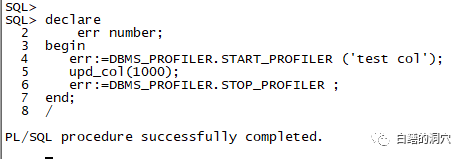
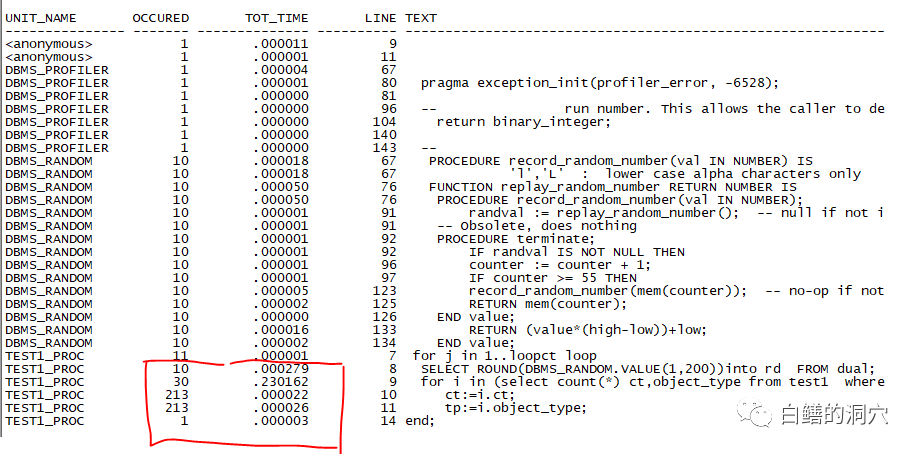
declare err number; begin err:=DBMS_PROFILER.START_PROFILER ('testprofiler'); --启动 profiler测试 test1_proc(10); err:=DBMS_PROFILER.STOP_PROFILER ; end; / |

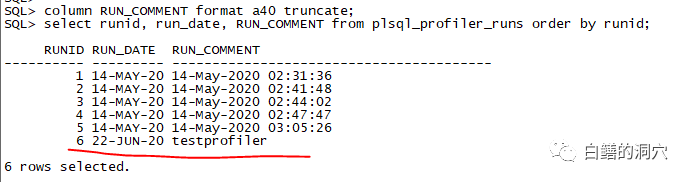
column RUN_COMMENT format a40 truncate; select runid, run_date, RUN_COMMENT from plsql_profiler_runs order by runid; |
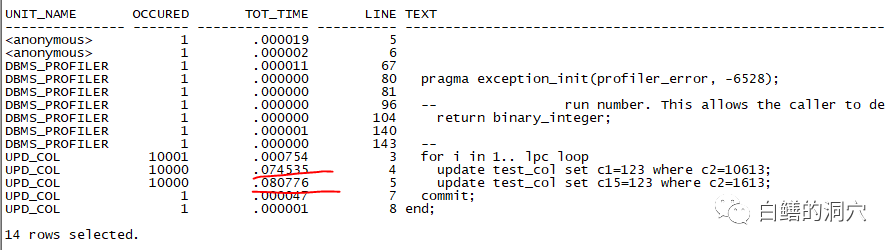
set line 132 column RUN_COMMENT format a40 truncate; select runid, run_date, RUN_COMMENT from plsql_profiler_runs order by runid; column unit_name format a15 truncate; column occured format 999999 ; column line# format 99999 ; column tot_time format 999999.999999 ; col text format a60 truncate; select p.unit_name, p.occured, p.tot_time, p.line# line, substr(s.text, 1,75) text from (select u.unit_name, d.TOTAL_OCCUR occured, (d.TOTAL_TIME/1000000000) tot_time, d.line# from plsql_profiler_units u, plsql_profiler_data d where d.RUNID=u.runid and d.UNIT_NUMBER = u.unit_number and d.TOTAL_OCCUR >0 and u.runid= &RUN_ID) p, user_source s where p.unit_name = s.name(+) and p.line# = s.line (+) order by p.unit_name, p.line#; |
create table test_col as select object_id c1, object_id c2, object_id c3, object_id c4, object_id c5, object_id c6, object_id c7, object_id c8, object_id c9, object_id c10, object_id c11, object_id c12, object_id c13, object_id c14, object_id c15 from dba_objects ; create index idx_col2 on test_col(c2); |
create or replace procedure upd_col(lpc integer) is begin for i in 1.. lpc loop update test_col set c1=123 where c2=10613; update test_col set c15=123 where c2=1-613; end loop; commit; end; / |
|