




背景
支持常见数据数据库的数据实时采集,快速发现数据变化,能够保持数据一致,即正确同步源系统数据并且不改变数据逻辑; 支持大规模高并发数据流的缓存队列,易于扩容; 支持高并发实时数据加工计算; 低成本的分布式存储管理海量数据,支持大规模高并发处理能力,支持同城双活、异地灾备; 提供对外查询服务,服务支持权限管理、元数据管理、监控管理等,服务支持集群化部署,具备高可用机制,无单点故障。
逻辑架构
实时数据服务的主要逻辑架构应该包括数据采集、数据处理、数据存储和接口服务等层次。实时数据流从采集层次进入,经过数据处理和存储层次之后,通过数据接口服务层流出系统。
总体的逻辑架构如下图所示:
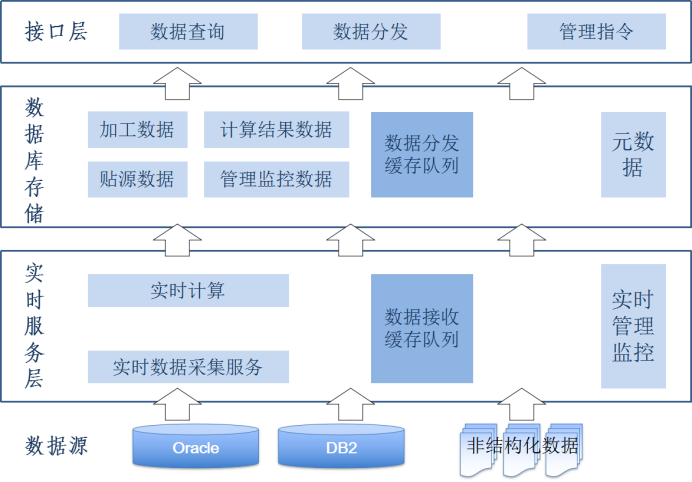
数据源
数据源是数据的产生者。数据源产生的数据作为实时数据交换系统的输入数据,供数据消费者使用。
实时数据交换系统需要支持如下类型的数据源的接入,即可以采集如下类型的数据源:
1. 常见关系型数据库,例如Oracle、DB2等数据库;
2. 数据文件,例如应用日志文件、系统日志等;
数据采集服务模块需要在数据源端部署数据采集组件,方能实现实时探知数据变化,并将变化数据采集发送到实时数据交换系统服务端。
实时数据采集服务
数据缓存队列
监控和管理
技术方案
整体架构方案通过数据实时抽取+复制的机制,将业务系统源库中的数据或日志数据实时抽取并发送至缓存队列。流处理引擎则从缓存队列中分批拉取数据,对每一条数据进行解析和加工,并复制到实时数据服务平台的对应模型中。该平台同时需要满足实时查询的需求,可满足数据查询下移、实时统计、预测等业务需求。
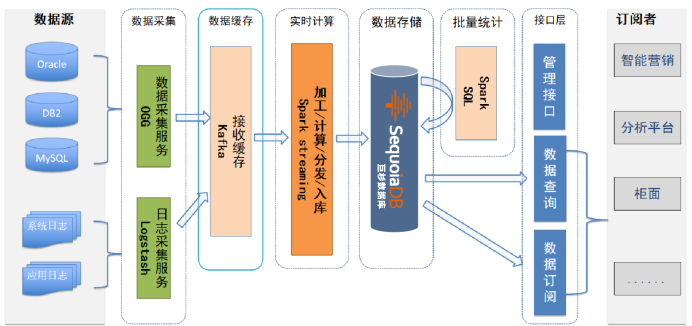
数据采集
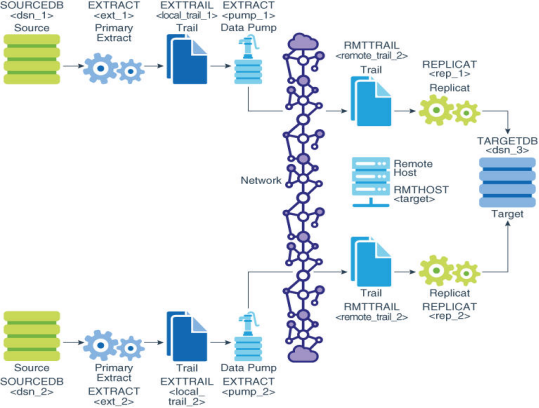
Extract:Extract 进程运行在数据库源端上,它是OGG的捕获机制,可以配置Extract 进程完成“初始化数据”和“ 同步数据变化”。
Data Pump:是一个配置在源端的辅助的 Extract 机制,是一个可选组件,如果不配置 Data Pump,那么由 Extract 主进程将数据发送到目标端的 Remote Trail 文件中,如果配置了 Data Pump,会由 Data Pump将Extract 主进程写好的本地 Trail 文件通过网络发送到目标端的 Remote Trail 文件中。
Trail:为了持续地提取与复制数据库变化,OGG将捕获到的数据变化临时存放在磁盘上的一系列队列文件中,这些文件叫做 Trail 文件。
Collector:Collector 是运行在目标端的一个后台进程,接收从 TCP/IP 网络传输过来的数据库变化,并写到 Trail 文件里。
Replicat:Replicat 进程是运行在目标端系统的一个进程,负责读取 Extract 进程提取到的数据并应用到目标数据库,可以配置 Replicat 进程完成“初始化数据”和“数据复制”。
数据缓存
{“table”: 表名,以schema.tablename作为表名“op_type”: 操作类型(I、U、D)(I:insert、U:update、D:delete)“op_ts”: 本条消息在OGG源端抽取的时间戳“current_ts”: 本条消息同步到Kafka的时间戳“pos”: 消息在OGG源端trail文件中的位置(sequence number+offset)“primary_keys”: 表的主键字段“before”: // 操作执行前的数据“after”: // 操作执行后的数据}
数据加工
数据加工层采用Spark Streaming实时流处理框架。在该层中,使用可靠读取的方式从Kafka队列中获得相应的数据,然后在JSON数据中解析表名,操作符以及时间戳,再根据操作符解析需要的插入、删除、更新的相应字段。
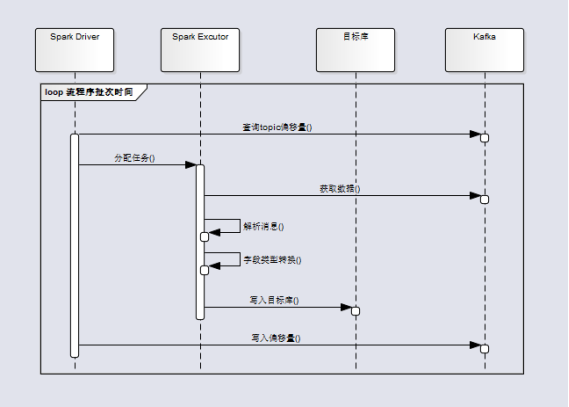
数据处理流程:
1. SparkStreaning 引擎根据配置的批处理间隔,Driver 进程周期性的查询Kafka对应topic的偏移量,如果有新的数据到达,Driver 将消息的分区和偏移量信息传递给各Excutor进程,Excutor 进程拉取对应的数据。
2. 流程序根据 JSON 格式消息中的表名称,获取该表对应目标库(SequoiaDB)表名称和字段类型。
3. 获取到集合空间和集合后,将消息中的字段值进行相应的类型转换,并生成对应的 BSONObject 对象,最后执行对应的更改。
4. Driver 进程向 kafka 提交处理完成的消息偏移量。
数据存储
数据的存储采用分布式数据库 SequoiaDB。将海量数据保存在 SequoiaDB 分布式数据库中,利用数据库自身的分布式存储机制与多索引功能,能够很好地为应用提供高并发、低延时的查询服务。
SparkStreaming 实时处理数据时,通过调用 SequoiaDB 原生 API 接口将解析后的数据存储到SequoiaDB中,数据库底层采用多维分区的方式将数据分散到多个数据分区组上进行存储。该方式通过结合了 Hash 分布方式和 Range 分布方式的优点,让集合中的数据以更小的颗粒度分布到数据库多个数据分区组上,从而提升数据库的性能。
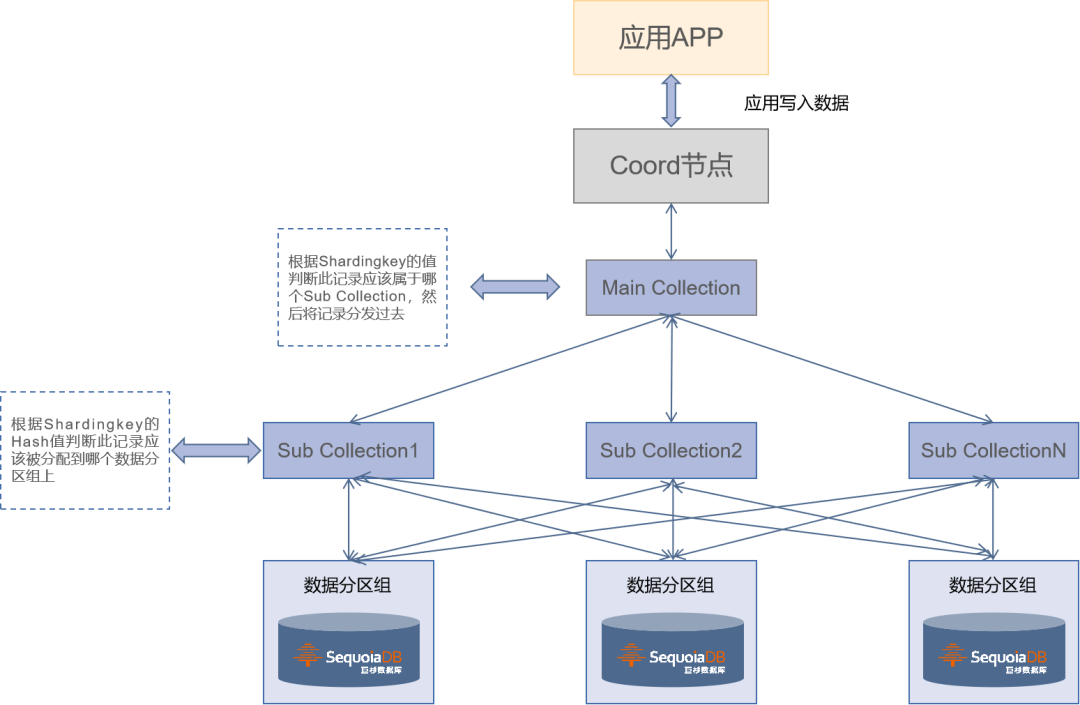
采用分区的目的主要是为了解决单台服务器硬件资源受限问题,如内存或者磁盘 I/O 瓶颈,使得机器能够得到横向扩展;此外还能将系统压力分散到多台机器上,从而提高系统性能,并且不会增加应用程序复杂性。再结合 SequoiaDB 的副本模式,保证系统的高可用性。
数据查询
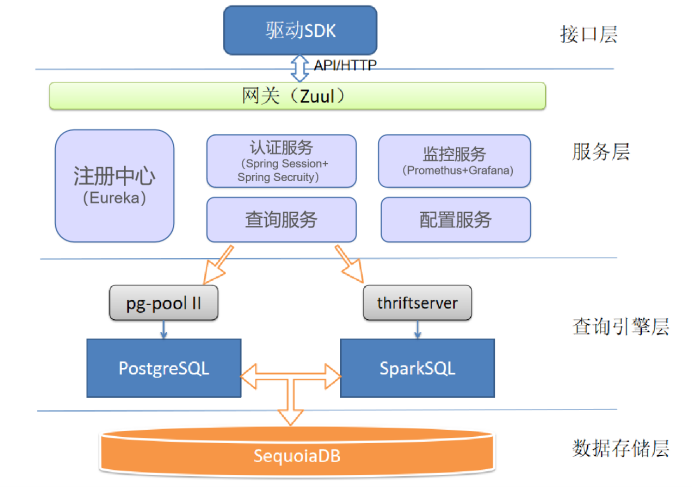
为了在不同的查询场景能够提供最优的查询效率,提供了两种查询引擎:PostgreSQL、SparkSQL,这两种引擎通过与 SequoiaDB 对接实现 SQL 的解析与计算,只存储表的元数据信息,实际数据内容存储于 SequoiaDB。
引擎适用场景:
PostgreSQL:适用于查询条件相对固定的精准类查询,单表查询或多表关联且根据关联条件筛选后结果集较小的查询。
Note:为了避免单点故障以及承受高并发下的查询要求,PG部署为集群模式,并使用pg-pool II软件管理PG集群,实现负载均衡以及故障转移功能。
SparkSQL:适用于多表关联且语句较为复杂的统计分析类查询,能够提供优于传统关系型数据库的查询效率。
Note:服务内部使用JDBC的方式来连接查询引擎,所以启用了Spark提供的thrift-server服务来使用SparkSQL。
项目成果
实时数据交换平台目前已经在超过20家银行用户上线生产。其中在一家大型股份制银行,基于巨杉数据库构建的实时数据服务平台,已经服务包括ECIF,借记卡核心,用户CRM等在内的超过30个业务系统,总部署超过50台物理服务器。
银行用户的实时数据交换平台未来还将进一步拓展为全行范围内的统一数据交换平台,为不同业务系统提供历史数据和准实时数据的大规模并发、大规模数据吞吐量的查询服务。各业务系统的数据集中存放于数据交换平台,可以提升数据关联价值,也可以起到数据归档作用。在当前实时数据处理基础上,还将持续增加包括元数据管理、数据生命周期管理在内的多种解决方案。
小结
本文主要介绍了实时数据服务平台的整体架构,以及架构中各个组成模块的作用和技术实现细节,从数据采集层,数据处理层,数据存储层、数据查询等方面进行了详细分析与说明。帮助读者对基于 SequoiaDB 搭建的实时数据服务平台有个清晰且全面的了解。
越来越多的企业倾向于实时的获取数据的价值,而不满足于通过夜间运行批量任务作业的方式来处理信息的方式了。他们认为数据的价值只有在刚刚产生时才是最大的,而且在数据刚一产生就对它进行移动、处理和使用才是最有意义的。实时数据服务平台将银行各个系统的数据实时的处理,整合得到有价值的数据保存到 SequoiaDB 巨杉数据库中供用户实时查询使用。不仅提高了用户的满意度,还将实时处理技术与实际业务应用有效地结合起来,促进实时处理技术的落地。未来将会有更多的业务场景需要该技术的支持。
一个稳定可靠且高效的实时处理架构是体现实时数据价值的基础,实时数据服务平台的搭建,能够稳定的在生产环境中运行,提供高效的服务,在技术上,具有很高的参考价值。该实时数据处理架构实现了 SequoiaDB 与其他数据库实时对接,能够方便从其他数据库中实时的迁移和备份数据。
 往期技术干货
往期技术干货巨杉Tech | SequoiaDB高可用原理详解
巨杉Tech | 分布式数据库负载管理WLM实践
巨杉Tech | 巨杉数据库的HTAP场景实践
巨杉Tech | SequoiaDB SQL实例高可用负载均衡实践
巨杉Tech | 并发性与锁机制解析与实践
巨杉Tech | 几分钟实现巨杉数据库容器化部署
巨杉Tech | “删库跑路”又出现,如何防范数据安全风险?
巨杉Tech | 分布式数据库千亿级超大表优化实践
社区分享 | SequoiaDB + JanusGraph 实践
巨杉Tech | 巨杉数据库的并发 malloc 实现
巨杉数据库无人值守智能自动化测试实践



