




Errors in file/oracle/app1/oracle/product/9.2/admin/bsssz/udump/bsssz_ora_10892.trc: ORA-00600: 内部错误代码,参数: [kksscl-inf-inl-loop],[2500], [592], [603], [1211], [1211], [], [] Tue Apr 18 13:48:25 2006 Errors in file/oracle/app1/oracle/product/9.2/admin/bsssz/udump/bsssz_ora_8253.trc: ORA-00600: 内部错误代码,参数: [kksscl-inf-inl-loop],[2500], [424], [454], [909], [909], [], [] |
通过TOP命令观察,有1-2个数据库SERVER进程十分繁忙。如果KILL繁忙的数据库进程,系统就会恢复正常。有时候,不KILL进程,系统几十秒到几分钟后系统会自动恢复正常。ORACLE的技术支持人员也到现场进行了处理。根据现场观察,认为是BUG2235386。并且已经打了2235386补丁。打补丁后,仍然出现了相同的故障,说明补丁2235386并不能彻底解决本故障。从这个ORA-600错误的主要原因是共享池闩锁争用,等待某个LIBRARY CACHE对象的闩锁产生了INTERNAL DEADLOCK。
接到客户发来的TRACE后我们又仔细分析了ALERT LOG,发现了一个有趣的现象,就是在这个ORA-600的前后都会出现一个或者几个ORA-60错误:
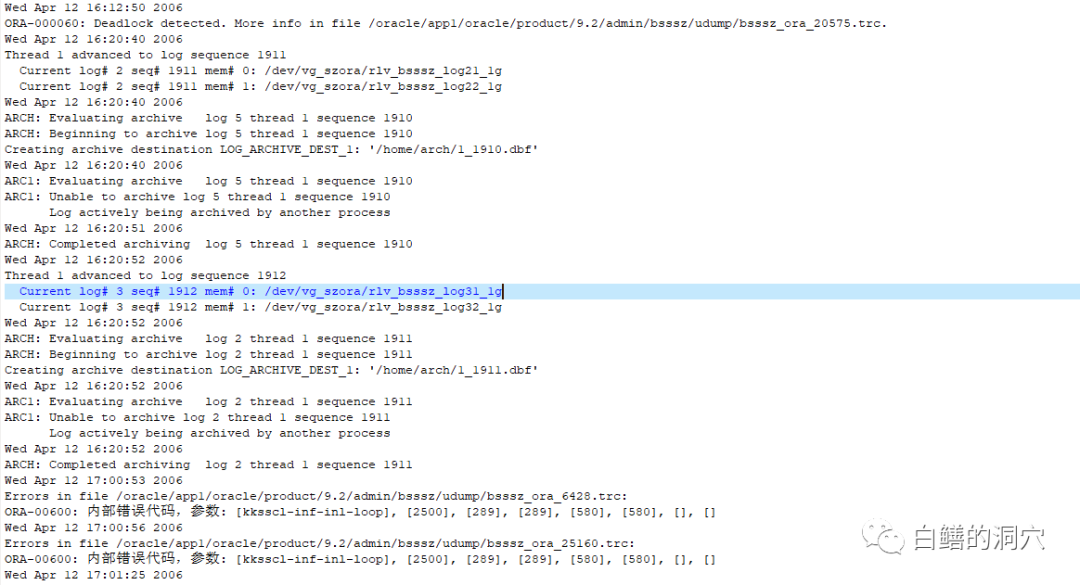

有的相隔几分钟,有的甚至相隔十多分钟,所以这个现象也没有引起大家的注意。于是我让用户观察一下下次出现类似问题时,CPU使用率很高的那个进程是不是就是产生死锁的进程。因为这个问题出现的很频繁,每隔几天就会出现一次,有时候一天都会出现几次,最短的几十秒,最长的十几分钟。于是很快用户就确认了,确实出问题的时候,伴随着死锁发生,而且那个CPU使用率较高的进程就是死锁产生的进程。
同时通过对产生ORA-600的会话进行分析,发现了以下几个特点:
1、通过对ORA-600[KKSSCL-INF-IN1-LOOP]进行分析,发现报错的SESSION正在等待某个子CURSOR分析完成。等待的CURSOR都有或多或少的子CURSOR,多的有200-300个子CURSOR,少的有5-10个子CURSOR; 2、等待子CURSOR编译完成的CURSOR的SQL语句没有任何规律 3、死锁的SESSION的SQL语句一般是UPDATE和DELETE语句。都包含或多或少的子CURSOR(几个到几百个) 4、为了了解在故障发生时系统有什么异常的操作,对5月10号发生故障的时段(20点23分-20点27分58秒)的归档日志进行了LOGMINER分析(故障发生在5月10号20点26分17秒,5月10号20点27分56秒恢复),发现26分17秒到27分56秒之间没有任何SQL语句执行,说明这个期间数据库完全HANG住(一般情况是发生了Internal Deadlock或者系统内部资源不足造成的等待某资源释放)。在23分到26分17秒之间有一个类似DDL操作的迹象,5月10日20点26分10秒,对产生了大量internal操作和对SEG$和TSQ$的操作,由于操作是Internal的,因此具体发生了什么DDL操作无法判定。因此无法确定该操作和系统 HANG住是否有直接的联系。可以确认的是,该操作和段扩展没有关系。除此之外,在整个分析时段中没有明显异常的SQL(SELECT操作除外,在LOGMINER中看不到)。在整个分析过程中insert操作十分多。 5、使用KILL -3不能停止该死锁进程的操作,不过能在日志中看到该KILL被该进程捕获,说明该进程并没有死或者僵死。并且通过该进程的TRACE开始时间和捕获到KILL-3操作的时间,可以看出,该进程写TRACE已经超过10分钟了,还没有完成。 |
l 死锁出现时,存在大量的INSERT和UPDATE操作,系统的一致性读(CR GET)十分大
l 死锁出现时,系统中都有大型的SQL存在,这种SQL的特点是都是大型的SELECT操作,存在大量的大表连接,平均每次执行要进行几千万甚至超过1亿个BUFFER GET(也就是说要扫描几个G的数据库缓冲区)。由于在SELECT操作进行的时候,系统的修改操作也十分多,因此会导致SELECT操作产生了大量的CR GET,加大DB CACHE 相关的闩锁竞争
l 死锁出现时,DB BUFFERS CHAINS闩锁竞争比较大
l 死锁的SESSION的PROCESS STATE DUMP比普通DEAD LOCK的Process State Dump大
n 通过调整应用,解决死锁问题
n 关闭TRACE文件中的PROCESS STATE DUMP
n 优化系统,降低系统总体负载,减少故障出现的机会(不能彻底解决问题)
