




MatrixKV是ATC20的一篇文章,主要研究方向是使用NVM优化LSM-tree数据结构,从论文标题就可以看出,优化效果主要有两点:
- Reducing Write Stalls(减少写停顿);
- Reducing Write Amplification(减少写放大)。
论文地址:https://www.usenix.org/conference/atc20/presentation/yao
论文主要是探讨LSM-tree结构的写停顿问题,特别是在写操作密集、写流量较大的应用场景,可能会导致少数请求延迟较大,出现长尾延迟大的问题,对一些即时性较强的业务影响较大。
背景
论文先分析了LSM-tree具有写停顿和写放大问题。
写放大问题

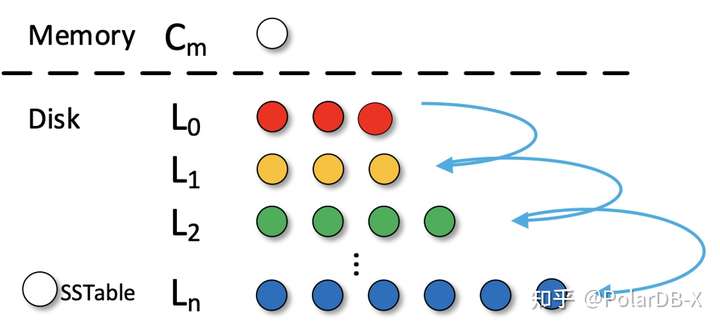
LSM-tree结构的写放大问题是老生常谈的原因了。LSM-tree将数据划分成多层,为了保证每层的数据有序性,有后台Compaction线程进行多个SSTable文件(常见LSM-tree的键值存储数据库,LevelDB、RocksDB等在磁盘的数据结构)合并,将上层的数据迁移到下层,让数据规模可以逐步扩展,每次Compaction都会产生写放大,随着层数增多,写放大也会越大。
写停顿问题
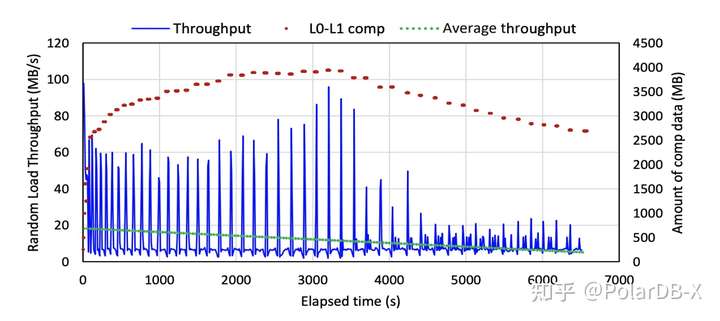
论文测试了RocksDB在持续随机写负载下的性能,如下图,蓝色是实时性能,红色是L0-L1 Compaction的数据量,绿色是平均性能。蓝色曲线表明RocksDB的性能抖动厉害,每隔一会就会出现性能低谷,并且低谷次数和L0-L1 Compaction的次数较接近,这种性能波动较大的情况像是阻塞了一样,称为写停顿。

分析下出现写停顿的原因,首先有三个前提:
- L0层的每个SSTable数据范围是重叠的,主要是为了优化compaction,让每层的数据能够逐步扩展,如果L0层范围不重叠,意味着每次MemTable从内存flush都要和整层L0进行合并,数据排序的效果较差。
- 前台请求写入的性能一定是快于后台合并,因为前台请求写入日志然后在内存组织,最后flush到L0层即完成,而后台compaction需要保持每层的数据不超过阈值,开销较大,所以为了防止L0层的数据无限膨胀,LevelDB、RocksDB都会通过L0的文件个数来对前台请求做出限制,RocksDB中主要有三个参数:level0_file_num_compaction_trigger(4)、level0_slowdown_writes_trigger(20)、level0_stop_writes_trigger(36)。当L0层的文件达到level0_file_num_compaction_trigger,则开始进行L0-L1层的Compaction;当L0层文件达到level0_slowdown_writes_trigger,则减缓前台写请求,对请求进行限流;当L0层文件个数达到level0_stop_writes_trigger,则阻塞前台写请求。
- L0层和L1层进行compaction通常会选取L0-L1层的所有文件,因为大多数情况下的负载key是随机的,所以L0层的文件范围会重叠,且L0的每个文件范围通常会覆盖L1的所有文件。
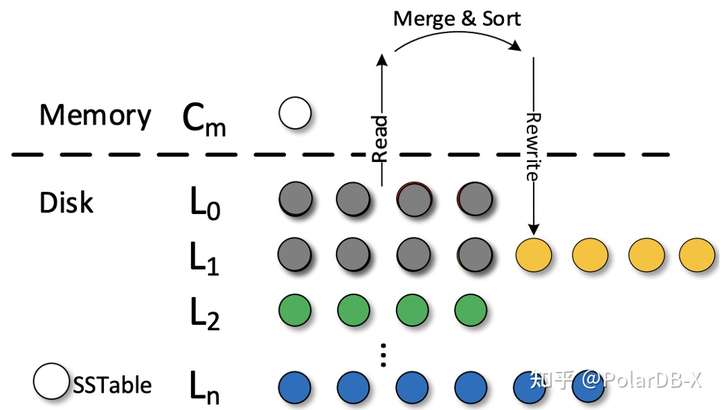
如下图所示,当L0层和L1层进行Compaction时,选取L0-L1层所有文件进行Compaction,一次Compaction的总数据量达到3-4GB,且RocksDB支持MVCC,每次Compaction完才会进行版本更迭,一次性删除L0的所有文件,这个过程可以看成L0层文件写满,限制前台写请求,Compaction选取L0-L1层所有文件进行合并,合并完后L0的文件变为0,如果写负载较密集的情况下,这是一个突变的值,用这个值来限制前台写请求,就会产生写停顿的情况,前台写请求很快写满L0层,然后前台写性能就停顿了,等L0-L1层Compaction完,L0的文件又变成0,L0层空了,前台写性能又很快,写满L0层后,又阻塞了……

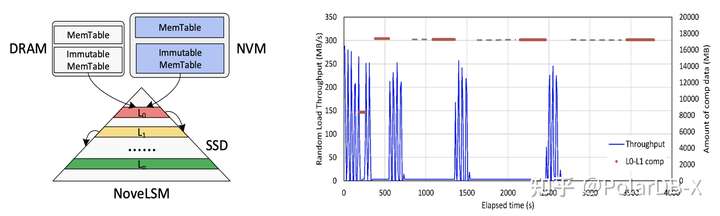
论文也对NoveLSM(ATC-2018)做背景测试,如下图,NoveLSM将MemTable存储到NVM中,同时加大MemTable的大小,会导致Flush到L0层的文件变大,因此L0-L1层进行Compaction的数据量进一步增大,写停顿问题更加严重。

设计
MatrixKV的整体架构如下图所示,采用DRAM-NVM-SSD三层结构,使用混合存储结构的原因有三点:1、未来几年NVM无法取代SSD;2、相比于DRAM,NVM性能差距大;3、兼顾成本和性能。

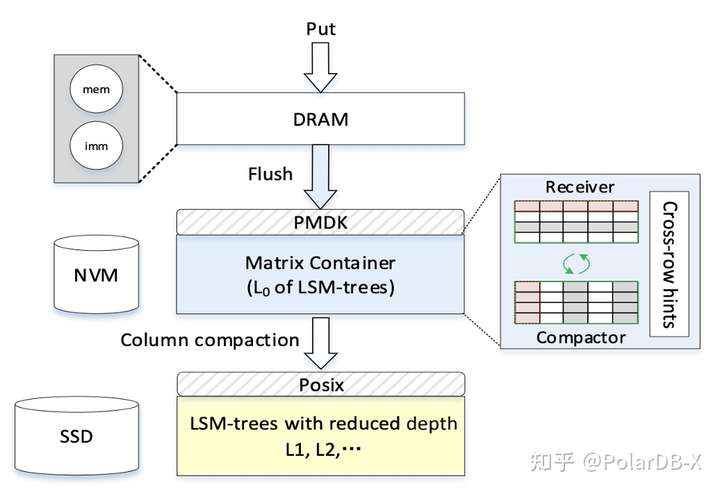
DRAM存储原来的MemTable、ImmuTable,和RocksDB一样。 NVM存储L0层的数据,同时设计了新的数据结构Matrix Container,用于解决写停顿问题。 SSD存储L1、L2等下层的数据,符合LSM-tree下层数据冷、量大的特性。 MatrixKV提出了四个设计点。
设计点1:L0层新结构-Matrix Container
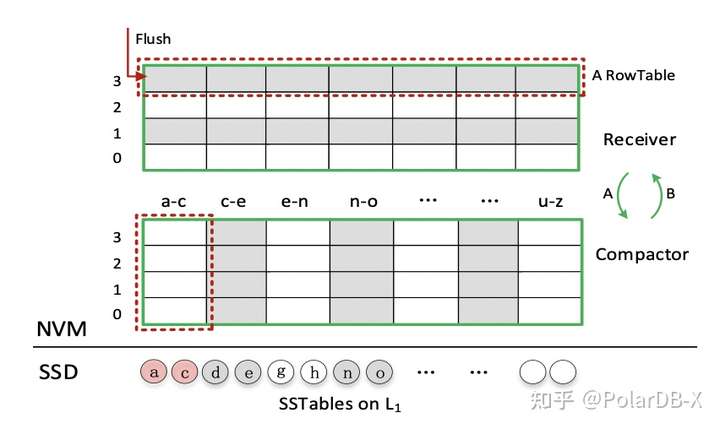
论文对存储在NVM的L0层设计了新的数据结构Matrix Container,如下图所示,内存flush到NVM的数据可以看成一行有序的数据,结构是RowTable,不断Flush多个文件,就是多行有序数据,组合在一起就是矩阵的效果,每行数据是有序的,不同行的新旧不同,具备版本的特性,上面的更新,下面的更旧。同时具有两个结构Receriver和Compactor,类似内存中的MemTable和ImmuTable,Receriver可以接收Flush数据,写满后转成只读的Compactor,不会再增加数据,Compactor可进行Compaction。

设计点2:细粒度Compaction-Column Compaction
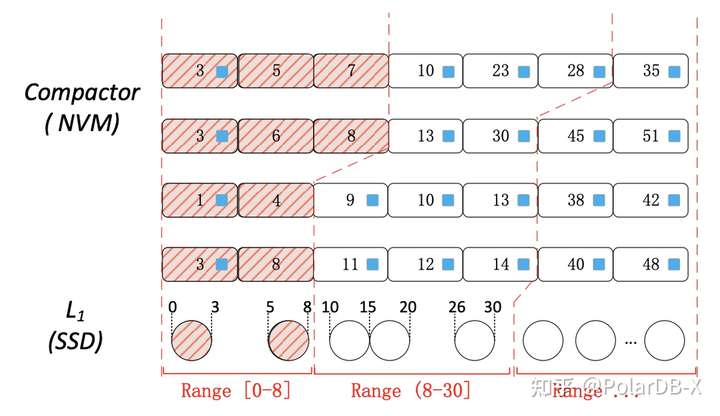
对L0层的结构设计成Matrix Container,就是为了可以细粒度可控Compaction,对列进行Compaction操作,如下图所示,当L0-L1进行Compaction时,数据量是可以根据L1层的少数文件进行小范围的Compaction,论文命名为Column Compaction,这种Compaction方式有三个优点: 1.能够控制每一次L0-L1层Compaction的数据粒度,每一次Compaction的数据量可以设置合适的值; 2.将原来通过L0文件个数控制前台写请求变成数据量控制,细粒度的Column Compaction能够保证L0的数据缓慢变化,不会一次性剧变,能够避免写停顿问题; 3.Compaction的有效性更好,相比与原来的Compaction,Compactor容量较大,数据密度更大,进行Column Compaction能够使L0的更多数据和L1的少量数据合并,重复key能够更快消除,避免重复写相同的key,且在同一个Compactor中,Column Compaction产生的新数据不会和Compactor后面的数据再次进行Column Compaction,因为范围不会重叠。可能有点难理解,举个例子:原来的Rocksdb的L0层数据量较小,假设L0只有两行数据(图中行【1、4、9】和行【3、8、11】),和L1层进行第一次Compaction,key-3写到L1,然后和上面行【3、6、8】再次进行第二次Compaction,可以发现key-3会写多次,这是数据密度的原因。并且第一次Compaction产生的新数据,会再进行第二次Compaction,而Column Compaction对于同一个Compactor内的某个范围数据,不会进行两次Compaction,当然两个Compactor的数据还是会进行Compaction。 很明显,Column Compaction能够降低写放大。 可能有人会问:把原来的L0放大,变成和MatrixKV一样大,不就一样了吗?但这意味这写停顿问题会更加严重,L0-L1一次Compaciton的数据量会更大很多。

设计点3:减少LSM-tree层数
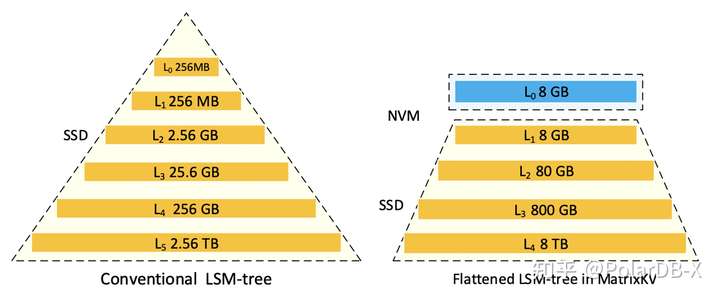
MatrixKV将L0层的数据存储到NVM,且放大的L0层的初始容量,同时L1层的大小和L0层是一样的,如下图所示,AF(上下两层的数据比例)一样,容纳相同数据量情况下,MatrixKV的层数比原来的LSM-tree更少,意味着Compaction数据搬迁的层数更少,写放大也会更小。

设计点4:跨行查询-加速L0层的读取速度
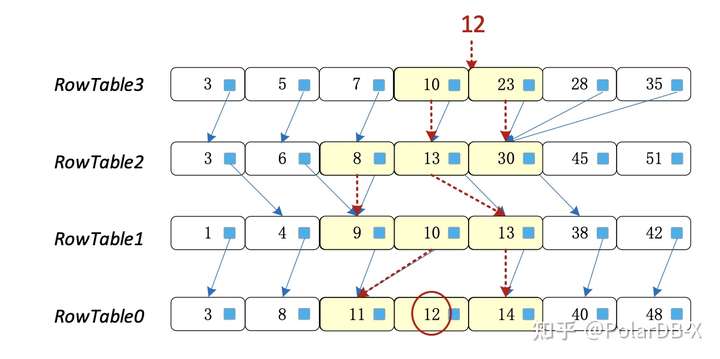
L0层的数据存储在NVM中,可以看成是一个矩阵的数据分布,且L0层的数据量较大,每行数据的范围是重叠的,为了加速L0层数据的读取,设计了新的索引结构,如下图所示,论文为两行数据之间建立了新的索引,每行数据的每个key包含了一个指向下行的指针,用于定位该key在下行中第一个大于等于该key的位置,构建这个索引的开销其实并不大,每新增加一行数据,扫描一次该行和下行的key就可以完成。 构建该索引的好处:由于上行更新,下行更旧,查询某个key时都是先查询上行,再逐行查询,每行可以使用二分查找,原来的做法相当于每行都要进行该行的全范围二分查找,增加了索引后,可以利用上行的二分位置,索引到下行,在下行中进行二分查找范围更小。举个例子,查询12,最上行没有找到,但是定位到下行的13-30,然后在13的前一个(13的前一个key一定小于10)和30范围之间二分查找,所以某行没有找到时,可以快速在下行的小范围内继续二分查找,加快查找速度。

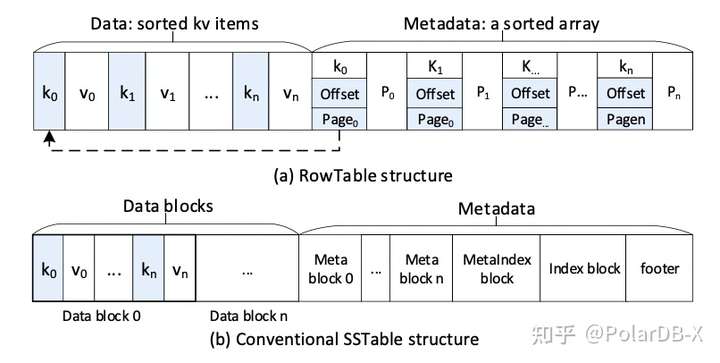
为了该索引效果,设计了新的RowTable结构,如下图所示,为每个key构建索引,与原来的SSTable有些差别,存储空间肯定会更大一些,典型的用空间换性能。

实现
论文在已开源的RocksDB代码中进行修改,以实现MatrixKV。MatrixKV访问NVM采用PMDK库,该库是Intel开发的持久性内存访问工具,在github上也已经开源。MatrixKV访问SSD直接通过POSIX API。写操作实现:日志直接存储在NVM中,DRAM中的MemTable和SSD中的SSTable和原来的RocksDB一样,不同的是L0层是新的结构RowTable。读操作实现:沿用三层读取,DRAM>NVM>SSD,不同的是在NVM中的L0层有新的读取策略。一致性实现:沿用RocksDB的版本控制,只有Flush、Column Compaction、Compaction完成时才会更新版本,不会导致数据丢失。
测试
论文的测试环境如下图: 测试对象四个: RocksDB-SSD:运行在SSD中的RocksDB; RocksDB-L0-NVM:L0层存储在8G的NVM中,L1、L2等存储在SSD的RocksDB; NoveLSM:另一篇论文方案,8G的NVM存储Memtable,L0、L1、L2等存储在SSD; MatrixKV:本论文方案,L0为8G的NVM空间,L0结构改变,L1、L2等存储在SSD。


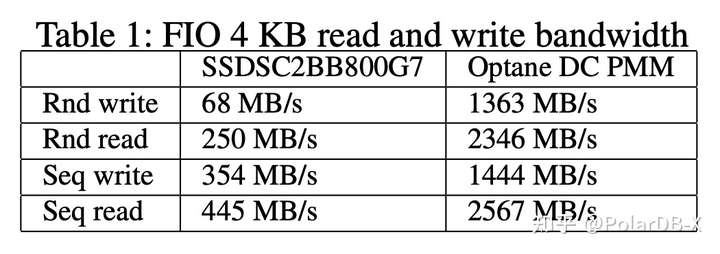
SSD和NVM的性能对比如下图:

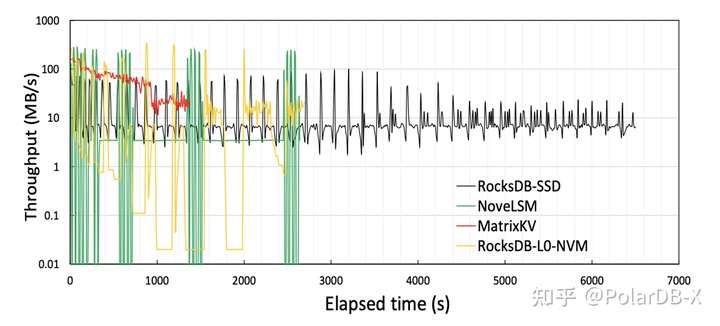
1.写停顿问题测试 如下图,红色的是本论文的MatrixKV,性能抖动不会太明显。

下图是每次L0-L1层Compaction的数据量,MatrixKV可控制的非常均匀,数据量较小。

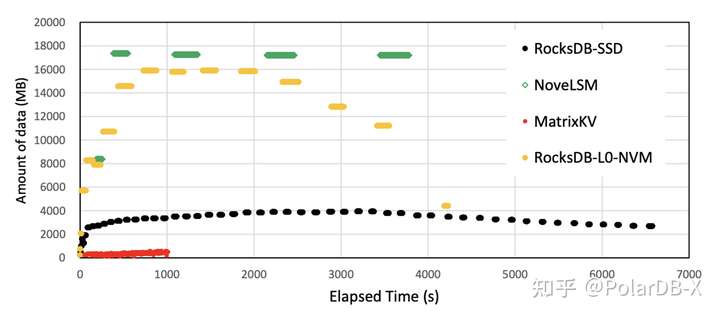
2.随机写性能 如下图,MatrixKV的随机写性能较好,阻塞更少,写放大更小,写性能会好一些。

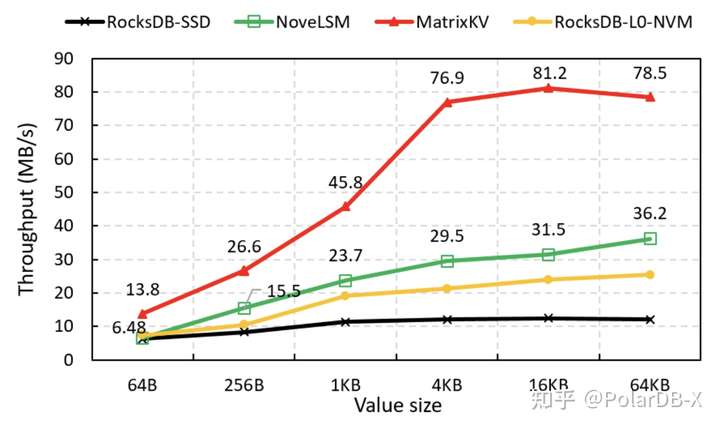
3.写放大 如下图,MatrixKV的写放大更小。

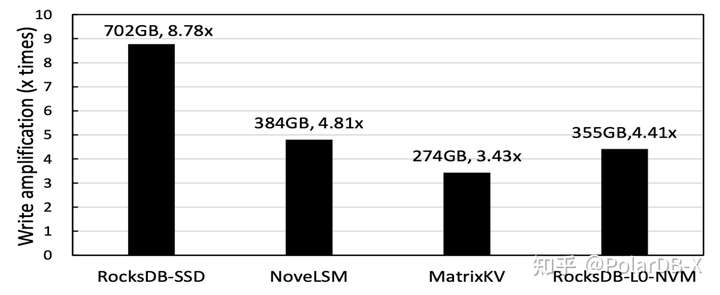
4.L0层的读性能 论文没用图,简单说了一下,在8GB的L0数据量时,测试L0层的随机读性能,性能更好17.5倍,RocksDB没用bloom-filter。


总结
1.论文减少写停顿的方法确实可行,细粒度的compaction策略比原来的LSM-tree更好,论文对该问题的发现、分析较为不错,特别是对矩阵模型的思考; 2.减少层数以减少写放大、建立索引提高读性能的优化较为常规,能用的方法很多。
文章来源:https://zhuanlan.zhihu.com/p/461226502
