




前言
本篇文章主要针对节点替换的实现原理和对节点替换过程中遇到的问题、解决方法进行总结。本文适合使用节点替换的人员排查问题使用,提高排查问题以及解决问题的效率。
- 随着集群规模的扩大,用户使用的集群节点数量增加,单节点故障概率变大,同时随着数据量增大,单个节点的计算能力和存储能力也可能成为瓶颈,这两种情况都需要对集群节点进行替换,保证集群能够正常工作。GBase 8a MPP Cluster 具有在线不停服节点替换能力,即可在生产环境下不停机进行节点替换。
- 由于86版本原节点替换功能在替换数据节点时存在大量的feventlog,gcrecover恢复时系统负载很大,且获取tableid耗时很长,严重影响节点替换的性能,因此95版本为了解决上述问题,采用rebalance的搬移策略恢复分片的方式进行数据恢复。
- 由于在实际应用过程中,目前节点替换有时会出现各种问题,影响工作效率,针对一些异常,如设置节点替换状态报错、节点替换命令执行过程中出现的问题进行描述、分析原因并提供解决办法。
一、节点替换实现原理
- 95版本节点替换
如下图所示,node3节点是故障节点,使用一台node4替换node3,替换完成后,故障节点ip进行了变更,与ip不相同
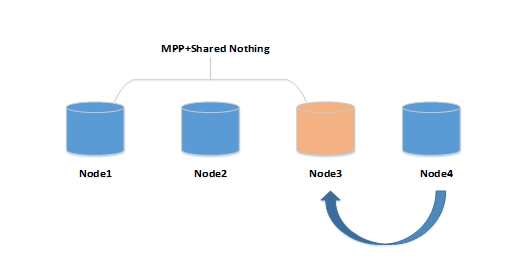
图1 节点替换图示说明
- 使用freenode替换纯data节点替换实现逻辑
- 检查参数,被替换节点应为unavailable状态,集群状态应为normal
- 检查集群写锁,在没有写操作时将集群设置为readonly状态
- gcadmin删除被替换节点的feventlog,否则rebalance将会失败
- 将free node加入到被替换节点的vc中,生成使用新节点替换损坏节点的distribution,执行initnodedatamap
- 将gbase库的元数据拷贝到新节点
- 打印提示信息,提示用户检查rebalance状态,在rebalance成功后可用gcadmin 命令将old distribution以及hashmap删除,将unavaiable状态的损坏节点从vc中移除,变为freenode

图2 使用freenode替换纯data节点替换实现逻辑
- 设置节点状态
- 发现节点损坏或者决定替换节点
- 用户允许设置的节点状态是unavailable
- unavailable状态必须通过节点替换才能恢复为normal
节点替换状态的转换如下图

那么,根据上面描述的使用freenode替换纯data节点替换实现逻辑,使用者具体的使用freenode替换data操作是什么呢?可以参考如下的操作步骤:
这里以192.168.11.101 所在的集群为例进行说明:
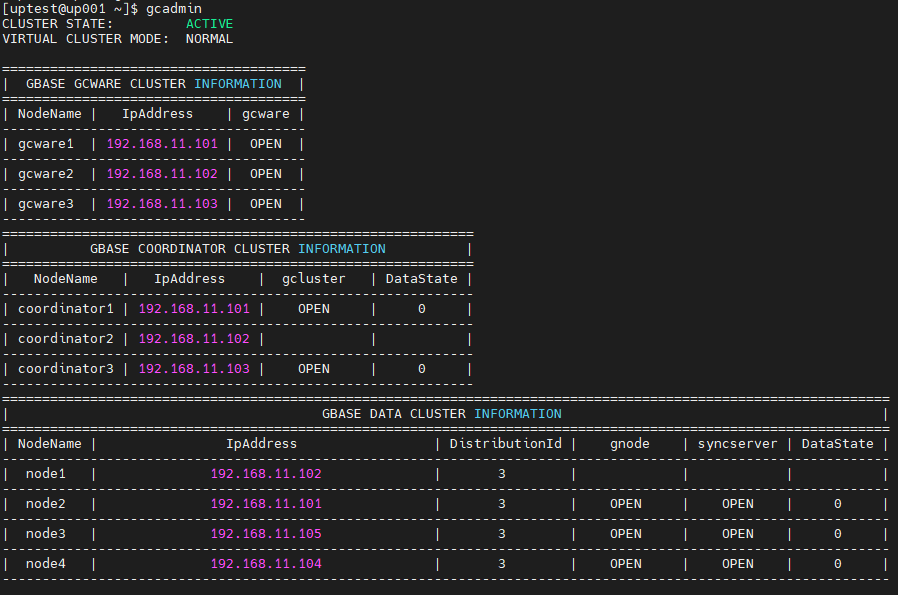
1、手工操作
1)将被替换节点设置为unavailable,需要进行节点替换的节点是192.168.11.102
gcadmin setnodestate ip unavailable
[uptest@up001 ~]$ gcadmin setnodestate 192.168.11.102 unavailable
after set node state into unavailable,can not set the state into normal,
must run gcadmin replacenodes to replace this node ,after that command node state can return into normal.
you realy want to set node state into unavailable(yes or no)?
yes
get node data state by ddl fevent log start ......
get node data state by ddl fevent log end ......
get node data state by dml fevent log start ......
get node data state by dml fevent log end ......
get node data state by dml storage fevent log start ......
get node data state by dml storage fevent log end ......
check coordinator node data state by fevent log start ......
check coordinator node data state by fevent log end ......
check data server node data state by fevent log start ......
check data server node data state by fevent log end ......
set node [192.168.11.102] state to unavailable successful
2)使用gcadmin 命令删除被替换节点的feventlog(gcadmin的命令可以通过执行gcadmin -h或者gcadmin --help查看)
gcadmin rmfeventlog ip
[uptest@up001 ~]$ gcadmin rmfeventlog 192.168.11.102
after rmfeventlog 192.168.11.102, fevent log will be removed, must run gcadmin replacenodes to replace this node.
you realy want to remove node 192.168.11.102 fevent log(yes or no)?
yes
delete ddl event log on node 192.168.11.102 start
delete ddl event log on node 192.168.11.102 end
delete dml event log on node 192.168.11.102 start
delete dml event log on node 192.168.11.102 end
delete dml storage event log on node 192.168.11.102 start
delete dml storage event log on node 192.168.11.102 end
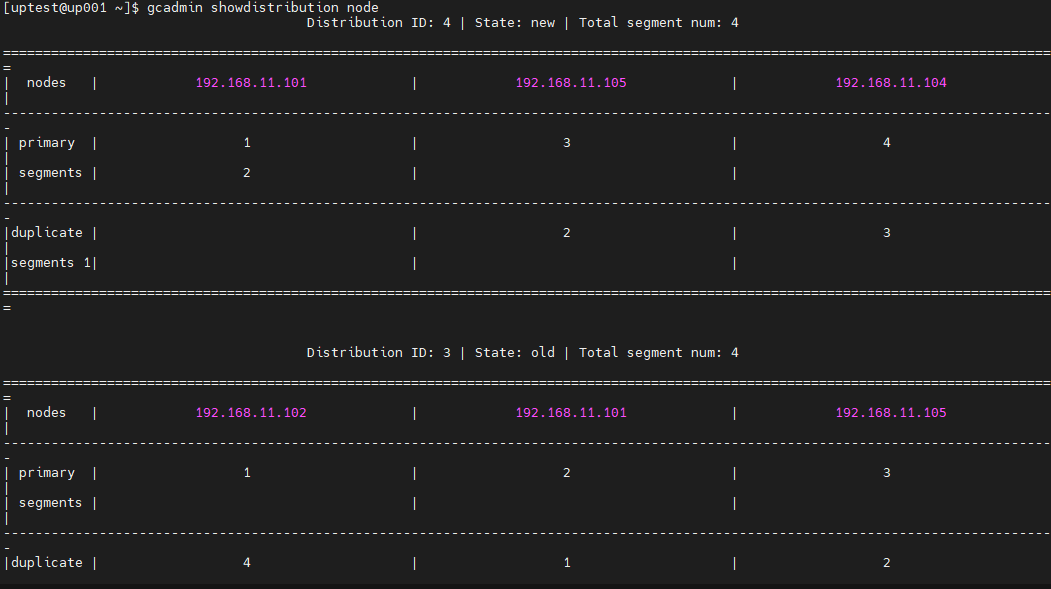
3)建立新的distribution(剔除被替换节点,其他节点分片分布保持不变)
首先需要先需要手工生成一个剔除被替换节点的新的distribution,这里以192.168.11.102 节点举例说明:
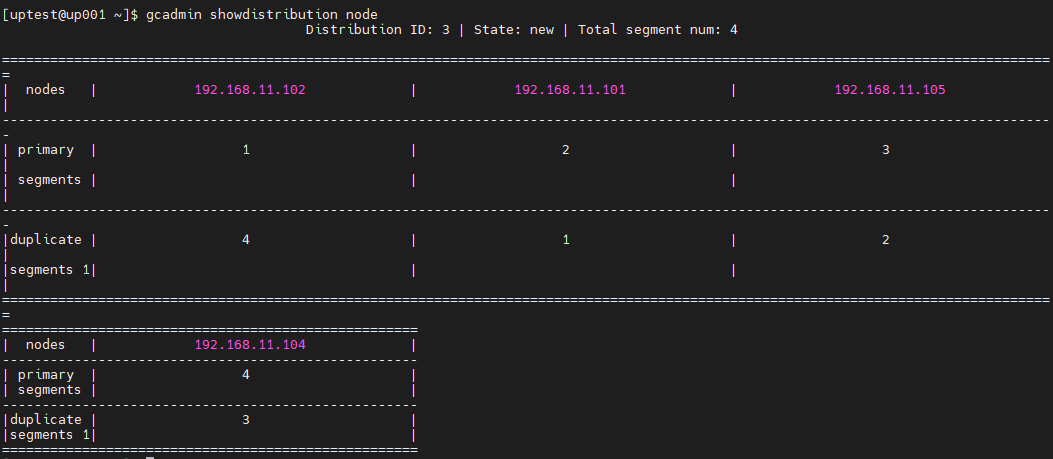
gcadmin getdistribution 3 distribution_info.xml
[uptest@up001 ]$ gcadmin getdistribution 3 distribution_info.xml
gcadmin getdistribution 3 distribution_info.xml ...
NOTE:file [distribution_info.xml] was exist, the content will be cleared
get segments information
write segments information to file [distribution_info.xml]
gcadmin getdistribution information successful
修改distribution_info.xml中的内容,将被替换节点所在的节点去掉
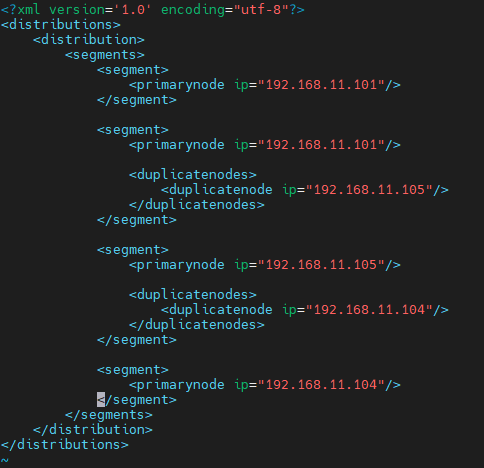
手工生成新的distribution
[uptest@up001 gcinstall]$ cat gcChangeInfo.xml-bak
<?xml version="1.0" encoding="utf-8"?>
<servers>
<cfgFile file="distribution_info.xml"/>
</servers>
[uptest@up001 gcinstall]$ gcadmin distribution gcChangeInfo.xml-bak
gcadmin generate distribution ...
gcadmin generate distribution successful
生成distribution完成后,执行initnodedatamap操作
[uptest@up001 ~]$ gccli -uroot
GBase client 9.5.3.26.5dad792a. Copyright (c) 2004-2022, GBase. All Rights Reserved.
gbase> initnodedatamap;
Query OK, 0 rows affected, 6 warnings (Elapsed: 00:00:01.34)
4)将数据rebalance instance到最新的distribution上
[uptest@up001 ~]$ gccli -uroot
GBase client 9.5.3.26.5dad792a. Copyright (c) 2004-2022, GBase. All Rights Reserved.
gbase> rebalance instance;
Query OK, 1 row affected (Elapsed: 00:00:02.12)
查看rebalance是否完成,可以通过查看系统表的完成进度
[uptest@up001 ~]$ gccli -uroot
GBase client 9.5.3.26.5dad792a. Copyright (c) 2004-2022, GBase. All Rights Reserved.
gbase> use gclusterdb;
Query OK, 0 rows affected (Elapsed: 00:00:00.00)
gbase> select * from rebalancing_status;
+------------+---------+------------+----------+----------------------------+----------------------------+-----------+------------+----------+----------------+-----------------+
| index_name | db_name | table_name | tmptable | start_time | end_time | **status **| percentage | priority | host | distribution_id |
+------------+---------+------------+----------+----------------------------+----------------------------+-----------+------------+----------+----------------+-----------------+
| test.t1 | test | t1 | | 2022-02-11 12:23:48.976000 | 2022-02-11 12:23:49.002000 | **COMPLETED** | 100 | 5 | 192.168.11.101 | 4 |
+------------+---------+------------+----------+----------------------------+----------------------------+-----------+------------+----------+----------------+-----------------+
1 row in set (Elapsed: 00:00:00.05)
查看rebalancing_status表的status 字段,如果所有用户表的重分布状态都显示COMPLETED,表示本次重分布操作已完成,可以进行下面的步骤。
2、执行节点替换命令replace.py替换data节点(程序内部调用过程可以参考如下表格中的内容)
如果被替换节点是一个复合节点(即是coordinator也是data,那么替换的顺序是先替换coordinator,再替换data节点)
./replace.py --host=192.168.11.102 --ov --dbaUser=uptest --generalDBUser=root --generalDBPwd=’’ --type=coor --dbaUserPwd=gbaseroot
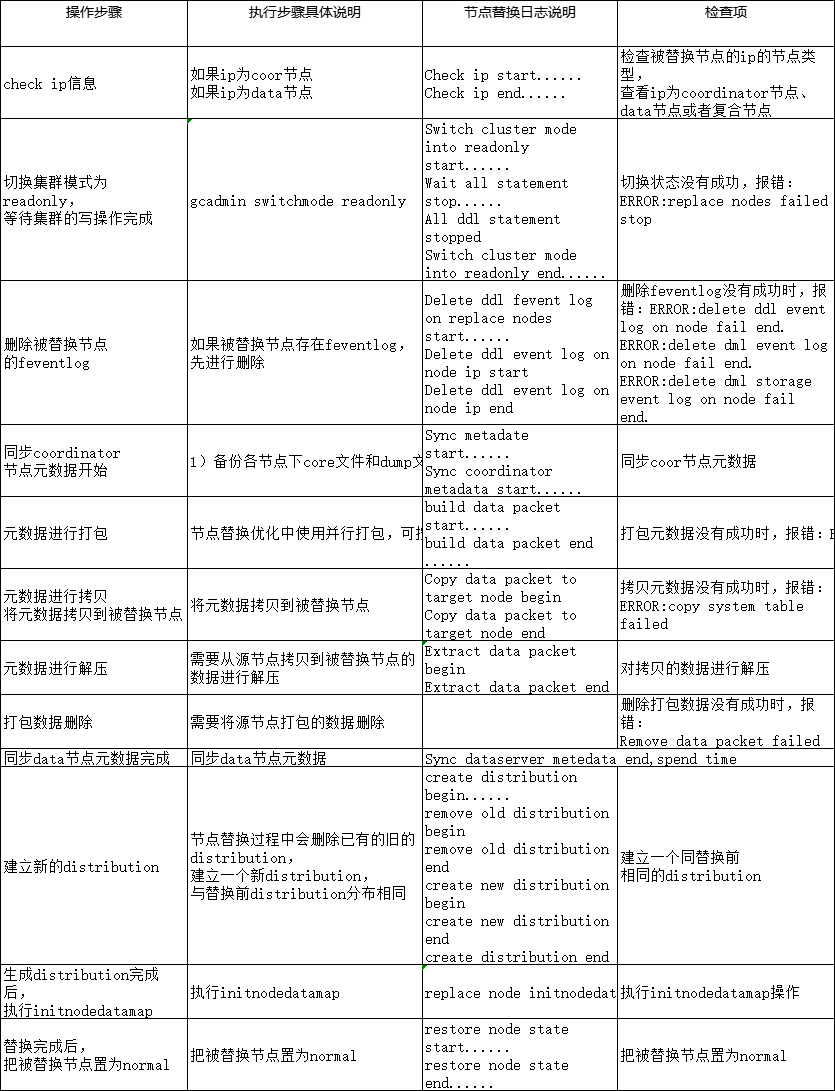
3、完成后再次执行rebalance instance
rebalance instance;
4、确保所有数据rebalance完成后,可以将中间中转数据的distribution删掉
gcadmin rmdistribution 3
- 使用全新节点替换纯data实现逻辑
- 检查参数,被替换节点应为unavailable状态,集群状态应为normal
- Replace.py 脚本安装dataserver节点信息
- gcadmin检查集群写锁,在没有写操作时将集群设置为readonly状态
- gcadmin删除被替换节点的feventlog,否则rebalance将会失败
- gcadmin将gbase库的元数据拷贝到新节点
- gcadmin打印提示信息,提示用户检查rebalance状态,在rebalance成功后可用gcadmin命令将废弃distribution以及hashmap删除
- 使用全新节点替换纯data节点执行步骤:
- 手工操作
1)将被替换节点设置为unavailable
2)使用gcadmin 命令删除被替换节点的feventlog
3)建立新的distribution(剔除被替换节点,其他节点分片分布保持不变)
4)将数据rebalance instance到最新的distribution上 - 执行节点替换命令replace.py替换data节点(程序内部调用过程可以参考如下的表格)
- 完成后再次执行rebalance instance
- 确保所有数据rebalance完成后,可以将中间中转数据的distribution删掉
- 使用freenode替换纯data和全新节点替换纯data对比介绍

- 862版本节点替换流程
- 设置节点状态命令
gcadmin setnodestate ip unavailable
- 执行replace.py节点替换命令
replace.py --host=ip --rootPwd=1111111
参数overwrite,强制替换参数,–host为ip列表,每次可替换多个节点,按照集群安装手册进行新机器配置
二、节点替换故障排查
针对节点替换功能使用过程中的报错信息与报错场景,进行归类汇总,总结如下:
由于节点替换过程主要分为两个主要部分,一部分是安装,一部分是gcadmin replacenode。
1.与安装参数及环境部署相关的问题
与安装参数及环境检查的相关问题,一般集中在执行节点替换命令输入的参数及相关的环境变量检查上,具体的检查内容可以参考表1中的检查内容。
-
环境检查及节点安装

表1
涉及安装参数及环境检查相关的问题,可从报错信息入手,结合上述表格中列出的检查项,一步一步排查原因。
2.设置节点替换状态相关的问题
-
设置节点替换状态时,需要获取所有正常可用的coordinator节点数
-
设置节点替换状态时,需要检查data节点是否有可用分片
-
集群如果已经存在一半coor节点-1损坏的情况下,需要对设置的coor节点进行检查(86版本和952版本)
3. 执行节点替换命令使用的脚本相关问题
节点替换功能使用的脚本:
节点替换在启动后的不同阶段,可能会启动不同的进程
Replace.py 节点替换主进程,整个节点替换过程中执行节点上该进程都会存在
安装脚本 节点安装进程,安装过程中在目标节点上执行
gcadmin replacenodes 设置集群状态、同步数据、设置feventlog,在安装完成到替换结束,执行节点存在整个进程
同步集群层元数据脚本 在所有coordinator节点存在这个进程
同步数据节点元数据脚本 在所有dataserver节点上存在这个进程
打包、解压进程 在所有节点上可能存在这个进程
在replace.py脚本中需要调用gcadmin replacenodes,目前对于节点替换命令限制使用了单进程运行,如果使用并发操作,后执行的节点替换命令会报错。
使用节点替换过程中具体的相关问题说明:
3.1 与安装参数及环境部署相关的问题
- 执行节点替换命令host参数输入为空,执行节点替换命令报错
./replace.py --host= --rootP=111111 --ov
Can not get replaced nodes’ ip,please use ‘–host’ option.
分析原因:
节点替换命令执行时,需要对所有输入的参数进行检查,检查不符合要求的参数报错。
解决办法:
可参考表格中的内容进行对照,按照参数检查的报错信息修改具体的参数及参数值。

- 节点替换命令输入参数passwordInputMode值为pwdsame,密码输入正确时,执行节点替换命令报错
执行节点替换命令,操作系密码root密码输入gbase(正确的应该是111111),数据库root用户密码输入回车
分析原因:
由于使用passwordInput参数传入的值应该是操作系统root用户的密码111111,实际传入的是操作系统root用户错误的密码
- 执行节点替换命令报错:“can not get coordinator node info”
执行replace.py时报错:“can not get coordinator node info”
./replace.py --host=ip -rootP=111111 --ov
Traceback(most recent call last):
Exception: can not get gcluster node info:cat :/etc/corosync/corosync.conf:Permission denied
分析原因:
检查/etc/corosync/corosync.conf文件的权限是640,依照集群的默认安装应该是644才对,通过修改其权限为644后节点替换可顺利执行。
深入检查发现现场系统root的umask为0027,造成问题的原因基本明确为权限造成。
解决办法:
这个其实是程序存在的问题,在root用户umask为027的情况下,/etc/corosync/corosync.conf的文件权限不正确,进行节点替换之前,应该保证所使用的文件权限正确,才可以执行节点替换命令。
在linux系统中,我们创建一个新的文件或者目录的时候,这些新的文件或目录都会有默认的访问权限,umask命令与文件和目录的默认访问权限有关。若用户创建一个文件,则文件的默认访问权限为 -rw-rw-rw- ,创建目录的默认权限 drwxrwxrwx ,而umask值则表明了需要从默认权限中去掉哪些权限来成为最终的默认权限值。
- 设置节点替换状态完成后,执行节点替换报错:Error cause:/usr/bin/pexpect.py
./replace.py --host=ip --rootPwd=111111 --ov
Error:execute cmd [scp -o strictHostkeychecking=no -o -UserKnownHostFile=/dev/null -q -r /usr/bin/gadm_cp_sys_tbl.py /usr/bin/pexpect.py gbase@ip:/tmp]failed,error no[1] Error cause:/usr/bin/pexpect.py:No such file or directory
分析原因:
拷贝源节点上没有要拷贝的python程序导致的。
解决办法:
节点替换前,按照需要拷贝的python程序进行检查,查看python程序是否存在。
3.2 执行节点替换命令使用的脚本相关问题
1、执行节点替换命令,在同一节点的其他session上再次执行节点替换命令
[uptest@up001 gcinstall]$ ./replace.py --host=192.168.11.102 --ov --dbaUser=uptest --generalDBUser=root --generalDBPwd='' --type=coor --dbaUserPwd=gbaseroot
install prefix: /opt/uptest/192.168.11.101
execute replace node os user: uptest
replaced nodes: ['192.168.11.102']
replace node type: coor
IsAutoGcware: True
coordinator hosts: ['192.168.11.101', '192.168.11.102', '192.168.11.103']
IP: 192.168.11.102
IP: 192.168.11.101
IP: 192.168.11.105
IP: 192.168.11.104
data hosts: ['192.168.11.102', '192.168.11.101', '192.168.11.105', '192.168.11.104']
freenode hosts: []
node address type: IPV4
localHost is: 192.168.11.101
gcware mode: single vc mode
Error: replace.py(line 1288) -- gcware addlock:there is already a process running for replace node, and you can't have to do it again.
分析原因:
节点替换单进程运行,即同一时间内只允许有一个节点替换进程执行
解决办法:
节点替换完成后,在执行其他节点替换命令。
