





EXADATA 计算节点频繁重启故障一例
⒈ 概述
某客户打电话反馈,他们Exadata X5-2中的计算节点db02在昨天晚上9点半开始,频繁地出现主机重启故障,差不多每半小时左右就重启一次,数据库的运维厂商查看日志后,认为是Exadata中的IB心跳网络异常导致计算节点被驱逐出集群。客户希望我们尽快帮忙确认是否是IB网络异常。
2. 故障分析及解决
1、 数据库运维厂商将主机重启时间段的日志截图转发给了我,日志截图如下所示。
(1)GI集群的alert日志:
 (2)操作系统日志:
(2)操作系统日志:
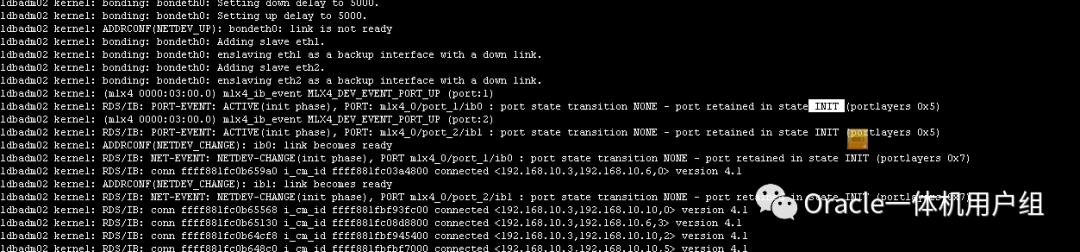
从第一张截图的确可以看出发生了心跳网络丢失的情况,然后集群进行了重组,当前活动的节点只有db01。
从第二张截图的确也可以看出,IB网口ib0和ib1的状态异常,截图中的当前状态是INIT初始化状态。
通过这两张截图,数据库的运维厂商认为是心跳网络出了问题,最终导致GI集群将db02节点驱逐出集群,导致了db02节点频繁重启。
2、我们先让硬件的同事收集了计算节点db02的ilom snapshot日志,硬件同事反馈无任何硬件故障。在db02节点重启之前,操作系统日志中也没有任何可疑信息。
3、于是,跟着数据库运维厂商的思路,只是简单地查看了db01和db02节点的操作系统日志,当db02节点第一次发生重启期间,db01节点的操作系统日志中有如下信息。
Dec 23 21:33:17 dm01dbadm01 kernel: ib0: ipoib_cm_handle_tx_wc: failed cm send event (status=12, wrid=50 vend_err 0x81) Dec 23 21:33:17 dm01dbadm01 kernel: ib1: ipoib_cm_handle_tx_wc: failed cm send event (status=12, wrid=32 vend_err 0x81) Dec 23 21:33:18 dm01dbadm01 kernel: RDS/IB: connection <192.168.10.1,192.168.10.3,0> dropped due to 'send completion error' Dec 23 21:33:18 dm01dbadm01 kernel: RDS/IB: send completion <192.168.10.1,192.168.10.3,0> status 12 vendor_err 0x81, disconnecting and reconnecting Dec 23 21:33:18 dm01dbadm01 kernel: RDS/IB: connection <192.168.10.2,192.168.10.4,0> dropped due to 'send completion error' Dec 23 21:33:18 dm01dbadm01 kernel: RDS/IB: send completion <192.168.10.2,192.168.10.4,0> status 12 vendor_err 0x81, disconnecting and reconnecting Dec 23 21:33:19 dm01dbadm01 kernel: RDS/IB: connection <192.168.10.2,192.168.10.3,0> dropped due to 'send completion error' Dec 23 21:33:19 dm01dbadm01 kernel: RDS/IB: send completion <192.168.10.2,192.168.10.3,0> status 12 vendor_err 0x81, disconnecting and reconnecting |
看着还真像是IB网络出现了问题,于是将这个问题就当作是IB心跳异常所导致,脑海里立即搜索Exadata中因为IB心跳超时而导致节点被驱逐的BUG。立即回想到Exadata中的Exawather因为收集slabinfo命令而导致IB超时,最终导致计算节点被驱逐的案例。
具体可参考MOS文档《Exadata node crashed RDS/IB: send completion <XXX> status 12 vendor_err 129,disconnecting and reconnecting,kernel: ib1: ipoib_cm_handle_tx_wc: failed cm send event (status=12, wrid=22 vend_err 0x81) (Doc ID 2158441.1)》。
4、于是让同事修改ExaWatcher.conf配置文件,关闭Slabinfo信息收集工作,但同事检查ExaWatcher.conf配置文件时,没有发现Slabinfo相关信息。为了验证是否因为ExaWatcher收集信息而导致主机重启,干脆让同事关闭了两个节点的ExaWatcher进程。
5、过了十几分钟后,系统再次重启。这说明主机重启与ExaWatcher收集信息无关。于是重新开始分析操作系统日志和GI集群日志。GI集群日志中,2021-12-23 21:33:46提示集群间的网络通信丢失50%。
2021-12-23 21:33:46.204: CRS-1612:Network communication with node dm01dbadm02(2) missing for 50% of timeout interval. Removal of this node from cluster in 29.330 seconds. |
检查 Exawatcher工具收集的资源使用日志,可以看到vmstat命令写入最后一条日志的时间为2021 21:33:08。
zzz <12/23/2021 21:33:03> Count:299 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 67614312 510128 18460004 0 0 7 33 0 0 3 1 95 0 0 1 0 0 67618376 510128 18460200 0 0 0 313 7940 11022 0 3 97 0 0 zzz <12/23/2021 21:33:08> Count:300 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 67618912 510128 18460200 0 0 7 33 0 0 3 1 95 0 0 |
这两个时间戳进行对比就可以看出,db02操作系统先出的问题,然后才是网络丢失。也即操作系统先重启,然后才提示心跳网络异常。
6、为了进一步确认db02节点的重启不是因为GI集群驱逐的结果,我让同事将CRS 置于disabled auto-start状态,也即操作系统启动时,CRS不会自动启动,然后关闭了db02的CRS。但是,没多久,db02节点再次重启。通过这个测试可以得出一个结论,主机的重启与GI集群毫无关系。
在分析这个案例的过程中,db02节点基本上每半小时就重启一次,非常有规律。同时,还发现一个奇怪的现象,那就是db02节点的操作系统重启时,该节点对应的ILOM也无法ping通。理论上,这是完全不可能的。
7、此时,已经非常肯定,db02节点的重启与集群无关。db02节点目前就相当于一个裸操作系统在运行,但是每半小时就重启一次,相当有规律,这真的非常奇怪。此时脑海里有三种可能:(1)操作系统上是否有crontab?
(2)kernel 因为某些Bug而crash掉了,没来得及写meesages日志?
(3)硬件有故障,但ILOM没有报出来?或者是CPU温度过高等?
8、检查了操作系统的crontab 和 init等,没有发现异常。对于第二、三种情况,只能开SR借助于Oracle原厂进一步分析。Oracle售后工程师从Ilom Snapshot日志中看到如下信息。
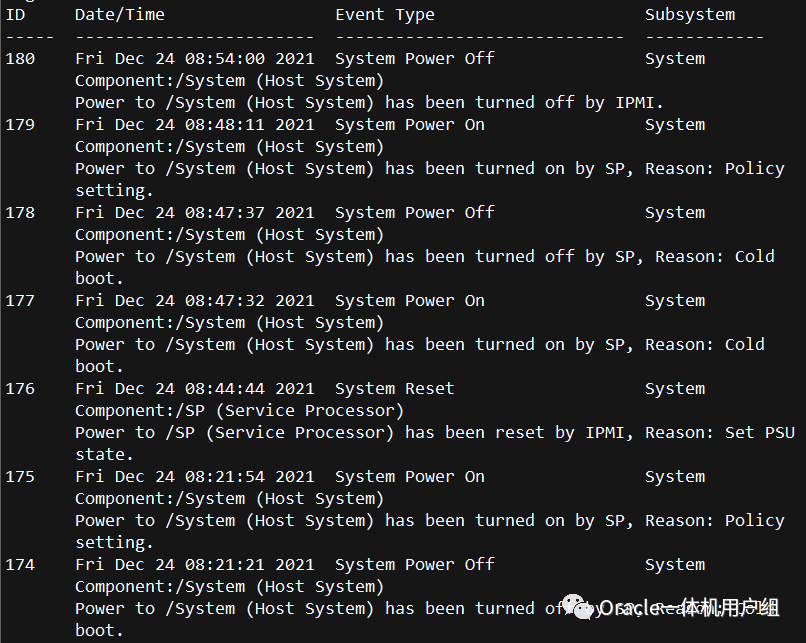
售后工程师的建议:
日志中可以看到SP(ILOM)在执行trun off 系统的操作。因此怀疑这个重启动作是由ILOM来执行的,建议开个硬件SR来继续调查这个问题。
9、通过跟Oracle售后工程师的沟通,还是有很多收获的,建议先让原厂的硬件工程师介入分析,如果硬件工程师确认硬件方面没有问题,再考虑kernel的问题。
由于这台Exadata的硬件已经原厂过保,所以最终无法联系原厂的硬件工程师来分析这个问题。还是只能自己想办法了。从ILOM的日志可以看到,操作系统的重启是由ILOM触发的,正常情况下,是不可能会发生这种事情的。这个案例中,很多现象真的匪夷所思。例如:1. ILOM会重启操作系统。2.操作系统重启时,ILOM也无法访问。
10、该如何处理这个故障,脑海里有了几种方案,但这些方案都只能是进行尝试。
(1)尝试升级Ilom的微码。也许是Ilom的某个未知BUG?目前Ilom表现出来的现象太不正常了。
(2)如果升级Ilom的微码无法解决问题,就尝试更换主板。因为Ilom是集成在主板上的,也许是主板上有瑕疵呢?
(3)后续的可能操作。例如:刷机等等。
11、按照脑海中的既定方案,先进行Ilom的微码升级工作,升级完成后,重启操作系统进行观察,连续运行24小时,再未出现操作系统重启现象。接着,将CRS改回auto-restart 状态,并且启动db02节点上的GI集群后进行观察,再次连续运行24小时,也未出现操作系统重启。到目前为止,该节点已经正常运行一个多月,至此,可以说明问题得以解决。
12、故障虽然解决了,但还是有很多疑问的,例如:是ILOM的哪个BUG? 我在MOS上未找到答案,也没有搜索到类似的案例。
