




简介:
由于MongoDB 的复制集本有数据冗余,读写分离,扩节点方面有很好的实现。但在两个复制集之间同步数据就存在局限, MongoShake是阿里开发的一个数据同步工具。可以用于数据迁移,备份,实时同步。
MongoShake 通过读取mongoDB复制集的oplog操作日志进行数据同步。
MongoShake对接的源数据库支持单个mongod,replica set和sharding三种模式。目的数据库支持mongod和mongos。如果源端数据库为replica set,我们建议对接备库以减少主库的压力;如果为sharding模式,那么每个shard都将对接到MongoShake并进行并行抓取。对于目的库来说,可以对接多个mongos,不同的数据将会哈希后写入不同的mongos。
mongoshake的的 基本架构和数据流:
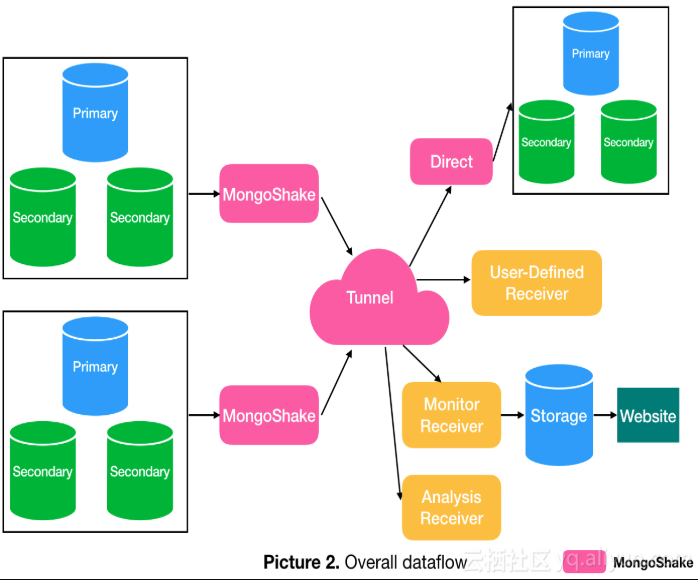
MongoShake复制的特性选项:
并行复制:并行方式有 document ID 或者collection 或者auto 。表示根据文档id或者表 进入不通的hash队列进行并行复制。(auto:自动配置,如果表有唯一键,则退为collection)
过滤:黑名单和白名单机制选择性同步db和collection。默认同步除系统表的所有库表。
Checkpoint:用于同步oplog的位点信息。格式: 年份-月份-日期 时:分。checkpoint 存在于哪里呢,在哪里设置呢?
1、如果首次同步切不设置context.start_position、或者设置了context.start_position 小于1970-01-01T00:00:00Z:会拉取所有oplog。
2、首次同步之后,在源端mongo复制集会自动创建数据库mongoshake,有库表ckpt_default 。db.ckpt_default.find() 有一条记录,记录oplog当前应用的时间点。例如:
{ "_id" : ObjectId("5e9926ed68845554501197ec"), "syncTs" : Timestamp(1587607553, 1), "name" : "复制集名称", "ackTs" : Timestamp(1587544710, 18) }
3、第一次可以手动指定checkpoint,表示从指定时间点开始同步数据。例如:context.start_position = 2020-04-17T02:26:00Z (注:如果mongo的时区指定了东八区,这个时间要减去8)
4、想重新发起oplog同步:a、清除mongoshake.ckpt_default 记录的时间点,b、指定context.start_position
安装 MongoShake :
URL:https://github.com/alibaba/MongoShake
解压后(假设解压到 data/mongoshake),目录下有以下文件:
collector.linux 执行命令
collector.conf 配置文件
logs/collector.log 打印日志,错误信息,同步时间点等
配置说明:
collector.conf 配置选项很多,但主要如下参数需要配置:
# 指定同步源mongo_urls = mongodb://USER:PASSSWORD@IP:PORT# 指定连接方式 有 primary secondaryPreferred standalone ,一般指定 standalone 表示从指定的节点抽取数据mongo_connect_mode = standalonecollector.id = mongoshake# 同步模式,all表示全量+增量同步,document表示全量同步,oplog表示增量同步。sync_mode = oploghttp_profile = 9100system_profile = 9200log.level = infolog.dir =log.file = collector.loglog.buffer = truefilter.namespace.black =filter.namespace.white =filter.pass.special.db =oplog.gids =shard_key = collection# 并发线程及其他性能相关参数worker = 4worker.batch_queue_size = 64adaptive.batching_max_size = 1024fetcher.buffer_capacity = 256worker.oplog_compressor = none# 通道模式 这里目标直连是mongo,选择directtunnel = direct# 目标实例mongo地址tunnel.address = mongodb://USER:PASSSWORD@IP:PORTcontext.storage = databasecontext.storage.db = mongoshakecontext.storage.collection = ckpt_default# 指定oplog开始同步的时间位点,默认先从目标库mongoshake.ckpt_default获取位点,如果不存在,从配置参数context.start_position获取,如果配置参数也不存在,则同步所有oplog。context.start_position = 2020-04-17T02:26:00Zmaster_quorum = falsetransform.namespace =dbref = falsemovechunk.enable = falsemovechunk.interval = 1000replayer.dml_only = false# 如果update,目标库不存在对应主键的文档,是否变为insert,建议用insertreplayer.executor.upsert = true# 如果主键冲突,是否转为update,在id多线程并发的时候,建议转为update,避免冲突错误。replayer.executor.insert_on_dup_update = truereplayer.conflict_write_to = nonereplayer.durable = truereplayer.collection_parallel = 6replayer.document_parallel = 8replayer.document_batch_size = 256replayer.collection_drop = truefilter.orphan_document = false
启动MongoShake:
配置以上配置文件后启动MongoShake:
/data/mongoshake/collector.linux --conf data/mongoshake/collector.conf &
查看日志:tail -f data/mongoshake/logs/collector.log
注意:
全量复制:全量复制过程中,容易发生冲突,冲突发生可能导致进程停止,建议设置replayer.executor.insert_on_dup_update 和 replayer.executor.upsert 为true
全量+增量:全量复制+增量复制。如果进程退出,下次启动进程会再次进行全量,建议数据进入日志同步的时候,改 sync_mode = oplog
增量同步:注意日志点的设置。
参考文档:
https://yq.aliyun.com/articles/603329
