




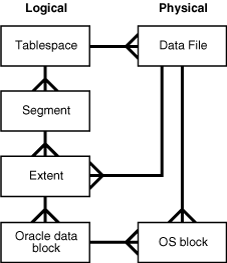
1. 基础概念:
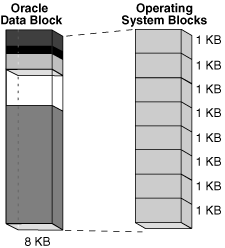
oracle block是逻辑存储数据(table、index、undo…的segment)分配的最小unit,对应到多个底层物理数据文件的os block。
-
db_block_size一般默认为8k,在创建db时指定,为了最优性能,推荐选择合适的OS bs大小倍数。
-
8k的普通表空间单个文件最大32g,32k的单个文件最大128g。
-
不同block size的db进行tts,可以手动指定DB_nK_CACHE_SIZE参数,区别于默认8k的db_buffer;或者为了防止太多字段和太长列的表发生行链接,还有一些DSS环境也可以指定db或ts较大的blocksize。
2. 块结构:

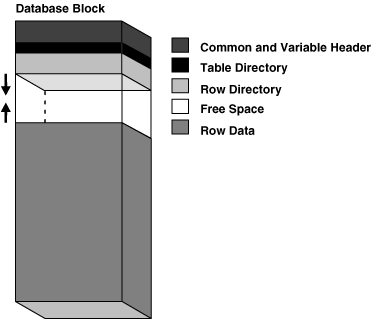
一个data block从上到下可以简单理解为 3 层:
- 1: 块头: 包含 块头结构信息 、 事务信息
- 2: 数据头:包含 数据头结构信息 、 表目录 、 行目录
- 3: 数据: 包含 实际的数据(row header + row pieces)
下面我们通过 trace 和 bbed 转储block数据简单分析一下,你也可以使用dd
-- 环境: oel 5.4 32位 11.2.0.3
-- trace总结了必要的信息,但是理解block结构bbed相对更好
create table test_dump(
id number,
name varchar(32),
age number
);
insert into test_dump values(1,'aaa',111);
insert into test_dump values(2,'bbb',222);
insert into test_dump values(3,'ccc',333);
insert into test_dump values(4,'xxx',444);
insert into test_dump values(5,'yyy',555);
insert into test_dump values(6,'zzz',666);
commit;
insert into test_dump values(6,'zzz',666);
rollback;
delete from test_dump where id in (4,5,6);
insert into test_dump values(6,'zzz',666);
-- 查询相关 segment 的block号
SQL> select header_file, header_block, blocks from dba_segments where segment_name = 'TEST_DUMP' and owner='YG';
HEADER_FILE HEADER_BLOCK BLOCKS
----------- ------------ ----------
4 130 8
-- 查询相关 extent 的block号(file_id标识db内唯一性,rfno标识tbs内唯一性)
SQL> select file_id, RELATIVE_FNO, block_id, blocks from dba_extents where segment_name='TEST_DUMP' and owner = 'YG';
FILE_ID RELATIVE_FNO BLOCK_ID BLOCKS
---------- ------------ ---------- ----------
4 4 128 8
-- 使用rowid函数找出具体row的block号用来转储,大家感兴趣也可以转储extent和segment块的信息观察,会发现存储一些metadata和一些block空间使用标记
SQL> select ID, DBMS_ROWID.ROWID_RELATIVE_FNO(rowid) file_no, DBMS_ROWID.ROWID_BLOCK_NUMBER(rowid) block_no, DBMS_ROWID.ROWID_OBJECT(rowid) object_id from yg.test_dump;
ID FILE_NO BLOCK_NO OBJECT_ID
---------- ---------- ---------- ----------
1 4 133 14247
2 4 133 14247
3 4 133 14247
6 4 133 14247
-- trace dump 文件从上至下简单分析
SQL> alter session set tracefile_identifier = dump_test;
SQL> select * from v$diag_info where name = 'Default Trace File';
INST_ID NAME VALUE
---------- ------------------------------ ------------------------------------
1 Default Trace File /u01/app/oracle/diag/rdbms/prod1/PROD1/trace/PROD1_ora_663_DUMP_TEST.trc
SQL> alter system dump datafile 4 block 133;
-- ALTER SYSTEM DUMP DATAFILE 1 BLOCK MIN 24419 BLOCK MAX 24420; -- dump多个块
1: BH (buffer header分析,同一个块可能有很多,都放在shared_pool相同的bucket中)
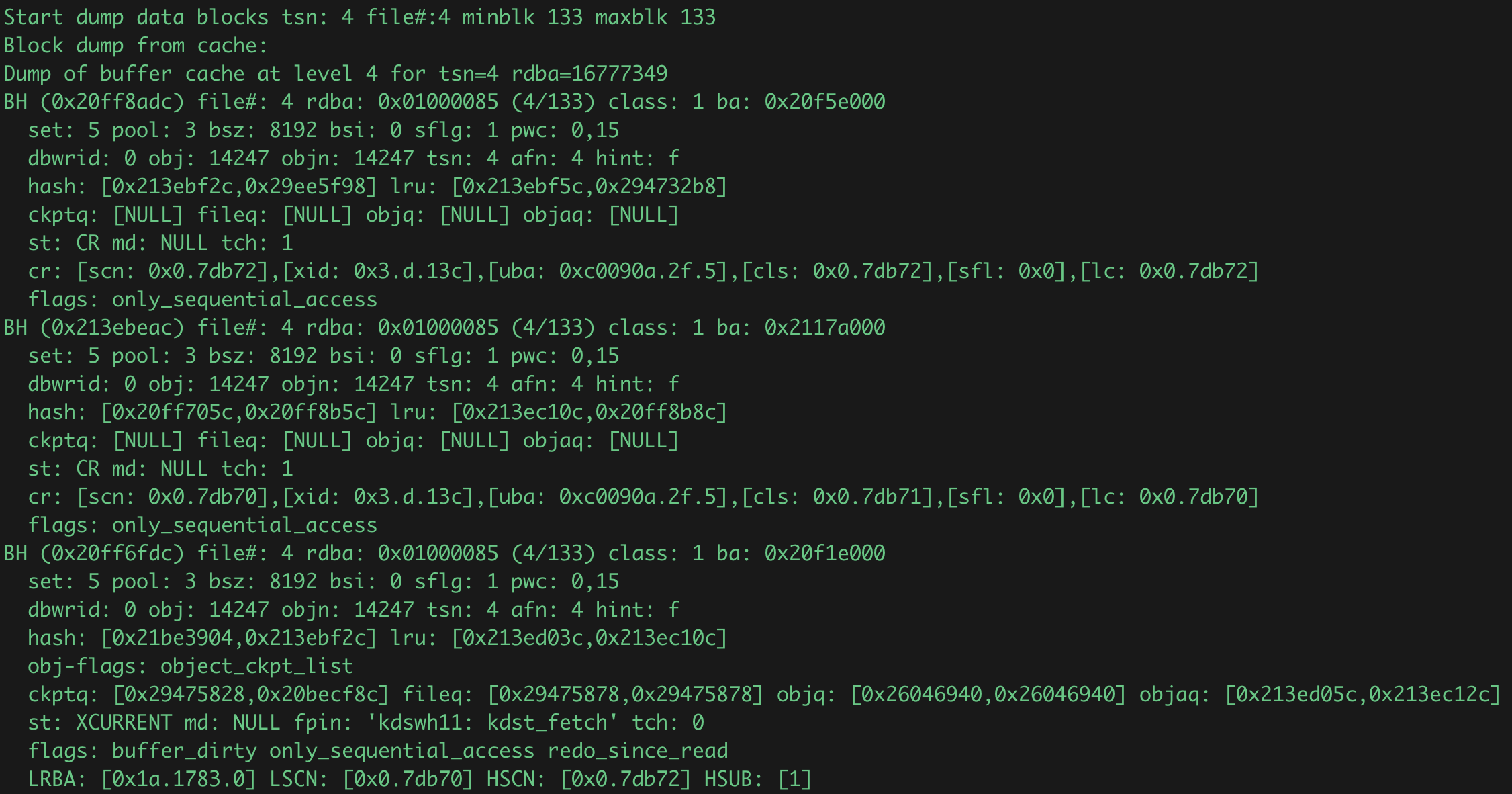
BH (0x20ff8adc)
-- BH的hash值,即此bh的内存地址
file#: 4
-- db内唯一的file_id
rdba: 0x01000085 (4/133)
-- 相对地址,由rfile和dba组成
class: 1
-- 块类型:1=data block, 9=2nd level bmb, 2=sort block, 10=3rd level bmb, 3=save undo block, 11=bitmap block, 4=segment header, 12=bitmap index block 5=save undo header, 13=unused, 6=free list, 14=undo header, 7=extent map, 15=undo block
ba: 0x20f5e000
-- 此buffer_header对应的buffer实际内存地址
bsz: 8192
-- block块大小
obj: 14247
-- dba_objects中的 DATA_OBJECT_ID,会发生改变
objn: 14247
-- dba_objects中的 OBJECT_ID,一般不会发生改变
hash: [0x213ebf2c,0x29ee5f98]
-- hash chain 指向上一个和下一个bh的hash地址
lru: [0x213ebf5c,0x294732b8]
-- lru链的上一个和下一个地址
ckptq: [NULL] fileq: [NULL] objq: [NULL] objaq: [NULL]
-- 相关队列,还未完全理解
st: CR
-- 对应v$bh中的state字段,标识块状态为一致性读块
tch: 1
-- 块访问计数,好像3s内访问不会变化
cr: [scn: 0x0.7db72],[xid: 0x3.d.13c],[uba: 0xc0090a.2f.5],[cls: 0x0.7db72],[sfl: 0x0],[lc: 0x0.7db72]
-- 相关的undo信息
flags: only_sequential_access
-- 块标记,还未理解
2.内存转储块数据(block header分析)
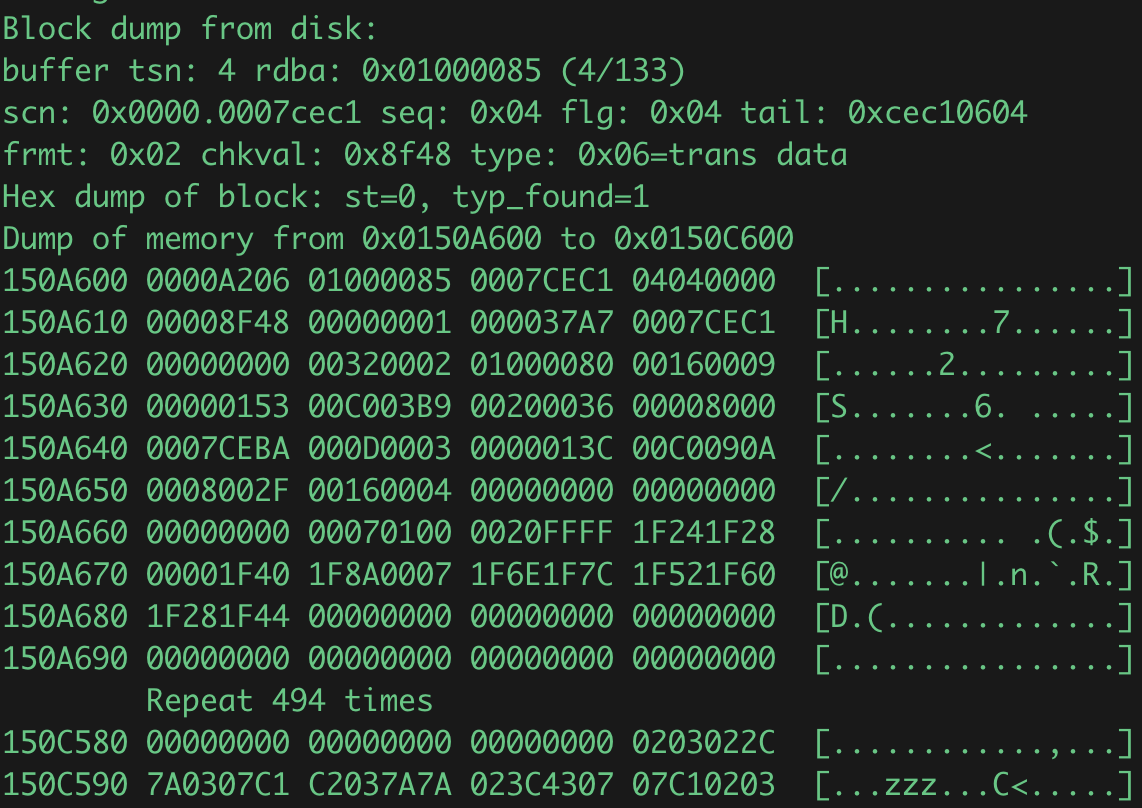
-- 这部分先列出了块的基本信息,然后是块的数据。转储的是内存,第一列是偏移量,可以手动从0000A206块开头字节计算,和上面列出的块基本信息是一致的。也可以使用dded转储,但bbed直接读磁盘文件数据,数据的块字节可能是反序存储的,需要注意,输出是(06a20000)。
buffer tsn: 4
-- 表空间号
scn: 0x0000.0007cec1
-- 块scn号,高低位分别由scn wrap和scn base组成
seq: 0x04
-- 在相同的SCN 下,该块可能会产生多次变化,使用序列号进行区分,如果SCN 增长,序列号复位为1,和scn、type一起组块块尾tail值用来校验块
flg: 0x04
-- 标记是否置于freelist(不确定)
tail: 0xcec10604
-- 块尾校验值,这也是未关闭的db,使用os copy数据文件不可用的原因,oracle block会根据块头信息校验块尾tail值,判断是否断裂、损坏
frmt: 0x02
-- 注意bbed中显示是a2,据说是为了保护敏感信息(8i~9i 都是0x02 10.1.0 2k: 0x62 4k:0x82 8k:0xa2 16k:0xc2 (logfile 0x22 512 bytes))
chkval: 0x8f48
-- 如果db_block_checksum=true时,block的核查值
type: 0x06=trans data
-- 标识为数据块类型(data/index)、段头、undo等 (1=undo segment header block; 2=undo data block; 0x10=DATA SEGMENT HEADER; 6=data block)
-- 后面是内存中块数据的16进制转储,8k块包含每行16字节,512行,中间有全0的行会省略。
3.disk转储块数据
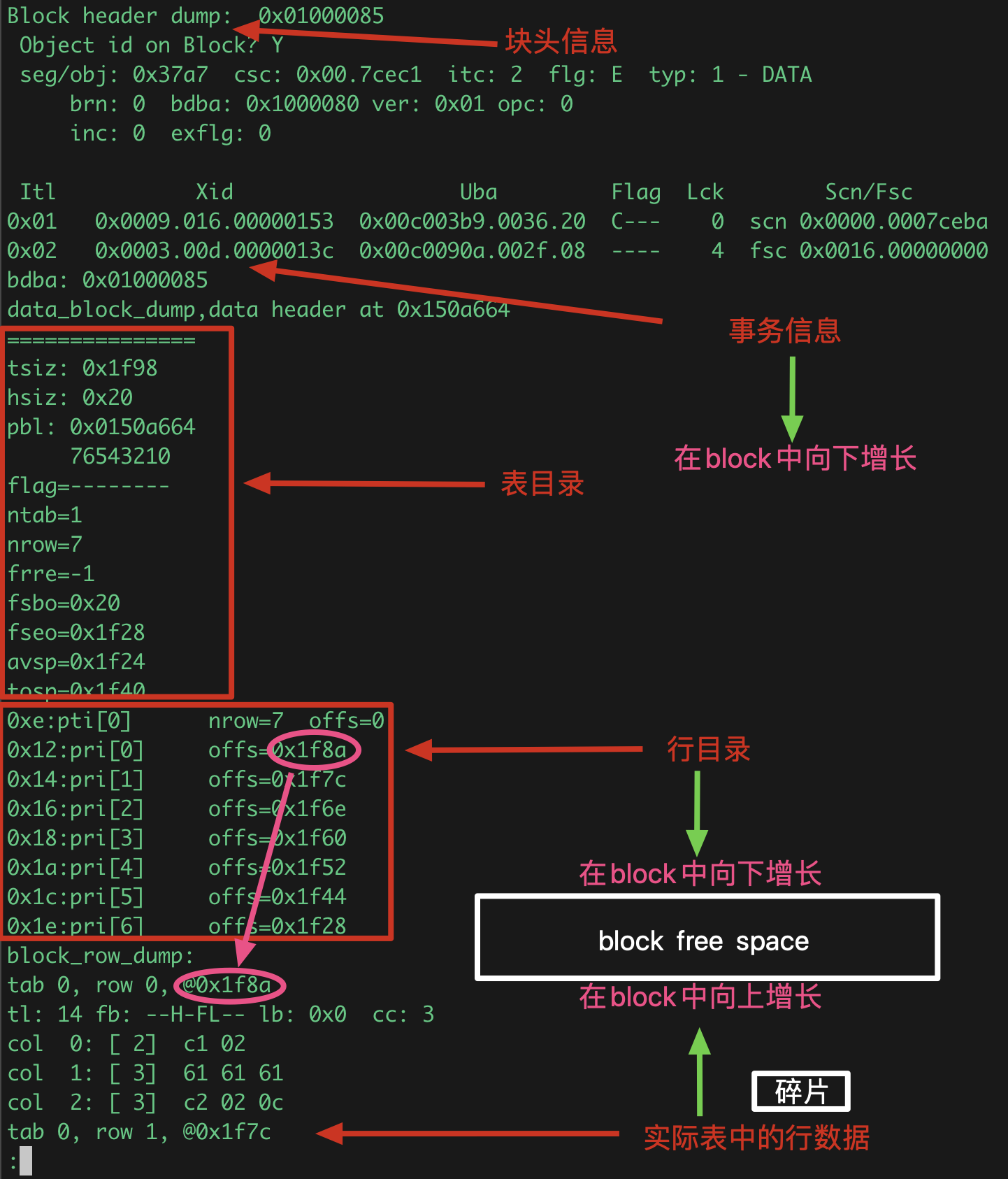
-- 块头(基本信息+事务信息)
0x01000085 -- rdba
csc: 0x00.7cec1 -- The SCN at which the last full cleanout was performed on the block
itc: 2 -- ITL 条目的个数 max 255超过会报ORA-02207 ORA-00060 ORA-00054 可能是没空间分配itl条目了或它的争用引起的,在8i中 INITRANS default为1 , 9.2.0中 INITRANS default为2
flg: E -- 标记块是否在freelist,assm为E
typ: 1 - DATA -- 数据类型,索引数据块显示为 typ: 2 - INDEX
Xid -- Transaction ID (UndoSeg.Slot.Wrap) 值可以用select XIDUSN, XIDSLOT,XIDSQN from v$transaction; 查到
Uba -- Undo address (UndoDBA.SeqNo.RecordNo)
Flag -- 我这测试案例2个事务,第2个删除3条插入1条记录还未提交,所以这里显示 lck=4
-- C = Committed;
-- U = Commit Upper Bound;
-- T = Active at CSC;
-- B = Rollback of this UBA gives before image of the ITL.
-- ---- = transaction is active, or committed pending cleanout
-- C--- = transaction has been committed and locks cleaned out
-- -B-- = this undo record contains the undo for this ITL entry
-- --U- = transaction committed (maybe long ago); SCN is an upper bound
-- ---T = transaction was still active at block cleanout SCN
-- 数据头(数据头信息+表目录+行目录)
tsiz: 0x1f98 -- Total data area size (tsiz: hsiz: pbl: bdba: 在数据文件都是没有存储的)
hsiz: 0x20 -- Data header size
pbl: 0x00648264 -- Pointer to buffer holding the block
ntab=1 -- 这block中有几个table的数据 cluster这个就可能大于1
nrow=7 -- block 有多少行数据
frre=-1 -- First free row index entry. -1=you have to add one.
fsbo=0x20 -- Free Space Begin offset 除去row dict 后面的可以放数据的空间的起始位置也可以看成是从这个区域的开始"flag"到最后一个 "row offs"占用的空间
fseo=0x1f28 -- Free Space End offset ( 9.2.0 )参与db_block_checking的计算剩余空间 select 的时候oracle不是简单的根据offset定位row.这个值也是参与了定位row的
avsp=0x1f24 -- Available space in the block (pctfree and pctused)
tosp=0x1f40 -- Total available space when all TXs commit ( 9.2.0 )参与db_block_checking
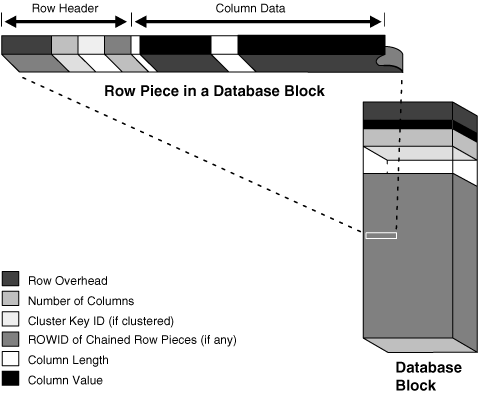
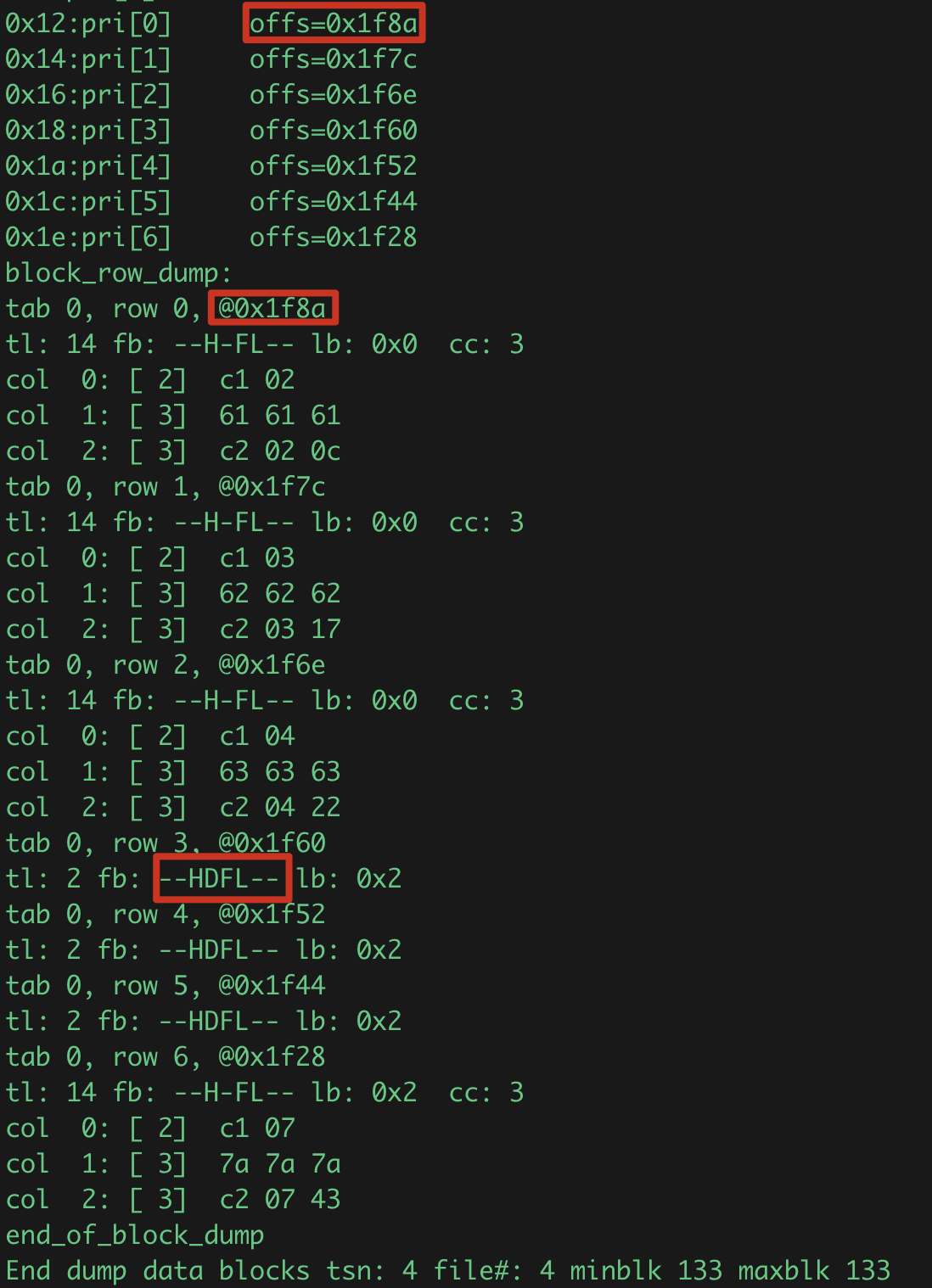
-- 数据行就按照标准的格式,行头的列数等+每一列的长度、值组成,一般按照create table定义顺序存储列,long和lob除外,默认255个列都存储为一个piece。
offs -- 偏移量 , row dicrectory中的插槽点记录的offs指向行头位置
-- 933 0x2d8:pri[355] sfll=356 rollback的行也会保留行目录的插槽点,可以重用,显示未sfll,没有offs,这里未演示。
tl: 2 fb: --HDFL-- lb: 0x2
-- 行4,5,6行删除未提交,所以itl中lck有值,这里多出一个D标记,标识row被删除了,感兴趣可以使用bbed尝试恢复
-- 注意这里的fb: --H-FL--。 其有8个选项,每个值分别与bitmask 对应。
-- Therefore,columns that fit within a single block, are not chained, migrated or part of aclustered table and are not deleted will have the following attributes:
-- (1)Head of Row Piece
-- (2)First Data Piece
-- (3)Last Data Piece
-- 如果一个row 没有被删除,那么它就具有上面的3个属性,即Flag 表示为:--H-FL--. 这里的字母分别代表属性的首字母。其对应的值:32 + 8 + 4 =44 or 0x2c.
-- 如果一个row 被delete了,那么row flag 就会更新,bitmask 里的deleted 被设置为16. 此时row flag 为: 32 + 16 + 8 + 4 = 60 or 0x3c.
# 这里主要分析的是普通table的data block结构,和其他的index data block,extent header,segment header都是不同的,每个逻辑存储结构在块的头部都有相应的标准结构,用于快速、高性能的分配、回收和查询块等等使用,大家可以自己dump深入研究。
bbed分析块结构和数据
-- 1. 查看 block 结构
BBED> map /v dba 4,133
File: /u01/app/oracle/oradata/PROD1/users.dbf (4)
Block: 133 Dba:0x01000085
------------------------------------------------------------
KTB Data Block (Table/Cluster)
struct kcbh, 20 bytes @0
ub1 type_kcbh @0
ub1 frmt_kcbh @1
ub1 spare1_kcbh @2
ub1 spare2_kcbh @3
ub4 rdba_kcbh @4
ub4 bas_kcbh @8
ub2 wrp_kcbh @12
ub1 seq_kcbh @14
ub1 flg_kcbh @15
ub2 chkval_kcbh @16
ub2 spare3_kcbh @18
struct ktbbh, 72 bytes @20
ub1 ktbbhtyp @20
union ktbbhsid, 4 bytes @24
struct ktbbhcsc, 8 bytes @28
sb2 ktbbhict @36
ub1 ktbbhflg @38
ub1 ktbbhfsl @39
ub4 ktbbhfnx @40
struct ktbbhitl[2], 48 bytes @44
struct kdbh, 14 bytes @100
ub1 kdbhflag @100
sb1 kdbhntab @101
sb2 kdbhnrow @102
sb2 kdbhfrre @104
sb2 kdbhfsbo @106
sb2 kdbhfseo @108
sb2 kdbhavsp @110
sb2 kdbhtosp @112
struct kdbt[1], 4 bytes @114
sb2 kdbtoffs @114
sb2 kdbtnrow @116
sb2 kdbr[7] @118
ub1 freespace[7944] @132
ub1 rowdata[112] @8076
ub4 tailchk @8188
-- bbed map这个命令解释的block结构就比trace转储的更加清晰了,只是它的块组成结构需要我们自己慢慢理解,分析和计算,没给直接显示出来,按后面的偏移量结合bbed的dump转储数据计算基本都是一致的。
-- 从上至下分别是:
block header 标准信息
事务信息
data header 标准信息
表目录
行目录
free space
row data
tail check
-- 2. 转储 block 数据
BBED> dump /v dba 4,133 count 120
File: /u01/app/oracle/oradata/PROD1/users.dbf (4)
Block: 133 Offsets: 0 to 119 Dba:0x01000085
-------------------------------------------------------
06a20000 85000001 72db0700 00000104 l .�......r�......
fb9a0000 01000000 a7370000 72db0700 l �.......�7..r�..
00000000 02003200 80000001 09001600 l ......2.........
53010000 b903c000 36002000 00800000 l S...�.�.6. .....
bace0700 03000d00 3c010000 0a09c000 l ��......<.....�.
2f000800 04001600 00000000 00000000 l /...............
00000000 00010700 ffff2000 281f241f l .......... .(.$.
401f0000 07008a1f l @.......
<16 bytes per line>
-- 注意bbed直接从datafile转储的数据高低位和os cpu平台有关,我这里高低位就是反序从右至左反过来存储的,<06a20000 85000001>按照map解释的偏移量计算如下:
struct kcbh, 20 bytes @0
ub1 type_kcbh @0
ub1 frmt_kcbh @1
ub1 spare1_kcbh @2
ub1 spare2_kcbh @3
ub4 rdba_kcbh @4
ub4 bas_kcbh @8
type -> 06
frmt -> a2
spare1 -> 00
spare2 -> 00
rdba -> 01000085 -- 和之前trace转储的 Block header dump: 0x01000085 是一致的
3. rowid和rownum


- rowid和rownum都是伪列,在block中不实际物理存储的。
- rowid是通过上图4部分组成,唯一标识一行。
- rowid在move、导出导入、行迁移、闪回等情况可能发生改变(所以也是ogg环境需要开启附加日志,普通的redo记录信息由于源和目标不同的rowid环境无法确保数据一致的一个原因)。
- rowid不存在数据块中,但存在index数据块中,index行就有2列:key和rowid值(方便快速定位需要行)。
- rownum是一个结果集的行号,记录一定从1开始,不能像这样直接查询rownum>10,直接排除前面1-9的记录,需要使用子查询和排序。
4. 行链接和行迁移:
行插入块,由数据块底部向上,一行跟一行,每行都是行头+行数据(1个或多个piece,默认1个),一般每个piece中的 列长+data+列长+data…每行数据长度都不一定相同,除了char固定列长度补齐存储,慢慢把hwm向上推进直到block的pctfree或者pctuse阈值。del和update会变成free空间,但是零碎,如果能放入行或piece就可以重复使用,放不下的就是碎片,当free到达阈值时oracle自己合并这些碎片空间避免浪费,也不会经常合并影响性能。
- 行链接:
一般插入产生,默认行少于255列都放1个piece,当超过255列甚者1000多个列时会有多个piece进而形成行链;字段太长,比如有很多个varchar2(4000),而block size又是2k、4k太小,一行数据就占有几十k数据,一整个block都放不下一整行也会导致行链产生。 - 行迁移:
一般更新产生,字段数据从null或者小值变成大值,本块放不下,但是整行数据可以放在一个块里,这样就直接迁移一整行数据迁移到其他block。
个人理解: 行链和迁移都是在在原行位置放置一个标记点,指向后面的多个piece数据或者行数据,不同的场景rowid可能变也可能不变,具体看block有没有被释放又再次使用。oracle优先发生行迁移,优先在本块发生,这样避免读更多的块降低性能。
5. 相关优化:
- 选择合适的blocksize,太小可能影响单次IO吞吐和产生很多行链,太大可能造成热块冲突和浪费空间。
- 设置合适的INI_TRANS参数,避免频繁dml的块产生ITL事务槽等待。
- 一般使用assm管理,通过pctfree控制块的空间使用和性能平衡。
- 尽量减少行链和行迁移产生,造成额外的读和锁。
结语:
本次就简单了解学习oracle数据块,并未深入很多细节和扩展到index、extent等其他,自己整理记录希望能帮到自己和大家,如有错误理解欢迎指正。
自己现在技术还很差,对oracle概念和实施方面还不错,本次深入了解一下oracle block内部结构,方便日后提升相关恢复技能。
我自己看了不少书,相对实践较少,工作经验也不足,以后要勤加练习,最想告诉想深入学习oracle但和我一样刚入门的朋友,尽量多看看oracle官方文档,oracle concepts一定要好好看至少,会经常有种豁然开朗的感觉。
遇到问题可以先看看官方文档指导,然后再结合谷歌和mos,因为mos有些19c的相对新的还是比较少,比如dg lag解决,在18,19都有新解决方案,所以建议学习或者有问题一定要多看官方手册。
