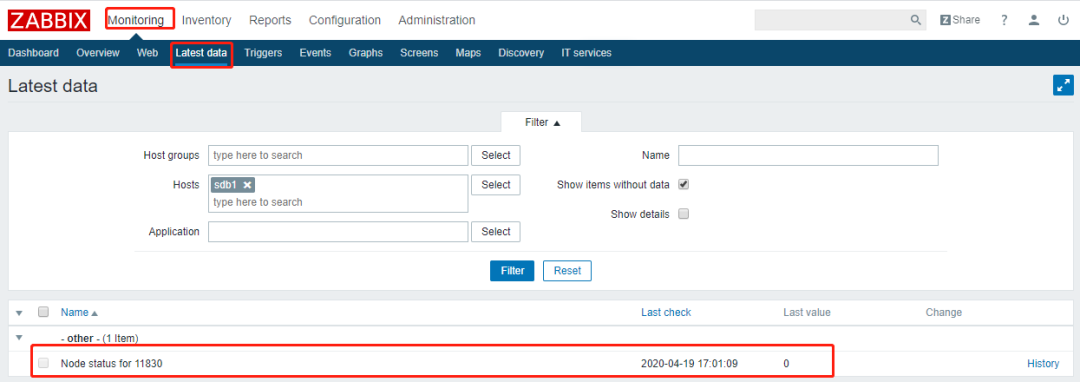
Zabbix监控告警
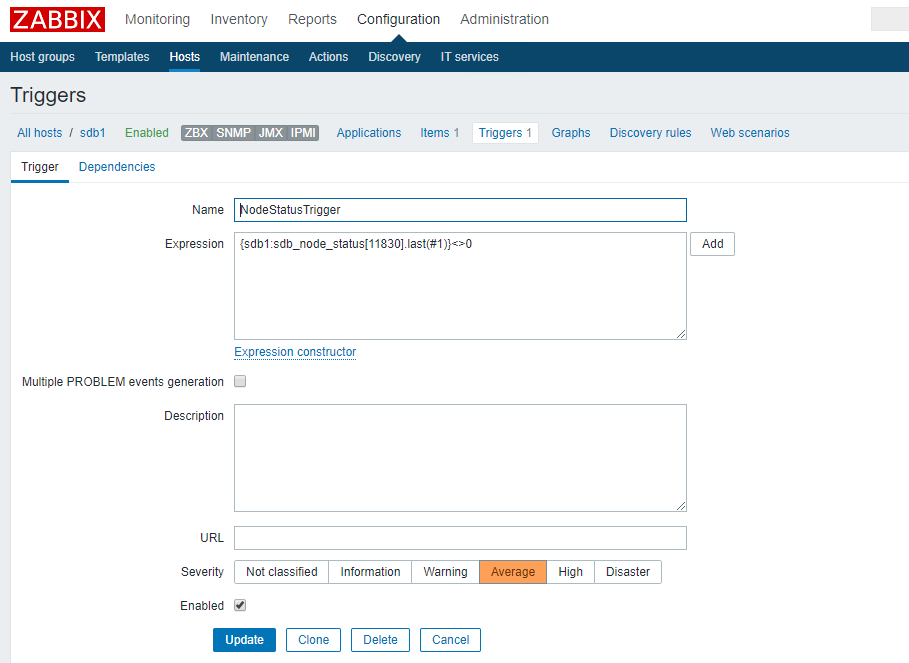
1. 为主机“sdb1”添加触发器
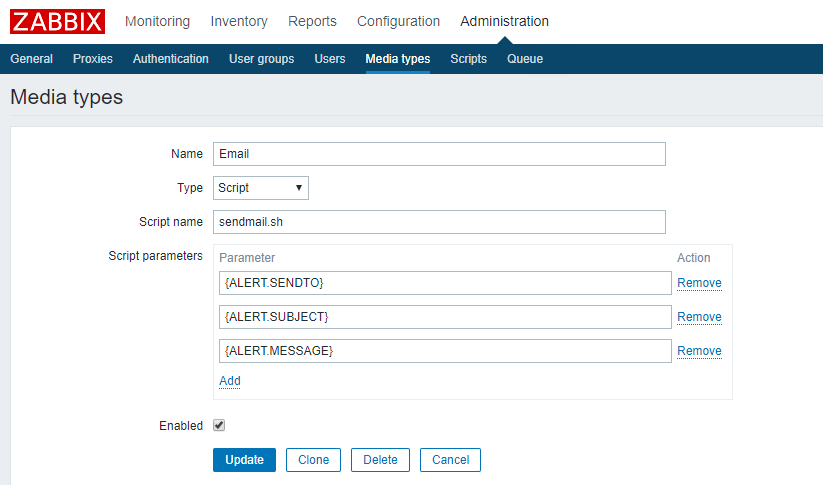
#!/bin/bashto=$1subject=$2context=$3tmp_file=/tmp/mail.txtecho "$3" > $tmp_filedos2unix -k $tmp_filemail -s "$subject" "$to" < $tmp_file
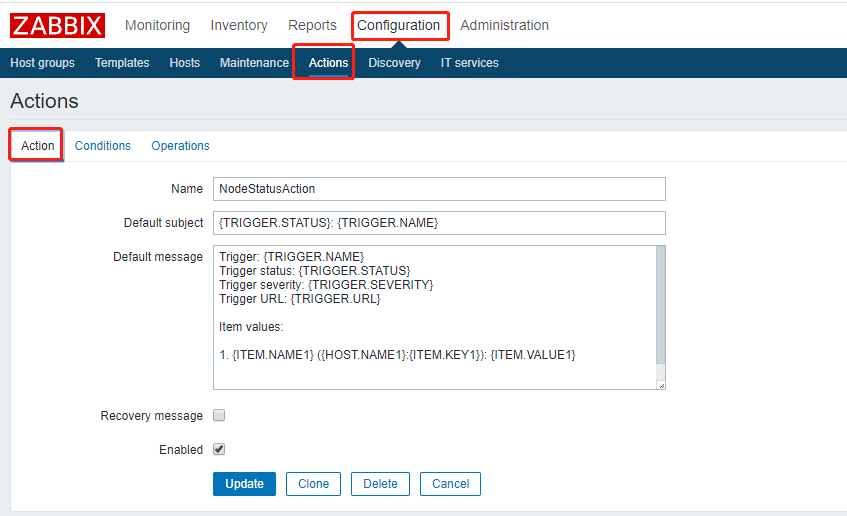
3. 配置“动作”
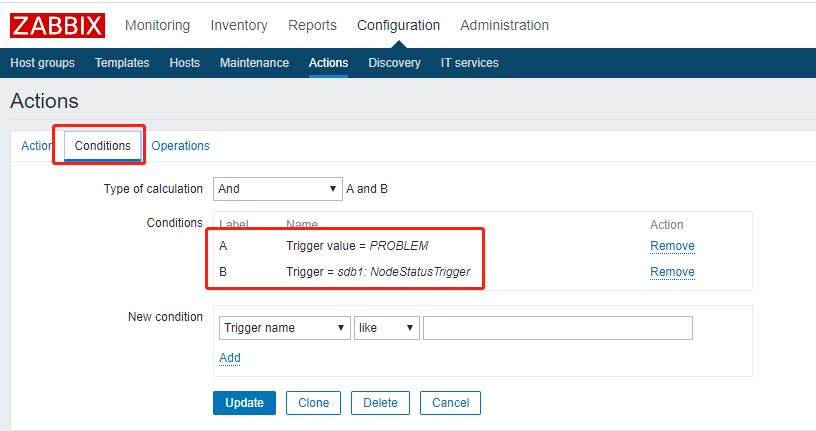
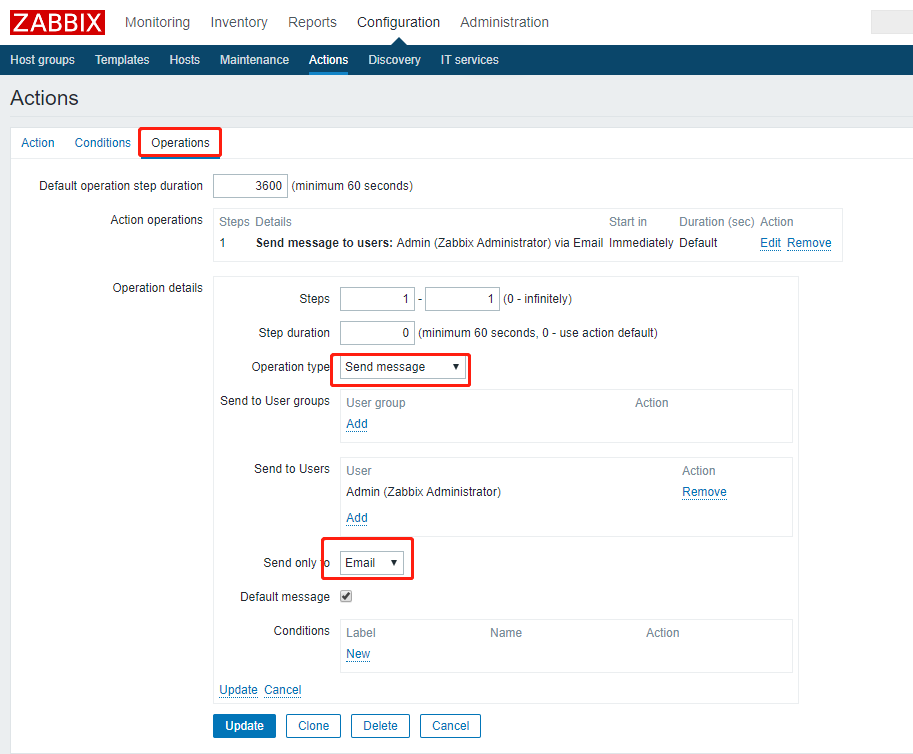
4. 手动停止节点“sdb1:11830”,并重新运行监控采集程序
[sdbadmin@sdb1 ~]$ sdbstop -p 11830Terminating process 10665: sequoiadb(11830)DONETotal: 1; Success: 1; Failed: 0
5. 验证接收邮件
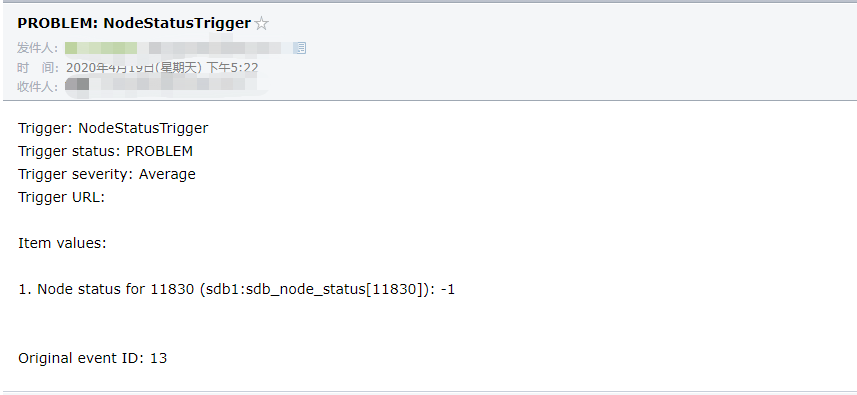
一、重要监控指标
操作系统
内存
mem.memtotal:内存总大小
mem.memused:使用了多少内存 = memtotal-memfree
mem.memused.percent:使用的内存占比
mem.memfree
mem.memfree.percent
mem.swapused:使用了多少swap
mem.available:可用内存
mem.buff/cache
I/O
disk.io.read_bytes:单位是byte的数字
disk.io.write_bytes:单位是byte的数字
disk.io.await
disk.io.util:是个百分数,比如56.43,表示56.43%
磁盘使用量
df.bytes.free:磁盘可用量,int64
df.bytes.free.percent:磁盘可用量占总量的百分比,float64,比如32.1
df.bytes.total:磁盘总大小,int64
df.bytes.used:磁盘已用大小,int64
df.bytes.used.percent:磁盘已用大小占总量的百分比,float64
df.inodes.total:inode总数,int64
df.inodes.free:可用inode数目,int64
df.inodes.free.percent:可用inode占比,float64
df.inodes.used:已用的inode数据,int64
df.inodes.used.percent:已用inode占比,float64
网络
net.if.in.bytes
net.if.in.packets
net.if.out.bytes
net.if.out.packets
net.if.total.bytes
net.if.total.packets
CPU
cpu.usercpu.system
cpu.nice
cpu.idle
cpu.iowait
cpu.busy:与cpu.idle相对,它的值等于100减去cpu.idle
SequoiaDB集群
集群状态
> var db=new Sdb('localhost', 11810);> db.snapshot(SDB_SNAP_DATABASE, {}, {'ErrNodes':1});{"ErrNodes": [{"NodeName": "sdb1:11900","GroupName": "group4","Flag": -79,"ErrInfo": {}},{"NodeName": "sdb4:11900","GroupName": "group4","Flag": -13,"ErrInfo": {}}]}
集群连接数量
协调节点对外服务的连接数据量,通过协调节点的数据库快照获取:
> var db=new Sdb('localhost', 11810);> db.snapshot(SDB_SNAP_DATABASE, {}, {'TotalNumConnects':1});{"TotalNumConnects": 2}
用户会话数
所有节点的会话数量总和,协调节点会话快照列出当前数据库中所有的用户和系统会话,类型为'ShardAgent'的会话一般来说是用户请求由协调节点传入数据节点:
> var db=new Sdb('localhost', 11810);> db.snapshot(SDB_SNAP_SESSIONS, {'Type':'ShardAgent'});
用户活动会话数
所有节点的会话数量总和,协调节点会话快照列出当前数据库中所有的用户和系统会话,会话状态分为:Creating(创建状态)、Running(运行状态)、Waiting(等待状态)、Idle(线程池待机状态)、Destroying(销毁状态),过滤出Running状态即可获得活动会话数:
> var db=new Sdb('localhost', 11810);> db.snapshot(SDB_SNAP_SESSIONS, {'Type':'ShardAgent','Status':'Running'});
超过N秒的会话数量
找到当前还在运行的执行时间超过N秒的会话,列出这样的长会话总和数量:
> var db=new Sdb('localhost', 11810);> db.snapshot(SDB_SNAP_SESSIONS, {'Status':'Running'});
通过协调节点的会话快照,过滤出处于运行状态的会话,取出字段‘LastOpBegin’的时间值T1,与当前时间戳T2求差值(Td=T2-T1),如果Td>N秒,则记为超时会话,最后统计出超时的会话总数。
最慢查询耗时
找到当前还在运行的执行时间最长的会话,计算出持续运行秒数:
> var db=new Sdb('localhost', 11810);> db.snapshot(SDB_SNAP_SESSIONS, {'Status':'Running','LastOpType':'Query'});
通过协调节点的会话快照,过滤出处于运行状态的查询类会话,根据字段‘LastOpBegin’的值进行正序排序后,取第一条会话记录,则为执行时间最长的会话,再用这条记录的‘LastOpBegin’值与当前时间戳求差值,得出持续运行秒数。
最长事务LSN差异
找到当前尚未提交的事务中BeginTransLSN最小的事务,计算出BeginTransLSN与节点的snapshot(6)里边的CurrentLSN差异。
1.连接协调节点访问事务快照:
> var db=new Sdb('localhost', 11810);> db.snapshot(SDB_SNAP_TRANSACTIONS, {},{'NodeName':1,'BeginTransLSN':1});...{"NodeName": "sdb01:11840","BeginTransLSN": 50516117620}...
省略了部分输出,以其中一条事务记录举例,可以发现事务位于数据节点sdb01:11840上。
2.直连数据节点访问数据库快照:
> var db=new Sdb('sdb01', 11840);> db.snapshot(SDB_SNAP_DATABASE, {},{'CurrentLSN':1});{"CurrentLSN": {"Offset": 50516136500,"Version": 6}}
计算CurrentLSN.Offset-BeginTransLSN=18880,得出LSN差异。可以设置阈值,比如超过100M时告警。
数据读与索引读比值
采集周期内,平均每秒,数据读次数除以索引读次数的比值(索引读为0时,视为索引读1次)。数据读和索引读的值分别取自协调节点数据库快照的“TotalDataRead”和“TotalIndexRead”,下面说明每个周期采集数据计算比值的方法:
1.首个周期只进行数据采集,不进行比值计算
> var db=new Sdb('localhost', 11810);> db.snapshot(SDB_SNAP_DATABASE, {},{'TotalDataRead':1,'TotalIndexRead':1});{"TotalDataRead": 827463384342, // 保存当前数据读TDR1"TotalIndexRead": 825728173290 // 保存当前索引读TIR1}
2.下个周期时,采集数据并计算比值
> var db=new Sdb('localhost', 11810);> db.snapshot(SDB_SNAP_DATABASE, {},{'TotalDataRead':1,'TotalIndexRead':1});{"TotalDataRead": 827522667331, // 保存当前数据读TDR2"TotalIndexRead": 825787340511 // 保存当前索引读TIR2}
通过计算TDR2-TDR1得到本周期内的数据读为59282989,计算TIR2-TIR1得到本周期内索引读为59167221,假设周期为1分钟,那么最后得到每秒的数据读与索引读比值为:59282989/59167221/60。
用户可以设置告警阈值,比如比值大于1000则告警。
SequoiaDB数据节点
节点状态
> var db=new Sdb('localhost', 11900);> db.snapshot(SDB_SNAP_DATABASE, {},{'Status':1});
用户会话数
> var db=new Sdb('localhost', 11900);> db.snapshot(SDB_SNAP_SESSIONS, {'Type':'ShardAgent'});
用户活动会话数
> var db=new Sdb('localhost', 11900);> db.snapshot(SDB_SNAP_SESSIONS, {'Type':'ShardAgent','Status':'Running'})
主备节点LSN差异
> var db=new Sdb('localhost', 11810);> db.listReplicaGroups();
数据读与索引读比值
日志空间使用比例
> var db=new Sdb('localhost', 11900);> db.snapshot(SDB_SNAP_DATABASE, {},{'BeginLSN':1,'CurrentLSN':1});{"BeginLSN": {"Offset": 50439260196,"Version": 4},"CurrentLSN": {"Offset": 50516492304,"Version": 6}}
3.0之前版本,可以连接每台服务器的sdbcm节点,调用listNodes()方法得到配置参数(当前生效的):
> var oma=new Oma('localhost', 11790);> oma.listNodes({'role':'data','svcname':'11900','expand':true})
3.0版本之后,快照增加了SDB_SNAP_CONFIGS,可以获取每个节点当前生效的参数值
> var db=new Sdb('localhost', 11900);> db.snapshot(SDB_SNAP_CONFIGS, {}, {'logfilesz':1,'logfilenum':1})
诊断日志监控
原生日志 | 关键字 | 涵义 |
Start up from crash, data is abnormal | 空格crash逗号 | SDB没有正常关闭,本次启动为崩溃恢复。需要进行本地恢复或者全量同步。 |
The db data is abnormal, need to synchronize full data | synchronize空格full | 开启全量同步。 |
Invalid storage unit size | Invalid空格storage | 非法文件大小。可能造成启动不成功。触发原因一般为创建文件阶段异常退出。 |
Consult failed[变量], need to synchronize full data | Consult空格failed | 协商失败,极有可能出现全量同步 |
SEVERE | SEVERE | SDB中最高级别错误日志,一般都是不可恢复错误引起。 |
2.普通警告
原生日志 | 关键字 | 涵义 |
failed to connect remote[变量] | failed空格to空格connect | 无法连接对端节点 |
vote: [变量] alive break | alive空格break | 心跳中断 |
vote:remove lsn[变量] higher(or equal) than local lsn[变量], we chage to secondary | higher(or空格equal) | 数据节点双主,本节点降备 |
Begin sync control…[expectLSN: 变量,…] | Begin空格sync空格control | 开启同步控制,存在至少一个备节点同步数据速度过慢 |
MySQL节点
节点状态
如果MySQL节点可以正常连接,并且可以返回查询结果,则认为mysql节点状态正常。
可使用简单的查询语句“select 1”进行验证。
慢查询耗时
1. 找到当前还在运行的执行时间最长的会话,计算出持续运行秒数
mysql> select * from information_schema.`PROCESSLIST` where info is not null;+----+------+-----------------+------+---------+------+------------+-----------------------------------------------------------------------+| ID | USER | HOST | DB | COMMAND | TIME | STATE | INFO |+----+------+-----------------+------+---------+------+------------+-----------------------------------------------------------------------+| 9 | root | localhost:51360 | NULL | Query | 1 | User sleep | select count(*) from information_schema.PROCESSLIST || 8 | root | localhost:51358 | NULL | Query | 0 | executing | select * from information_schema.`PROCESSLIST` where info is not null |+----+------+-----------------+------+---------+------+------------+-----------------------------------------------------------------------+2 rows in set (0.00 sec)
可以通过‘Time’列得知语句运行时间,找到超过阈值的语句。
2. 开启慢查询日志,监控慢查询语句
查看慢查询日志存放路径(slow_query_log_file),可以根据需要进行修改
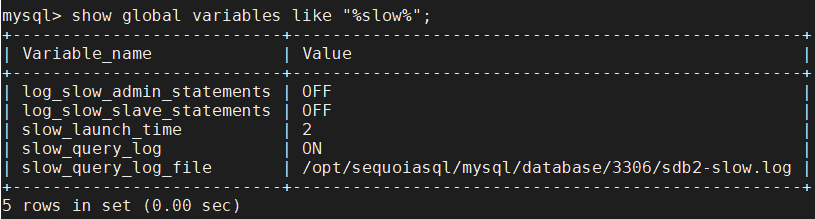
开启慢查询日志
mysql> set global slow_query_log=on;
设置慢查询时间阈值,执行时间超过阈值的SQL都会被记录到慢查询日志中
mysql> set global long_query_time=1;
慢查询日志格式
# Time: 2020-04-07T15:32:04.793557Z# User@Host: root[root] @ localhost [127.0.0.1] Id: 7# Query_time: 12.001431 Lock_time: 0.000213 Rows_sent: 1 Rows_examined: 2SET timestamp=1586273524;select sleep(12),count(*) from information_schema.PROCESSLIST;
活动连接数
所有不处于空闲状态的连接的总和数量:
mysql> show global status like 'Threads_running';
总连接数
所有连接数量总和,采集方法:
mysql> show global status like 'Threads_running';
PostgrSQL节点
节点状态
如果PG节点可以正常连接,并且可以返回查询结果,则认为PG节点状态正常。
可使用简单的查询语句“select 1”进行验证。
总连接数
所有连接数量总和,采集方法:
mysql> select count(1) from pg_stat_activity;
慢查询耗时
找到当前还在运行的执行时间最长的会话,计算出持续运行秒数:
pg=# select now()-query_start as time,state,query from pg_stat_activity where state <> 'idle';
可以判断time列的值是否超过阈值,超过阈值的则记为慢查询。
二、其他监控指标
范畴 | 指标名 | 指标性质 | 是否直接采集 | Sdb shell采集方法 | 对应snapshot指标名 | 指标含义说明 |
集群
| 每秒数据读次数 | 性能 | 需计算avg | db.snapshot(6) | TotalDataRead | 采集周期内,平均每秒数据读请求 |
每秒索引读次数 | 性能 | 需计算avg | db.snapshot(6) | TotalIndexRead | 采集周期内,平均每秒索引读请求 | |
每秒数据写次数 | 性能 | 需计算avg | db.snapshot(6) | TotalDataWrite | 采集周期内,平均每秒数据写请求 | |
每秒索引写次数 | 性能 | 需计算avg | db.snapshot(6) | TotalIndexWrite | 采集周期内,平均每秒索引写请求 | |
每秒更新记录条数 | 性能 | 需计算avg | db.snapshot(6) | TotalUpdate | 采集周期内,平均每秒更新记录数量 | |
每秒删除记录条数 | 性能 | 需计算avg | db.snapshot(6) | TotalDelete | 采集周期内,平均每秒删除记录数量。一般交易系统的数据模型和数据处理逻辑,是不需要delete数据的。所以需要告警阈值。 | |
每秒插入记录条数 | 性能 | 需计算avg | db.snapshot(6) | TotalInsert | 采集周期内,平均每秒插入记录数量 | |
每秒复制更新记录条数 | 性能 | 需计算avg | db.snapshot(6) | ReplUpdate | 采集周期内,平均每秒复制更新记录数量 | |
每秒复制删除记录条数 | 性能 | 需计算avg | db.snapshot(6) | ReplDelete | 采集周期内,平均每秒复制删除记录数量 | |
每秒复制插入记录条数 | 性能 | 需计算avg | db.snapshot(6) | ReplInsert | 采集周期内,平均每秒复制插入记录数量 | |
每秒查询命中记录条数 | 性能 | 需计算avg | db.snapshot(6) | TotalSelect | 采集周期内,平均每秒所有查询命中记录数量 | |
每秒读记录条数 | 性能 | 需计算avg | db.snapshot(6) | TotalRead | 采集周期内,平均每秒所有查询读取过的记录数量 | |
每秒读记录数比例 | 性能 | 需计算avg | 每秒读记录数 每秒查询命中记录数 | 无 | 采集周期内,平均每秒,读记录数除以查询命中记录数的比值。交易场景下,期望两者基本相同,比值不应该有较大差异,如果差异很大,一般说明发生了表扫描。 | |
节点 | 数据状态 | 状态 | 是 | db.snapshot(12) | DataStatus | 如果数据状态为“Normal”,则监控值为0,无需告警。如果数据状态为其他状态,则对应的监控值为“Repairing”:1,“Fault”:2,均需告警。 |
服务状态 | 状态 | 是 | db.snapshot(12) | ServiceStatus | 如果节点服务状态为 true,则监控值为0,无需告警。如果为false,则监控值为1,需要告警。 | |
节点综合状态 | 状态 | 根据三个状态计算 | db.snapshot(12) | 三个状态联合判断:Status、DataStatus、ServiceStatus | 节点异常的判断条件: 1. 无法连接 2. 或者 Status 不是 Normal 3. 或者 DataStatus 不是 Normal 4. 或者 ServiceStatus 不是 true | |
是否主节点 | 状态 | 是 | db.snapshot(12) | IsPrimary | 该节点是否主节点。0代表主节点,1代表从节点。 | |
是否发生主备切换 | 状态 | 需对比上轮值 | db.snapshot(12) | IsPrimary | 对比上轮采集值,如果主备角色有变化,则监控值为1,则意味着发生了主备角色切换,需要告警.如果主备角色没有变化,则减控制为0,正常结果,无需告警。 | |
与主节点数据差异 | 性能 | 是 | db.snapshot(12) | DiffLSNWithPrimary | 跟主节点之间的LSN差异超过100MB就告警。 | |
分区 | 是否有主 | 状态 | 是 | db.list(SDB_LIST_GROUPS) | PrimaryNode | 根据db.list(SDB_LIST_GROUPS)输出结果中的PrimaryNode来判断,如果有主节点,则用0代表分区内有主节点,否则就用1代表分区内没有主节点。如果采集出现错误,则用2代表其他错误情况。 |
监控作为底层基础设施的一环,是保障生产环境服务稳定性不可或缺的一部分,通过监控和告警手段可以有效地发现线上问题并及时解决,甚至可以通过故障自动诊断、自动处理等手段实现解决,数据库开发和运维人员能及时有效地发现服务运行的异常,从而更有效率地排查和解决问题。
 往期技术干货
往期技术干货巨杉Tech | SequoiaDB高可用原理详解
巨杉Tech | 分布式数据库负载管理WLM实践
巨杉Tech | 巨杉数据库的HTAP场景实践
巨杉Tech | SequoiaDB SQL实例高可用负载均衡实践
巨杉Tech | 并发性与锁机制解析与实践
巨杉Tech | 几分钟实现巨杉数据库容器化部署
巨杉Tech | “删库跑路”又出现,如何防范数据安全风险?
巨杉Tech | 分布式数据库千亿级超大表优化实践
社区分享 | SequoiaDB + JanusGraph 实践
巨杉Tech | 巨杉数据库的并发 malloc 实现
巨杉数据库无人值守智能自动化测试实践



