




 点击上方蓝色字体关注我哟!
点击上方蓝色字体关注我哟!
快来跟我一起学 Kubernetes!
不知道各位有没有注意到,在 K8s 系统中,每个实例对象都有自己的 UID(其实就是UUID),用于唯一标识自己,比如 Pod、ConfigMap 等对象的 metadata 内都有一个叫做 uid 的字段。为什么要有这个字段呢?因为仅靠 kind/namespace/name 是没办法确定实例还是那个实例的,比如实例被重建,kind/namespace/name 等信息并不会变化,这时候就需要使用 UID 来判断「你还是不是原来的你了」。
UUID(Universally Unique IDentifier)又名 GUID(Globally Unique IDentifier),是一种长度为 128 bits 的,无需中心化的注册机制就能在时间和空间上具备唯一性的标识符。例如,Pod 的 uid 信息如下:
apiVersion: v1kind: Podmetadata:name: coredns-6955765f44-dc48nuid: 78ee0556-96f1-44af-b8b2-1f507dc43931
Kubernetes UUID 的生成
一个问题油然而生啊!这个 uid(UUID) 在 K8s 中究竟是如何生成的,又是如何保证在集群内是全局唯一的呢?
通过阅读源码,K8s 对象的 uid 字段是在实际创建前,由 api-server 自动注入的,关键代码如下:
k8s.io/apiserver/pkg/registry/rest/meta.go
// FillObjectMetaSystemFields populates fields that are managed by the system on ObjectMeta.func FillObjectMetaSystemFields(meta metav1.Object) {meta.SetCreationTimestamp(metav1.Now())meta.SetUID(uuid.NewUUID())meta.SetSelfLink("")}
上述代码在每个对象被创建前被调用,用以填充 ObjectMeta 字段,其中一项就是 uid。而真正生成 uid 的代码实现位于 https://github.com/google/uuid 仓库,它参照 RFC 4122[1] 和 DCE 1.1 标准实现。
根据 RFC 4122 的说明 , UUID 生成算法最高可支持一千万每秒每台机器的生成速度(很大程度应该取决于将时间细分的粒度,例如 100 纳秒粒度,每秒就可以产生 10 亿个不同的时间刻度),足以用作交易流水 ID 使用。值得注意的是,由于 UUID 的长度固定,因此 UUID 的值可能会重复(大约在公元 3400 年,与算法实现有关)。一般,UUID 会以字符串的形式使用,即将 128 bit 转为对应的 16 进制表示的字符串,例如:“6aad787c-0e4a-46eb-8e1d-00a9a825bd04”。
根据算法实现和应用范围的不同,UUID 可分为 5 类:
version 1: 基于时间的 UUID(MD5 hash)
基于时间的 UUID 通过计算当前时间戳、随机数和机器 MAC 地址得到。由于在算法中使用了 MAC 地址,该版本 UUID 可以保证在全球范围的唯一性。但与此同时,使用 MAC 地址会带来安全性问题,这就是这个版本 UUID 受到批评的地方。如果应用只是在局域网中使用,也可以使用退化的算法,以 IP 地址来代替 MAC 地址。
version 2: 嵌入 POSIX UID 的 DCE 安全的 UUID
DCE(Distributed Computing Environment)安全的 UUID 和基于时间的 UUID 算法相同,但会把时间戳的前 4 位置换为 POSIX 的 UID 或 GID。
version 3: 基于名字的 UUID(MD5 hash)
基于名字的 UUID 通过计算名字和名字空间的 MD5 散列值得到。这个版本的 UUID 保证了:相同名字空间中不同名字生成的 UUID 的唯一性;不同名字空间中的 UUID 的唯一性;相同名字空间中相同名字的 UUID 重复生成是相同的。
version 4: 随机或伪随机 UUID
根据随机数或者伪随机数生成 UUID。这种 UUID 产生重复的概率是可以计算出来的,但随机的东西就像是买彩票:你指望它发财是不可能的,但幸运通常会在不经意中到来。
version 5: 基于名字的 UUID(SHA-1 hash)
和版本 3 的 UUID 算法类似,只是散列值计算使用 SHA-1(Secure Hash Algorithm 1)算法。
令人惊讶的是 K8s 使用的居然是版本 4,通过随机数生成 UUID,
关键源码如下:
// NewRandom returns a Random (Version 4) UUID.//// The strength of the UUIDs is based on the strength of the crypto/rand// package.//// A note about uniqueness derived from the UUID Wikipedia entry://// Randomly generated UUIDs have 122 random bits. One's annual risk of being// hit by a meteorite is estimated to be one chance in 17 billion, that// means the probability is about 0.00000000006 (6 × 10−11),// equivalent to the odds of creating a few tens of trillions of UUIDs in a// year and having one duplicate.func NewRandom() (UUID, error) {var uuid UUID_, err := io.ReadFull(rander, uuid[:])if err != nil {return Nil, err}uuid[6] = (uuid[6] & 0x0f) | 0x40 // Version 4uuid[8] = (uuid[8] & 0x3f) | 0x80 // Variant is 10return uuid, nil}
通过翻阅代码历史记录,可以发现 K8s 最初其实使用的是版本 1 的 UUID 生成算法,不过考虑到以下几个问题,才切换为版本 4 的:
•使用主机 MAC 地址,有隐私泄露的风险•依赖主机时钟获取时间信息不可靠•基于 clock 处理重复让代码变得复杂
更多细节请查看代码提交 PR : https://github.com/kubernetes/kubernetes/pull/75270
接着分析,随机生成 UUID 的代码中通过读取 rander
获得随机数,而 rander
根据平台的不同有所差异。Linux 平台下会首先尝试通过系统调用 getrandom(2)
获取随机数,如果系统调用不可用,则通过读取 /dev/urandom
文件的内容获取随机数:
// Reader is a global, shared instance of a cryptographically// secure random number generator.//// On Linux and FreeBSD, Reader uses getrandom(2) if available, /dev/urandom otherwise.// On OpenBSD, Reader uses getentropy(2).// On other Unix-like systems, Reader reads from /dev/urandom.// On Windows systems, Reader uses the CryptGenRandom API.// On Wasm, Reader uses the Web Crypto API.var Reader io.Reader
getrandom(2)
系统调用在 3.17 版内核被引入,本质上其实与读取 /dev/urandom
异曲同工,那么如何理解 /dev/urandom
呢?这需要深入 Linux 内核的随机数生成器。
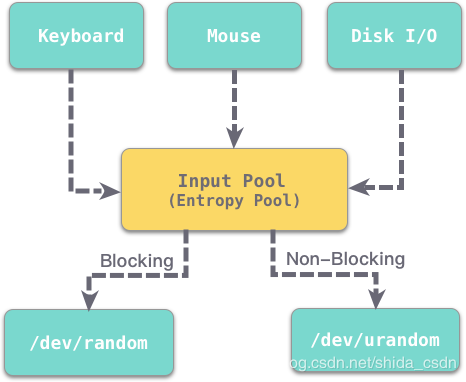 如上图所示,
如上图所示,/dev/urandom
与 /dev/random
是 Linux/Unix 系统中比较特殊的两个文件,用户可以通过读取该文件获得操作系统生成的随机数。而 Linux/Unix
操作系统生成随机数的原理是是利用当前系统的熵池来计算出固定一定数量的随机比特,然后将这些比特作为字节流返回。熵池就是当前系统的环境噪音,熵指的是一个系统的混乱程度,系统噪音可以通过很多参数来评估,如键盘输入、鼠标移动、磁盘
I/O、文件使用、不同类型的进程数量等等。那为什么会有 /dev/urandom
和 /dev/random
两个随机数文件呢?区别在于:/dev/random
是阻塞型的,当熵池中没有足够的输入时,就无法持续产生随机数,进而阻塞程序;而 /dev/urandom
是非阻塞的,当熵池中的输入不够时,可以通过一些额外的算法,持续产生随机数,当然此时随机的效果相比 /dev/random
要差些,但最重要的是能满足持续生成随机数的需求。
文末小结
到这里很容易知道,K8s 本质上是利用操作系统的随机数生成器(Unix/Linux 平台就是 /dev/urandom
)生成随机数的方法产生 UUID 的,其实也是充分利用了机器的熵,综合各类信息来产生随机数,出现重复的概率应该还是非常低的!引用它的原话是:“一年内创建数万亿个 UUID,仅会有一个重复”。
References
[1]
RFC 4122: http://tools.ietf.org/html/rfc4122
公众号『 Kubernetes 学习圈 』每天会发布一篇与 Kubernetes 相关的互动小问题!通过分析和解决小问题来驱动学习,逐步掌握 Kubernetes 容器编排技术,日拱一卒,每天进步一点!
好的技术绝对不是一蹴而就,而在于日复一日的积累,相信坚持的力量!
PS:看完文章如果有收获,顺手花 1s 时间帮点下文末右下方的「在看」,感激!
如果我的文章对你有所帮助,点赞、转发都是一种支持!

