




随着AI技术从研究实验室的好奇心发展到人们的日常生活,确保AI系统产生适当和公正的结果已成为一个重要的科学问题。这需要在构建AI系统的所有阶段中对数据,算法和设计选择进行多次迭代研究。为此,ImageNet作为一个有影响力的研究数据集,应进行严格审查。下面我们总结了我们的研究团队在该主题上的最新成果。
ImageNet是一个图像数据库,共有1400万张图像和22,000种视觉类别。由于它已公开用于研究和教育用途,因此已广泛用于对象识别算法的研究,并且在深度学习革命中发挥了重要作用。
随着计算机视觉技术在人们的Internet体验和日常生活中得到广泛应用,计算机视觉模型产生合适且公平的结果变得越来越重要,尤其是在涉及人的领域中。但是,仍然存在着臭名昭著的问题。例如,已经证明面部识别系统在各个种族群体中的错误率不成比例,部分原因是面部识别数据集中某些肤色的代表性不足。
ImageNet已大多用于对所述子集中研究对象识别算法1000级的类别选择用于ImageNet挑战[2] ,只有3人类别(scuba diver,bridegroom,和baseball player)。但是,完整的ImageNet在person子树下包含2,832个人员类别,可用于训练人员分类器。这种使用可能会出现问题,并引起有关公平性和代表性的重要问题。在这篇文章中,我们描述了过去一年中我们为识别和纠正此类问题所做的研究工作。
ImageNet的构建
ImageNet于2009年通过互联网搜索和众包构建。研究小组从WordNet获得了类别词汇,WordNet是一个英语数据库,该数据库将每个类别表示为一个由同义词组成的同义词集(或“同义词集”),例如dogsled, dog sled, dog sleigh。WordNet于1985年开始由普林斯顿大学的心理学家和语言学家手动构建,并已广泛用于自然语言处理的研究中。
对于每个同义词集,ImageNet团队在2009年通过查询搜索引擎自动下载图像。当时,搜索引擎没有准确的算法来理解图像的内容,因此他们主要根据标题或标签来检索图像。这导致每个类别有许多不相关的图像。
为了删除不相关的图像,他们在Amazon Mechanical Turk(MTurk)上雇用了工人来验证每个图像是否正确描绘了同义词集。由于注释工作的规模巨大(超过5万名工人和超过1.6亿张候选图像),因此开发了一种自动化系统,可以从搜索引擎下载图像并将图像分配给MTurk工人。
识别和纠正公平与代表性问题
在过去的一年中,我们一直在进行一项研究项目,以系统地识别和纠正person由ImageNet子树中的数据收集过程导致的公平问题。到目前为止,我们已经确定了三个问题,并提出了相应的建设性解决方案,包括删除令人反感的用语,确定非视觉类别以及提供重新平衡personImageNet子树中图像分布的工具。
在进行研究时,自2019年1月以来,我们已禁用ImageNet完整数据的下载,但ImageNet Challenge中使用了1000个类别的一小部分。我们正在实施我们建议的补救措施。
下面我们总结了我们的发现和补救措施,并在即将于2019年8月提交供同行评审的即将发布的技术报告中提供了更多详细信息。
概念词汇。第一个问题是WordNet包含不适合用作图像标签的令人讨厌的同义词集。尽管在2009年ImageNet的构建过程中,研究团队删除了在其光泽度中明确表示为“令人反感”,“贬义”,“贬义”或“污秽”的任何同义词集,但这种过滤效果并不理想,仍然导致包含许多令人反感或包含令人反感的同义词的同义词集。为了解决这个问题,我们使用了一组内部注释器,在攻击性方面对同义词集进行了手动注释。每个同义词集被分类为“令人反感”(无论上下文如何令人反感),“敏感”(取决于上下文而令人反感)或“安全”。“令人反感”的同义词集本质上是令人反感的,例如亵渎,与种族或性别侮辱相对应的,racist)。“敏感”同义词集并非天生具有冒犯性,但如果不适当地应用,例如基于性取向和宗教的人的分类,则可能会引起冒犯。
到目前为止,在person子树中的2,832个同义集中,我们已经识别出1,593个不安全的同义集(包括“令人反感”和“敏感”)。其余1,239个同义词集暂时被认为是“安全的”。可以在此处找到不安全的同义词集ID 。我们避免明确列出与每个概念相关的令人反感的概念;有关转换,请参阅https://wordnet.princeton.edu/documentation/wndb5wn。我们正在通过删除所有被标识为不安全的同义词集及其关联图像来准备ImageNet的新版本。这将导致删除600,040张图像,而将577,244张图像保留在其余的“安全”人员同义词集中。
重要的是要注意,“安全”同义词集仅表示标签本身不具有冒犯性。这并不意味着从视觉线索推断出这样的标签是可能的,有用的或符合道德的。尽管在某些情况下可以合理地使用这种视觉标记,例如识别游泳者以进行安全监控,但对于每种应用,都必须仔细考虑对人员进行分类的道德原则。
随着术语发展新的文化背景,进攻性是主观的,并且也在不断发展。因此,我们向社区提出了这个问题。我们正在更新我们的网站,以允许用户将其他同义词集报告为不安全。
不可成像的概念。第二个关注点是与生俱来的冒犯性概念,但是可能不适合包含在图像数据集中。ImageNet尝试用一组图像描述WordNet中的每个同义词集。但是,并非所有同义词集都可以在视觉上表征。例如,如何philanthropist从图像中得知一个人是否是一个?通过仅在注释者之间达成高度共识的情况下才允许图像,ImageNet的自动注释管道中的部分问题已得到部分解决[1]。但是这种保护措施并不完善,而且我们发现personImageNet子树中的大量同义词集不可成像-难以使用图像进行准确表征。
ImageNet中不可成像的同义词集是潜在的偏差来源。当一个不可成像的同义词集(错误地)用一组图像表示时,我们可能最终会对基本概念有偏见的视觉描述。例如,来自同义词集的图像Bahamian (a native or inhabitant of the Bahamas)主要包含穿着独特的巴哈马传统服饰的人。但是,巴哈马人只有在特殊情况下才穿这种服装。这种有偏见的描述是两个图像搜索引擎返回同构集的视觉上最独特的图像以及人类注释者仅对最独特的图像达成共识的结果。然后,这导致了同义集的偏差表示,这对于固有地不可成像的同义集特别明显。为了减少这种类型的视觉偏差,我们首先确定person子树中的同义词集的可成像性,然后删除具有低可成像性的那些。
我们使用MTurk的工作人员在可成像性方面对人员同义词集进行了注释。我们遵循了心理学语言学之前的工作,这些工作将可成像性定义为“单词引起图像的容易程度” [6-8]。我们要求多个工作人员以1-5的等级对形成每个同义词集的心理图像的难易程度进行评分,从非常困难(1)到非常容易(5)。
我们注释了暂时被标记为安全或敏感的同义词集的2394个人同义词集的可成像性。结果显示,中位数为2.36,并且只有219个同义词集的可成像性大于4。可在此处找到完整的可成像性列表。
图像的多样性。我们确定的第三个问题是ImageNet图像之间的代表性不足。ImageNet由通过查询图像搜索引擎[1]收集的Internet图像组成,这些图像已被证明可以检索种族和性别方面的偏见[4-5]。以性别为例,Kay 等。发现当使用职业(例如银行家)作为关键字时,与真实的真实比率相比,图像搜索结果显示出夸大的性别比率。另外,在手动清理阶段也可能引入偏见,因为当给定的示例与刻板印象一致时,人们倾向于给出积极的回应[4]。
ImageNet采取了使图像多样化的措施,例如关键字扩展,多种语言搜索以及组合多个搜索引擎。滤除不可成像的同义词集也可以缓解该问题:有了更强的视觉证据,工人可能不太容易定型。尽管做出了这些努力,但是受保护属性中的偏见仍然存在于person子树中的许多同义词集中。有必要研究这种偏见如何影响为下游视觉任务训练的模型,而如果没有高质量的图像级人口统计学注释,这是不可能的。
为了评估ImageNet中的人口统计数据并提出更具代表性的图像子集,我们在person子树中的图像上标注了一组受保护的属性。我们认为,美国的反歧视法律将种族,肤色,国籍,宗教,性别,性别,性取向,残疾,年龄,军事历史和家庭状况命名为受保护的属性[9-11]。其中,唯一可能成像的属性是颜色,性别和年龄,因此我们开始对其进行注释。
我们会按照既定的规程标注肤色,性别和年龄(有关详细信息,请参见我们即将发布的技术报告)。我们在139个同义词集上标注了人口统计信息,认为它们既安全又可成像,并且包含至少100张图像。我们注释了来自每个同义词集的100个随机采样的图像,总计达13,900张图像。下图显示了不同同义词集的类别分布,反映了真实的偏见。
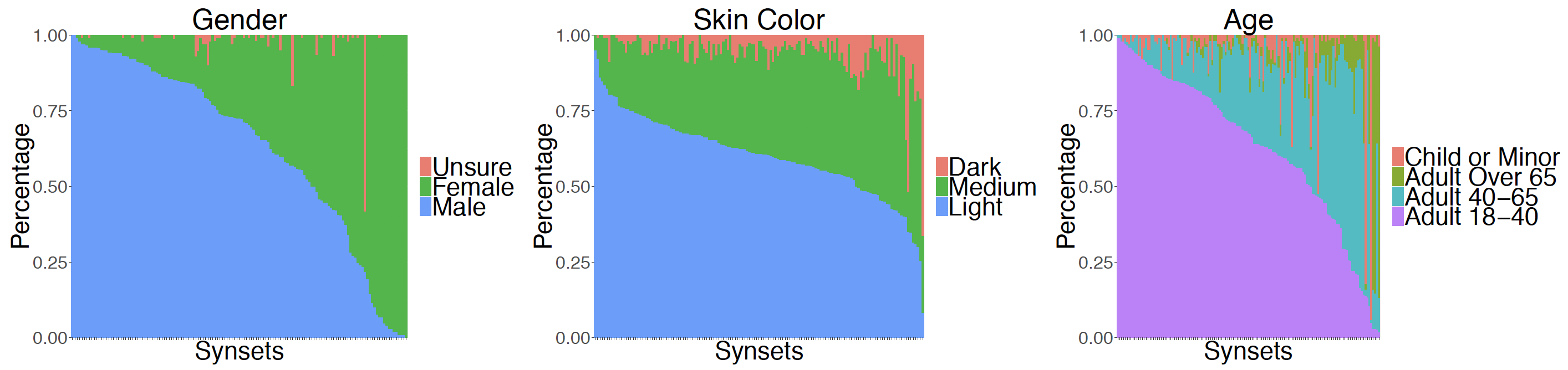
图1:139个安全且可成像的同义词集中的人口统计类别分布,其中至少包含100张图像。不同颜色区域的大小表明某些组的代表性不足。
给定人口统计分析,希望有一个建设性的解决方案来改善ImageNet图像的多样性。为此,我们正在构建一个Web界面,该界面将自动重新平衡每个同义集内的图像分布,以期通过移除对应于该属性的图像来实现单个属性的目标分布(例如,性别的均匀平衡)。代表过多的类别(图2)。这种平衡仅在每个属性类别中具有足够表示的同义词集上才可行。例如,同义词集baby自然不包含均衡的年龄分布。因此,我们将允许用户请求平衡属性类别的子集;例如,用户可以对三个成人类别(“ 65岁以上成人”,“ 40-65岁成人”和“ 18-40岁成人”)施加相同的表示,同时消除“儿童”类别。我们未来的工作包括收集其余注释,并公开发布Web界面。


图2:programmer在平衡为均匀分布之前和之后,ImageNet同义词集中的图像分布。
担心的是,用户可能能够使用此界面来推断已删除图像的人口统计。例如,有可能在视觉上分析一个同义词集,请注意,该同义词集内的大多数人似乎是女性,因此可以推断出在性别平衡过程中删除的任何图像都被注释为女性。为了减轻这种担忧,我们总是只将90%的少数族裔图像包含在平衡图像中,而将其余10%丢弃。此外,仅当请求至少2个属性类别(例如,用户不能请求仅女性性别分布)并且每个请求的类别中至少有10张图像时,我们才返回图像的平衡分布。
请注意,我们已经考虑了替代方案,例如发布单独的注释,或为代表性不足的属性收集其他数据,每种属性各有优缺点。我们即将发布的技术报告中有详细的讨论。
进一步讨论
在person子树之外还有许多工作要做,因为偶然的人也出现在说明其他ImageNet同义词集的照片中,例如在宠物,家用物品或运动的同义词集中。在其他子树中,问题的密度和范围很可能(或至少希望如此)比在此子树中小,因此过滤过程应该更简单,更有效。
最后,我们的努力仍在进行中。我们的研究报告正在等待同行评审,我们将在短期内分享。我们欢迎研究界及其他组织就如何构建更好和更公平的数据集来训练和评估AI系统提供意见和建议。
作者:杨开宇(普林斯顿大学),克林特·奇南(普林斯顿大学),李飞飞(斯坦福大学),贾登(普林斯顿大学),奥尔加·鲁萨科夫斯基(普林斯顿大学)
文章来源:http://image-net.org/update-sep-17-2019
