




在oracle数据库中,表的连接方法有排序合并连接、嵌套循环连接、哈希连接以及笛卡尔连接,针对自我学习和理解,在这里进行梳理:
排序合并连接## 二级标题
排序合并连接是先使用排序然后再合并的连接方法;
将两个需要连接的表各自排序好,经过谓词条件的过滤筛选后剩下的结果集,一个标志为结果集1,一个标志为结果集2。
结果集的第一条记录开始匹配结果集2的第一条记录,在匹配的过程中,如果匹配成功,则记录下结果集2的记录位置,下次进行第二条记录匹配时从记录的位置开始也就是避免扫描结果集2的全部记录。
下面通过实验说明一下:
首先构造两个比较简单的表
SQL> create table test1 (id number,name varchar2(10));
Table created.
SQL> create table test2(id number,name varchar2(10));
Table created.
SQL> select /+ leading(a) use_merge(b)/ a. from test1 a,test2 b where a.id=b.id;
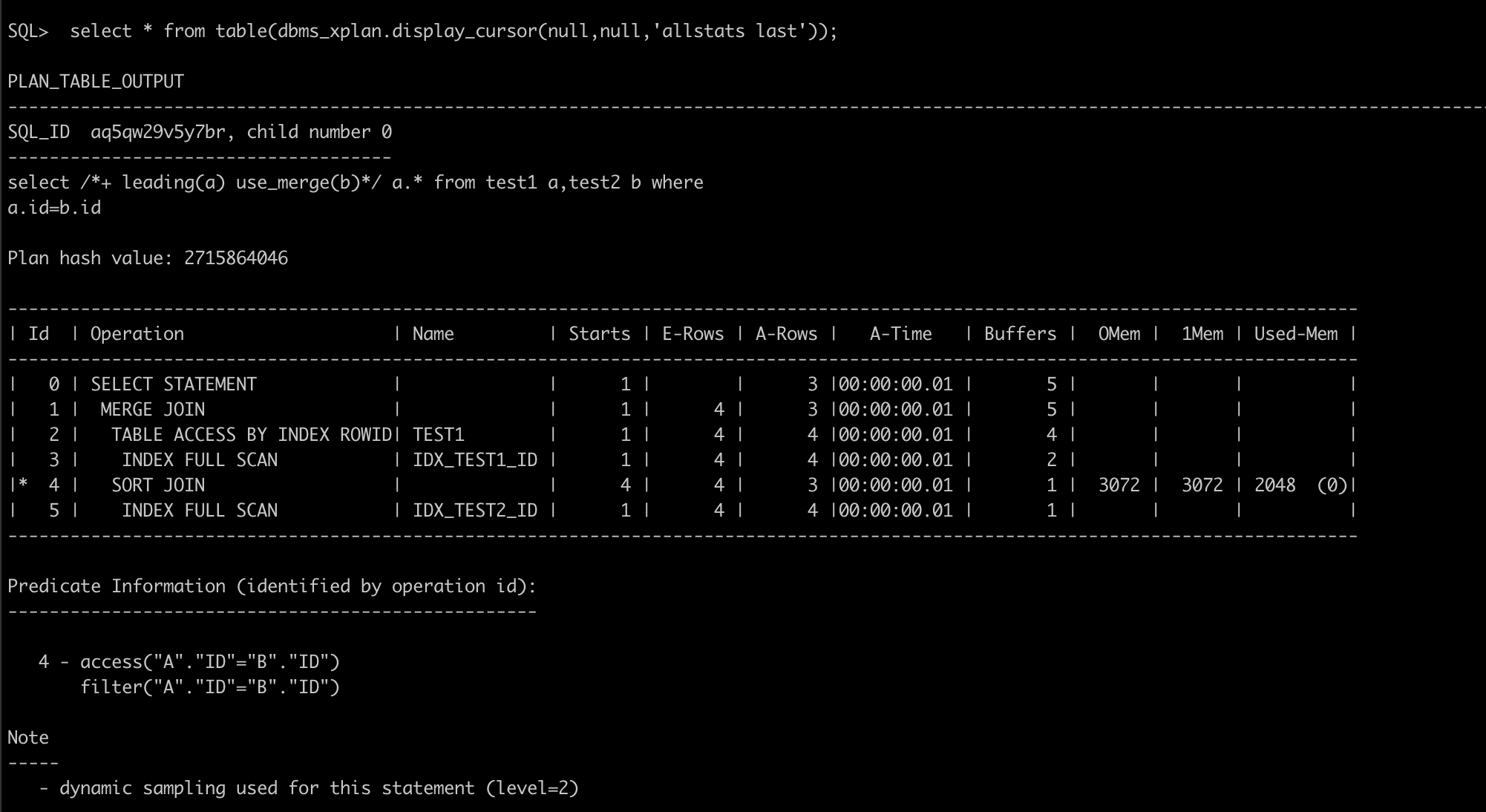
然后通过hint让执行计划走排序合并的方法进行表连接
alter session set statistics_level=all;
select * from table(dbms_xplan.display_cursor(null,null,‘allstats last’));
通过设置以上查看更详细的执行计划每个步骤消耗信息
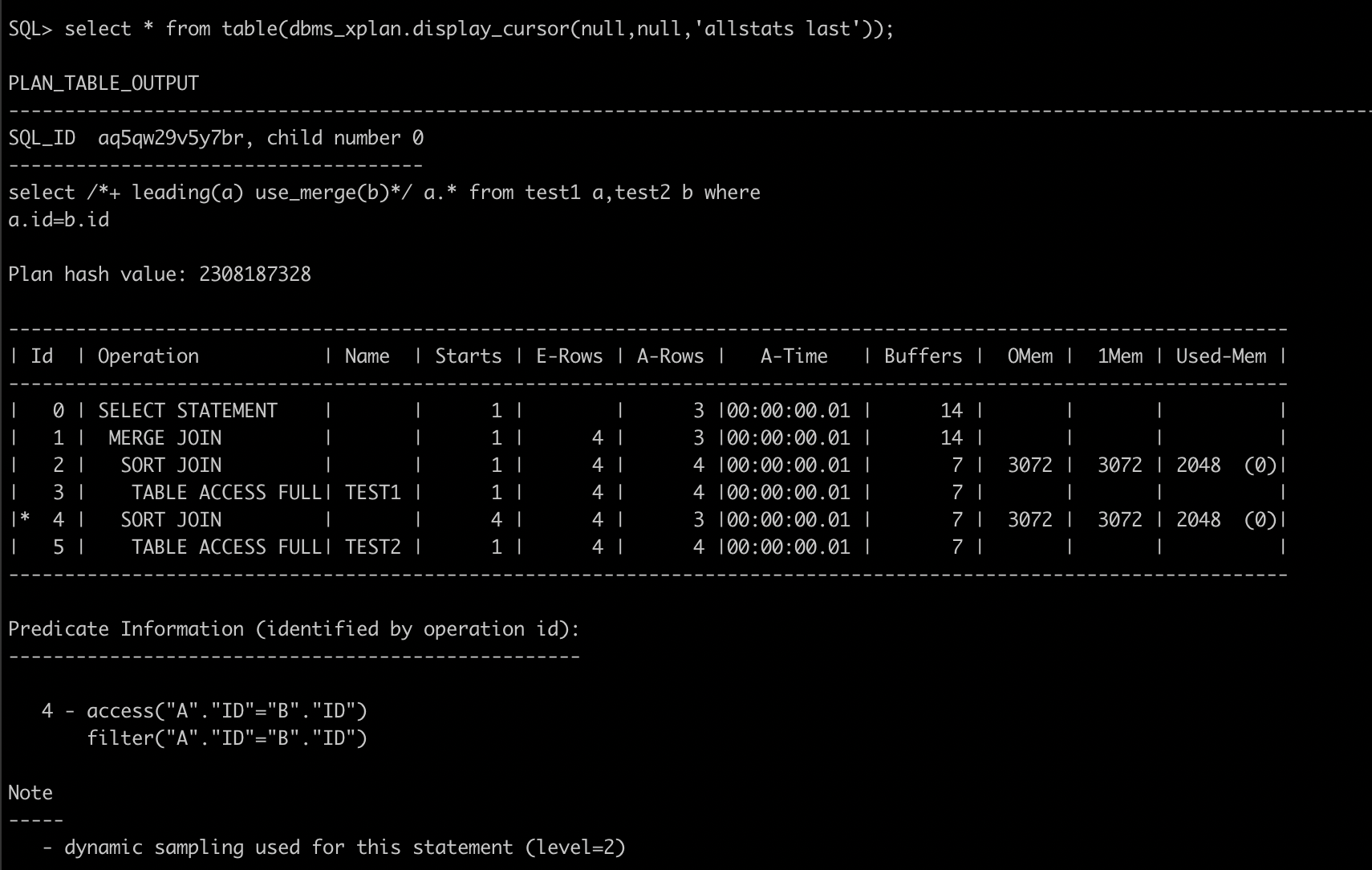
通过执行计划可以看到,执行步骤为3-2-5-4-1
也就是首先对test1进行全表扫,然后进行按id排序,接着对test2进行全表扫,然后也进行按id排序,starts表示对两表的访问次数,皆为1。而后面的E-ROWS表示预计返回的结果集行数,A-ROWS表示实际返回的结果集行数,A-TIME表示实际使用的时间
0Mem 指的是预计在 PGA 中排序需要的内存大小
1Mem 指的是当内存大小(PGA)不足以进行排序, 预计将数据一次交换到磁盘空间的内存大小
Used-Mem 指的是执行时实际使用的内存大小, 其中括号中的数字代表进行磁盘交换的次数, 0 代表没有进行磁盘交换
接下来就简单的对整个排序合并的过程进行梳理:
首先查看以下是从官方文档copy的关于排序合并的伪代码
READ data_set_1 SORT BY JOIN KEY TO temp_ds1
READ data_set_2 SORT BY JOIN KEY TO temp_ds2
READ ds1_row FROM temp_ds1
READ ds2_row FROM temp_ds2
WHILE NOT eof ON temp_ds1,temp_ds2
LOOP
IF ( temp_ds1.key = temp_ds2.key ) OUTPUT JOIN ds1_row,ds2_row
ELSIF ( temp_ds1.key <= temp_ds2.key ) READ ds1_row FROM temp_ds1
ELSIF ( temp_ds1.key => temp_ds2.key ) READ ds2_row FROM temp_ds2
END LOOP
对于第一数据集中的每一行,数据库在第二数据集中找到起始行,然后读取第二数据集,直到找到不匹配的行。当t1表中的数据<=t2表的数据的时候,返回t1,扫描t1下一行,当t1表中的数据>=t2表的数据的时候,继续扫描t2表的下一条数据。(个人对代码的理解)
第一步:对于test1,test2中的数据扫描并排序
第二步:开始进行选择条件的合并
这里的条件是test1.id=test2.id,返回符合这个结果的test1的数据






第三步:返回符合选择条件的结果集。
综上,符合条件的id=1,2,4的数据被选择出来。
从上面可以看出,在读取test1表中的每一条数据时,并没有去读取t2表中的每一条数据,而嵌套循环连接是这样做的。
排序合并算法在这个案例的消耗点:
1、全表扫描
2、对于结果集的排序
所以在遇到排序合并连接带来的优化问题时,创建适合的索引来减少排序是一个优化的思路;
PS:以上均为个人学习之后的理解,如有错误,恳请指正。
学习资料:《oracle官方文档》、《基于oracle的sql优化》
