




DIAG_ADR_ENABLED=off TRACE_LEVEL_CLIENT = 16 TRACE_FILE_CLIENT = <FILE NAME> TRACE_DIRECTORY_CLIENT = <DIRECTORY> TRACE_TIMESTAMP_CLIENT = ON |
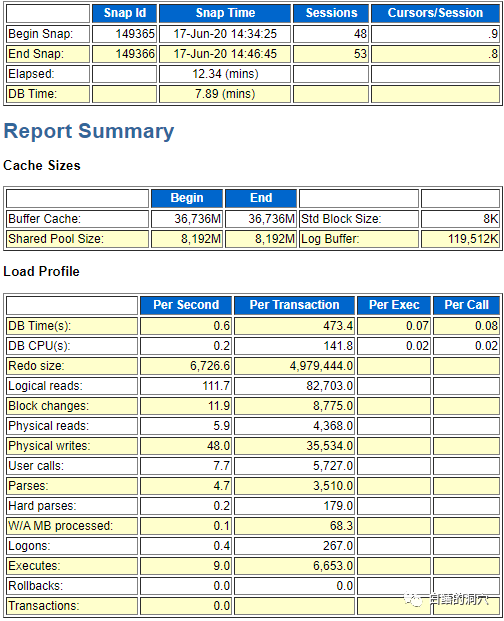
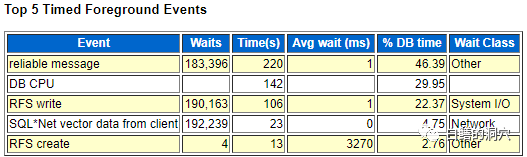
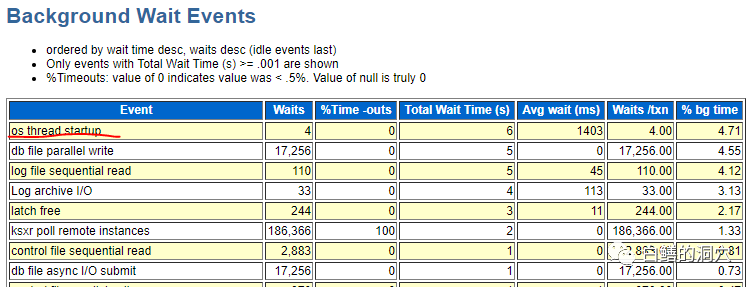
AIX环境下,等待进程启动时间是4秒
同样位置,LINUX下只有1秒。 |


| truss -aDefo tmp/a.log sqlplus "/as sysdba" |


文章转载自白鳝的洞穴,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
