周末应PG社区的邀请分享一个2015年时候写的关于PG的MVCC实现与应用场景优化的话题。今天早上起来准备把那篇文章整理整理。就想着顺便和大家讨论下关于Oracle、Mysql和PG这当今五大数据库之三的MVCC实现方式的差异,以及在应用场景选择上应该注意的问题。
关于MVCC是啥,MVCC的基本原理前些天我发过一篇文章,里面就介绍了这方面的内容,如果有兴趣的朋友可以去我的公众号上翻阅。MVCC叫多版本并发控制,是采用数据多版本技术解决并发访问时读不阻塞写,写不阻塞读的问题的。
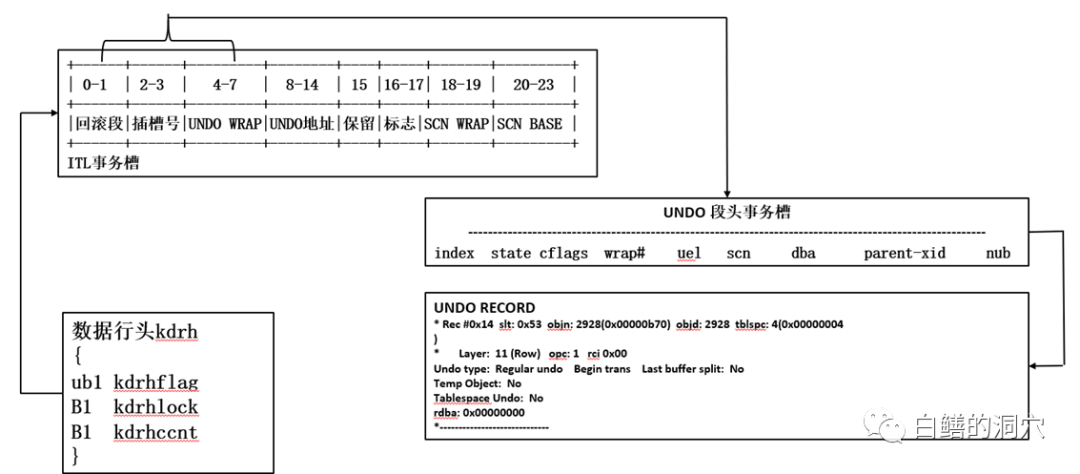
如上图所示,Oracle的多版本并发控制是块级(BLOCK LEVEL)的,基于Oracle UNDO/回滚段机制。在回滚段中保存了某个数据被修改之前的前映像的数据。在每条记录的记录头(kdrh)中,kdrhlock指向前一次修改该数据的事务槽(ITL)的位置,kdrhccnt指出了这个事务中在本块受影响的行的数量。在ITL中记录了该次修改的SCN信息,以及回滚段的地址信息。
当某个事务开始的时候,会在回滚段的段头TRNTBL中分配一个事务表记录,同时分配第一个UNDO记录,记下事务的一些信息。当事务修改某个数据的时候,在该数据的DATA BLOCK的ITL表中分配一个ITL记录,并锁定这个ITL记录,然后将数据行头中的kdrhlock指向这个ITL槽,然后再对数据进行修改。并把修改前的数据存储在回滚段的UNDO RECORD中。如果有事务要读取相关的数据,首先对数据库的DBCACHE缓冲区进行搜索。在Oracle的DB CACHE中,同一个数据块可能存在多个版本,这些版本被称为CR BLOCKS。如果在DB CACHE中已经找到了符合条件的CRBLOCK(根据SCN来判断CR BLOCK是否符合查询条件),就可以直接使用,如果没有找到可用的CR BLOCK,那么就需要通过该数据块的当前版本(CURRENTBLOCK)来生成所需要的CRBLOCK。在生成CR BLOCK的时候,可以根据该行数据的kdrhlock找到相关的ITL槽,通过比对SCN来判断要读取的数据是数据块中的数据还是修改前的数据。如果发现当前ITL槽中的SCN高于本事务所需要读取的SCN,那么就会通过ITL槽找到该数据在UNDO中的前映像数据(PRE-IMAGE),通过前映像数据和当前数据生成一个一致性读块(CR BLOCK),然后通过访问这个CRBLOCK来找到所需要读的数据。实际环境中可能更为复杂,因为ITL槽可能会被覆盖,在这种情况下,Oracle会把ITL信息写入UNDO RECORD中,形成一个链状结构,可以一层层的找到所需要的UNDO RECORD,从而完成这种操作。Oracle的多版本并发控制机制使用了一个独立的UNDO 表空间来存储UNDO数据,数据的前映像通过在DB BUFFER中的CR BLOCK来实现,因此数据无论修改多少次,都不会对存储数据的数据段产生负面的影响。而且一个CR BLOCK生成后,可以在缓冲区中较长时间内存在,供相关的事务使用。这个功能对于大并发的读操作来说,是十分有用的,可以大大提高相关操作的性能。由于Oracle UNDO的空间容量有限,因此不可能永久保存回滚段的数据,Oracle采用了UNDO RETENTION的机制来保护UNDO数据,可以设定一定的UNDO数据保存周期,当UNDO数据在保护期内,可以保证UNDO记录不被覆盖。这种机制很好的解决了UNDO数据生命周期管理的问题,同时确保了在一个大型查询中确保所需的PRE-IMAGE不会被覆盖失效。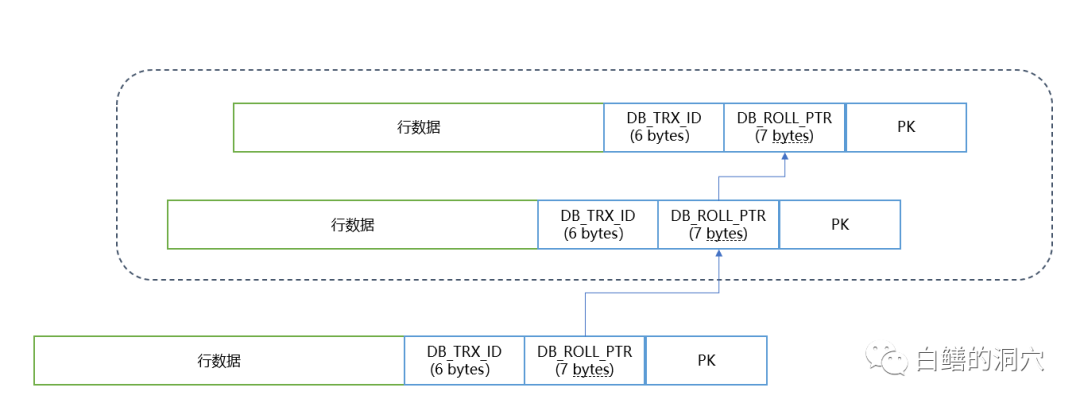
对于Mysql Innodb来说,是通过UNDO来实现行的版本链的。和Oracle不同的是,Oracle的多版本实现是按block的,而Innodb是采用的记录级的。具体做法是通过两个隐含列来实现的。一个是db_trx_id,指出该行的事务ID,一个是db_roll_ptr,指出这条记录的pre-image数据在UNDO中的地址。有了行版本链后,后面要实现MVCC就比较容易了,Innodb采用了RedView来实现数据版本的筛选。ReadView有三个主要元素:up_limit_id:当前已经提交的事务号 + 1,对于事务号 < up_limit_id 的数据,当前Read View都是可见的。从而确保SQL发起前的数据版本的可见性;
low_limit_id:当前最大的事务号 + 1,对于事务号 >= low_limit_id的数据,当前Read View都是不可见的;
trx_ids:为当前活跃事务id列表,即Read View初始化时当前未提交的事务列表。所以当进行可重复读(RR)的时候(Mysql Innodb引擎的缺省事务隔离级别,注意这是和Oracle的read commited是不同的),trx_ids中的事务对于本事务是不可见的,当然本会话自身的事务对于本会话都是可见的,这一点很容易理解。
到了PostgreSQL,情况的差异就比较大了。Post过热SQL也是采用行级别的多版本。其实现手段是在数据表中保存某条数据的多个版本。比如说要对某条记录进行修改,并不是直接修改该数据,而是通过插入一条全新的数据,同时对老数据加以标识。而删除数据也不是直接删除该数据,而是在相应的数据行上打上一个删除标识。为了更好的理解这种多版本并发控制机制,我们首先来看一个十分重要的数据结构HeapTupleHeaderData和HeapTupleFields。HeapTupleHeaderData是每一行数据的头结构,其定义如下:

HeapTupleFields是用于多版本并发控制的核心数据结构,其定义如下:

HeapTupleFields结构是PostgreSQL实现MVCC的核心数据结构,xmin,xmax,cmin,cmax和xvac是其中最为关键的字段。下面我们通过数据结构来看看PostgreSQL的MVCC工作机制。当一条记录被插入到数据库时,其xmin字段被存储为本事务的XID,xmax为0,当事务提交后,所有的事务的XID大于等于xmin中存储的XID的事务,都可以看到这条记录。这完全符合read commited事务隔离级别的要求。如果该记录被删除,在PostgreSQL中,暂时不会删除这条记录,而是会在这条记录上做一个标识。PostgreSQL的做法是将该记录的xmax设置为删除这条记录的事务的XID。这样,所有的该记录删除后的事务的XID都大于xmax的值,因此删除后发起的查询都无法读取到这条记录;而对于删除这条记录之前的启动的查询,由于XID小于xmax,因此仍然可以读取到这条记录。这样就解决了MVCC的事务隔离和一致性读的问题。如果该记录被修改(update)了,那么PostgreSQL不会直接修改原有的记录,而是会生成一条新的记录,新记录的xmin为update操作的XID,xmax为0,同时会将老记录的xmax设置为当前操作的XID,也就是说新记录的xmin和老记录的xmax相同。这样在同一张表中,同一条记录就会有存在多个副本。由于数据多副本的存在,在索引中也会产生类似的多副本情况,因此当DML操作产生时,索引页会做相关的调整。从PostgreSQL的MVCC机制工作原理来看,INSERT操作并没有太多的问题,PostgreSQL的INSERT操作和其他数据库的工作原理十分类似,只是PostgreSQL的行头大小为20字节,远远大于Oracle的3字节,也比Mysql略大。因此PostgreSQL的存储额外开销要略大于Oracle。从DELETE操作来看,三种数据库的操作极为类似,都不会直接从数据块中直接删除这条记录,而是设置一个删除标志。对于PG和Mysql Innodb来说,都通过一个独立的机制来进行数据回收。Oracle的数据处理一直是BLOCK级别的,因此下一次块重组的时候,这些数据记录空间就会被自动回收。这种情况可能导致Oracle数据库有大量数据块被删除后,过一阵子会产生大量的REDO,而不是删除操作本身。同时数据库相关表的性能也会略有下降,等数据重组完成后,这个影响就消失了。当然对于大多数应用来说,可能感受不到这种影响。
从UPDATE操作来看,无论UPDATE多少个字段,PostgreSQL都需要插入一条新的记录,这样会造成SEGMENT高水位的增长,如果某张表的数据插入后,需要多次UPDATE,那么这张表的高水位会出现暴涨。为了解决这个问题,PostgreSQL使用了一个版本回收机制----VACUUM。通过VACUUM,PostgreSQL可以回收旧版本,从而避免多版本带来的性能问题。从上面的MVCC实现原理上看,对于PG数据库来说,要十分注意一些场景问题。对于一些频繁UPDATE的数据表,应该采用内存缓冲来避免数据多副本带来的问题,特别是一些多字段的宽表,一定采用内存缓冲,定期刷新的方式,否则会出现很难解决的性能问题。如果解决好这些问题,PG库在高并发交易型应用场景下也可以有好的表现。
从MVCC机制上看,Oracle是CR BLOCK机制的,这种方式对于单块中有多条数据变更,并且CR BLOCK会多次使用的大并发场景,比MYSQL与PG的优势更大。





