




优化数据库的性能是一个非常复杂的过程,你需要对数据库的物理结构和逻辑结构有很深入的了解。
导致你的系统性能下降的原因有很多,通常跟应用程序设计和程序代码、内存容量、io、资源争用、操作系统和机器的cpu有关,简而言之就是两大类,软件质量和硬件配置。
当我们主动出击,对数据库做性能优化的时候,通常先从应用编写的程序下手,因为不好的程序会导致糟糕的性能并且带来可伸缩性问题。当oracle出现性能问题,我总结了几点跟程序有关的注意点
1、错误的会话管理
2、糟糕的游标管理(绑定变量、游标共享、非集合运算)
3、不科学的关系设计
4、不科学的存储结构
将大部分精力集中在对应用程序设计和编写上,对提升系统性能有重大意义。
01
错误的会话管理
对会话管理不善,会导致伸缩性问题。我用一个简单的场景来说明问题:一个用户登陆到网页,从网页中获取想要的数据,最后注销退出,如果用户在登进与登出上花费的时间比实际获取数据的时间还多很多,那么可以说这个系统性能很不尽如人意,接下来要面临的就是对其进行优化以提升用户体验,没有人愿意在登进与登出这个环节花太多时间。
02
糟糕的游标管理
编写连接到oracle数据库的代码时,首先应该考虑的是始终使用绑定变量(bind variables),也就是要始终将参数以变量的形式写进SQL语句。
比如,
select * from chicago.info where dept_id=’INF’;
这等效于
variable deptid varchar2(10)
exec :deptid := ‘INF’
select * from chicago.info where dept_id= :deptid;
这两个语句都能得到相同的结果,但是后者对数据库性能的提升帮助很大。因为当用户查询不同的deptid时,前者被数据库当成一个崭新的语句来执行,因此需要重新发生硬解析(hard parse);而后者则不需要再次硬解析,而是直接使用第一次执行时,oracle为之提供的执行计划。
oracle在每一次接触到一条新的SQL语句时,会为之计算生成一个哈希值,并将该值与内存中已经存在的哈希值比较,如果内存中有同样的哈希值,那么直接使用该哈希值对应的执行计划,如果不存在相同的哈希值,就发生一次硬解析。(生产环境复杂多端,有时一条SQL可能之前执行过,但是因为时间太长,内存中已经没有对应的哈希值了)
所谓新的SQL语句,就是之前从来没有出现过的,对oracle来说是一条崭新的字符串。回到我们正在讨论的绑定变量,如果我们不停的将一条使用了绑定变量的SQL语句发送给oracle,那么对于oracle而言,不管变量的值怎么变化,他都不是新的SQL。
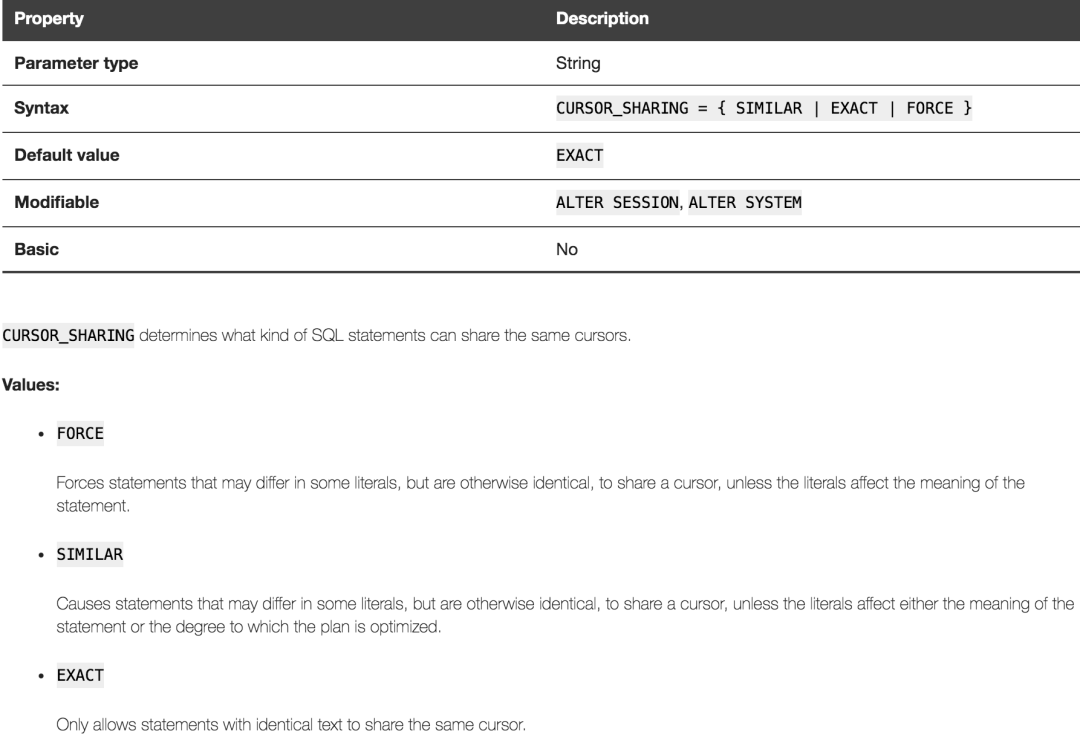
Note:
Forcing cursor sharing among similar (but not identical) statements can have unexpected results in some DSS applications, or applications that use stored outlines.
03
不科学的关系设计
数据库的关系设计不科学可能会导致大的问题,这里不讨论设计数据库系统的学术方法,因为在实际生产环境中,很难有一个规范化的关系设计。
上面提到的糟糕的关系设计是指比如过度规范化(over-normalization)带来的问题,因为这样会为了获得预期的结果而使用过多(overabundance)的表连接。
当我们试图将面向对象的模型映射到关系数据库时,过度规范化可能会成为问题。数据库的逻辑设计很重要,例如,在表中引入冗余列(redundant column)可以带来更好的性能,这样在大多数情况下,可以不必通过扫描一个大表来完成计算。
关系设计中的另一个问题是在表上使用不正确的索引。基于应用程序将采用的数据选择方法,应该在表上设置正确的索引,这是创建关系数据库模型时的设计考虑因素之一。
04
不科学的存储结构
Oracle数据库逻辑结构由表空间和模式对象决定,选错了就会导致bad performence。
在设计Oracle数据库时,我们有一组丰富的模式对象,我们必须回答诸如“哪个更好、位图索引还是反向键索引?”这样的问题。
在Oracle数据库的最新版本中,许多更改存储结构的操作可以在联机数据库中执行,性能衰减(decay)最小,并且不存在服务短缺(shortage)。

