




一、关于python的消息队列概述
关于python的队列,内置的有两种,一种是线程queue,另一种是进程queue,但是这两种queue都是只能在同一个进程下的线程间或者父进程与子进程之间进行队列通讯,并不能进行程序与程序之间的信息交换,这时候我们就需要一个中间件,来实现程序之间的通讯。
RabbitMQ并不是python内置的模块,而是一个需要你额外安装模块pika,安装完毕后可通过python中内置的pika模块来调用MQ发送或接收队列请求。
二、RabbitMQ的安装部署
关于安装部署当然docker更好使啦!所以我安装部署使用了docker。
- 查看RabbitMQ相关的镜像
docker search rabbitmq:management
- 拉取镜像
docker pull rabbitmq:management
- 启动容器
docker run -d -p 5672:5672 -p 15672:15672 --name rabbitmq rabbitmq:management
注意:这里两个-p,分别代表 -p 程序访问队列的端口号:容器端口号 -p 网页界面端口号:容器端口号
5672是程序访问时的端口号,15672是网页界面的端口号,不要搞混了
OK, 这么简单RabbitMQ就安装部署完了!
三、RabbitMQ网页界面的简单使用
安装部署完之后,访问 http://localhost:15672 这个网址就可以进入网页界面,默认用户名密码都是guest,点击登录即可。
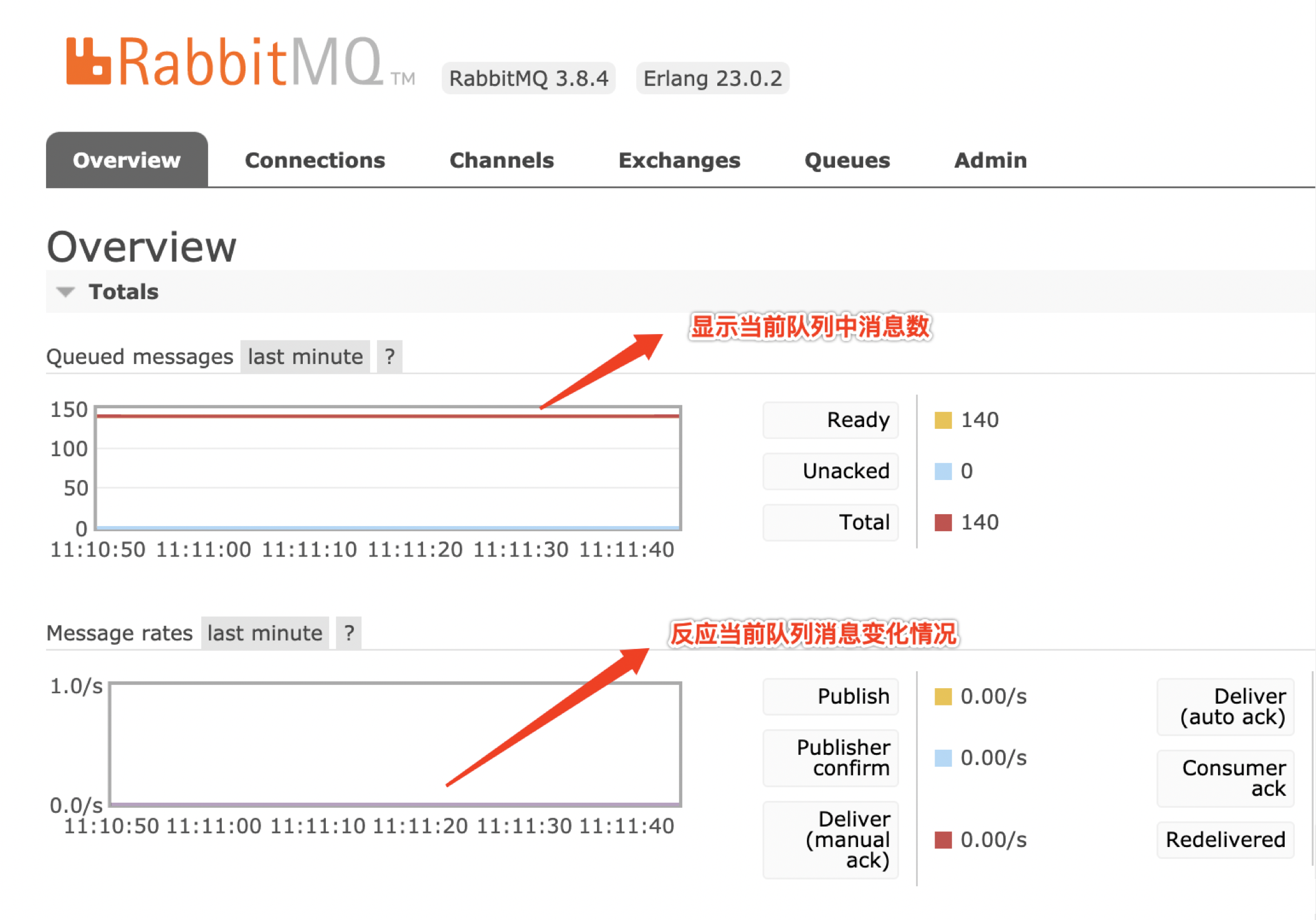
- 如何查看队列中消息信息?
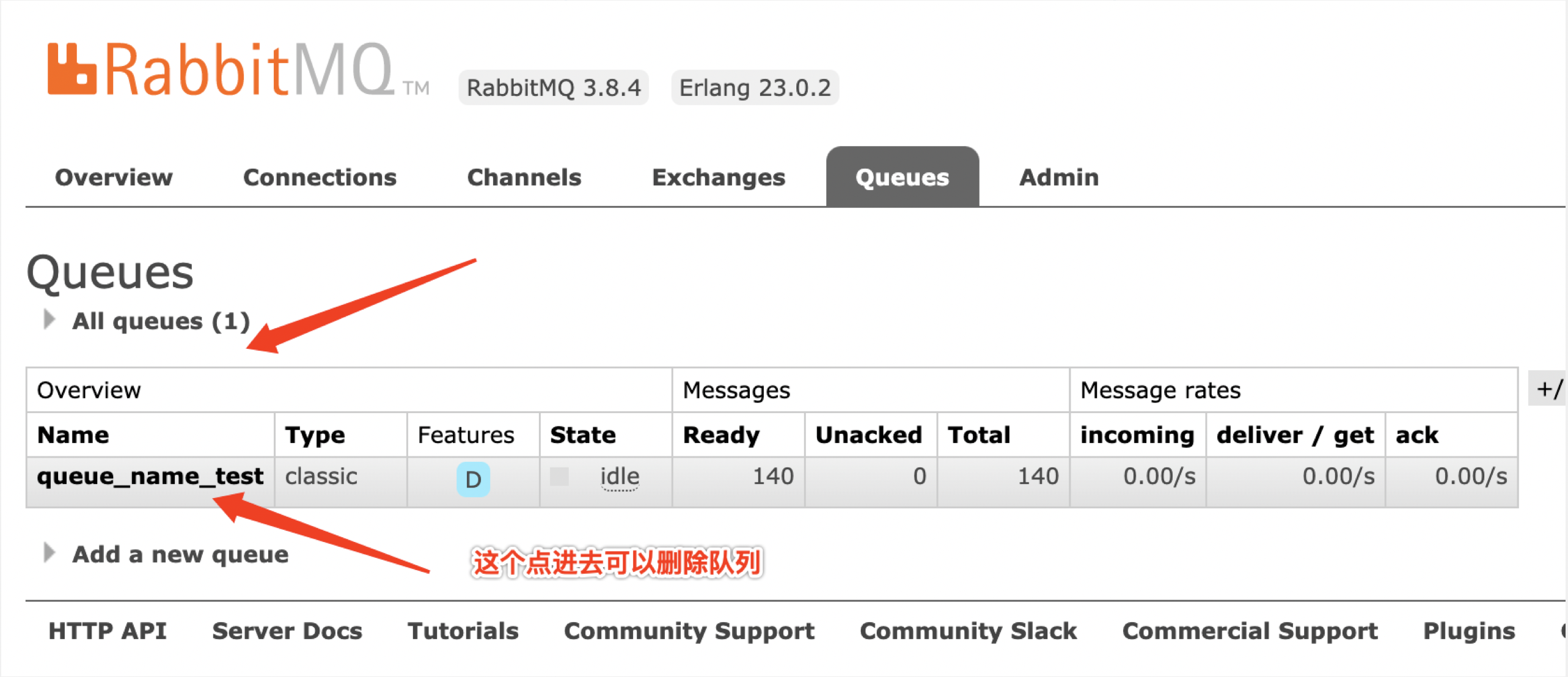
- 如何查看和删除队列?
四、Python对RabbitMQ的基本操作
python对RabbitMQ的操作,主要使用python的pika库
- pika库的安装
pip install pika
- pika库导入
import pika
- 连接RabbitMQ
# 连接RabbitMQ
def connection_mq():
credentials = pika.PlainCredentials(
username = 'guest', # 用户名
password = 'guest', # 用户密码
)
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host='127.0.0.1', # MQ地址(本机)
port=5672, # 端口号,注意是5672,不是15672
virtual_host='/', # 虚拟主机
credentials=credentials, # 用户名/密码
)
)
channel = connection.channel()
return connection, channel
- 生产者
# 生产者
def producer(info):
connection, channel = connection_mq()
channel.queue_declare(
queue='queue_name_test', # 队列名
durable=True, # 使队列持久化
)
channel.basic_publish(
exchange='',
routing_key='queue_name_test', # 告诉rabbitmq将消息发送到 queue_name_test 队列中
body=info, # 发送消息的内容
properties=pika.BasicProperties(delivery_mode=2, ) # 消息持久化
)
connection.close()
- 消费者
# 回调函数
def callback(ch, method, properties, body):
"""在这里可以写对取出数据的处理"""
print(body)
ch.basic_ack(delivery_tag=method.delivery_tag)
# 消费者(方式一:不停循环取消息和调用回调函数)
def consume():
_, channel = connection_mq()
channel.queue_declare(
queue='queue_name_test', # 消费对列名
durable=True, # 持久化
)
channel.basic_consume(
queue='queue_name_test', # 消费队列名
auto_ack=False, # 手动回应
on_message_callback=callback, # 回调消息
)
channel.start_consuming()
对于”auto_ack=False“的解释:
在消息发出后,Consumer接收到了生产者所发出的消息,但在Consumer突然出错崩溃,或者异常退出了,但是生产者消息已经发出来了,那么这个消息可能就会丢失,为了解决这样的问题,RabbitMQ引入了ack机制。
当autoAck等于false时,RabbitMQ会等待消费者显式地回复确认信号后才从内存(或者磁盘)中移去消息(实质上是先打上删除标记,之后再删除)。
当autoAck等于true时,RabbitMQ会⾃自动把发送出去的消息置为确认, 然后从内存(或者磁盘)中删除,而不管消费者是否真正地消费到了这些消息。
把这个参数设置为False之后,即使在消费的过程多次断开重连,也不会造成数据的丢失。
对于”channel.start_consuming() “的解释:
当auto_ack设置为False之后,channel.start_consuming()运行之后,消费者就会不停循环取消息和调用回调函数
当队列为空的时候,消费者也不会停止,会等待生产者生产数据,当消息队列中有消息会被立即消费。
五、使用过程中一些需求解决
- 需求1:获取消息队列中当前消息数
# 判断队列中消息数
def check_num():
_, channel = connection_mq()
queue = channel.queue_declare(
queue='queue_name_test', # 要判断的队列名
durable=True,
exclusive=False,
auto_delete=False
)
num = queue.method.message_count
return num
还有两种方式获取,但是不推荐使用,不太准确
1、方式一:使用pyrabbit
from pyrabbit.api import Client
cl = Client('localhost:55672', 'guest', 'guest')
cl.get_messages('example_vhost', 'example_queue')[0]['message_count']
2、方式二:使用requests
import requests
import json
url = 'http://{}:{}/api/queues/%2F/{}'.format(self.mq_host, self.mq_url_port, self.queue_name)
num = int(json.loads(requests.get(url, auth=(self.mq_name, self.mq_password)).content.decode())["messages"])
- 需求2:指定消费者提取5000条消息就停止
def consume():
_, channel = connection_mq()
channel.queue_declare(
queue='queue_name_test', # 消费对列名
durable=True, # 持久化
)
for method_frame, properties, body in channel.consume('queue_name_test'):
print(body)
channel.basic_ack(method_frame.delivery_tag)
if method_frame.delivery_tag == 5000:
break
OK,基本操作到此结束,更多更深的知识等待你我去探索…
