




NOLOCK的作用有的时候还是很强大的。通常我们的理解是NOLOCK不需要申请S锁,从而避免因他人做数据修改引起的阻塞,也就是说NOLOCK理应返回更多的数据才对(比如新插入的行还没提交,也顺手牵羊一起返回了)。然而,在某种情况下,NOLOCK反而返回了更少的数据,并且可以确认的是,当前没有人在删数据,那么到底是为什么呢?
重现步骤
脚本1:
======use test;godrop table tcnt;create table tcnt(num int, cnt int);drop table t1;create table t1(a int primary key, b char(500));declare @i int, @tcnt1 int, @tcnt2 int;set @i=1;set @tcnt1=0;set @tcnt2=0;insert into tcnt values (0,0);while (@tcnt2<10000)beginselect @tcnt2=count(*) from t1 with (NOLOCK);if (@tcnt2<>@tcnt1)begininsert into tcnt values (@i,@tcnt2);set @i=@i+1;set @tcnt1=@tcnt2;end;end;
脚本2:
======use test;godeclare @imin int, @imax int;set @imin=1;set @imax=10000;while (@imax>@imin)begininsert into t1 values (@imin,'x');insert into t1 values (@imax,'y');set @imin=@imin+1;set @imax=@imax-1;end;
将脚本1和脚本2在两个不同的session中执行,脚本1起到一个
select count(*) from t1 WITH (nolock)
的行数统计,而在t1中每添加几行(只要比上一轮行数多了,就统计),就做一次行数统计。脚本2开始往t1中疯狂插入10000行数据。结果根据tcnt表的行数统计情况来看,我们发现后面的行数有的时候会比前面的行数少。可以通过以下语句来确认:
select * from tcnt t1, tcnt t2 where t1.num<t2.num and t1.cnt>t2.cnt;
会得到以下结果
==============num cnt num cnt----------- ----------- ----------- ----622 1189 624 1187623 1191 624 1187687 1310 690 1309688 1312 690 1309689 1313 690 1309
也就是第623次统计的时候,发现有1191行,在624次统计的时候,发现却只有1187行!可是我只插入过数据,没删除过数据呀,数据哪去了呢?
解析
====
如果看明白脚本2的定义的话,应该可以猜到他的插入顺序是有特点的。他是从两端向中间插入的,也就是说,可能发生Page Split!
如果发生了Page Split,那么select count(*)的clustered index scan读到这个页面的时候,只发现了一半的数据,那么另一半的数据被split到哪里去了?为什么漏掉了呢?
Scan的顺序才是问题的关键。事实上,故事从这里才算开始:首先我们介绍两种scan的方式,allocation scan和range scan
脚本3
=========use mastergoDROP DATABASE allocationordertest;CREATE DATABASE allocationordertest;USE allocationordertest;GO-- Create a simple table that we can fill up quickly, plus a clustered indexCREATE TABLE t1(c1 INT, c2 VARCHAR (8000));CREATE CLUSTERED INDEX t1c1 ON t1(c1);GO-- Add some rows, making sure to produce an out-of-order dataset when scanned in allocation order.DECLARE @a INT;SELECT @a = 10;WHILE (@a < 100)BEGININSERT INTO t1 VALUES (@a, replicate('a', 5000))SELECT @a = @a + 1END;SELECT @a = 1;WHILE (@a < 10)BEGININSERT INTO t1 VALUES (@a, replicate('a', 5000))SELECT @a = @a + 1END;
根据脚本3,你很容易发现,他的先插入了10-100的数据,然后再插入1-10的数据,然后执行以下两个指令,你会发现结果的顺序是不同的。
SELECT * FROM t1;SELECT * FROM t1 WITH (NOLOCK);
不带NOLOCK的返回的是1-100的正确顺序,而带NOLOCK的返回的是10-100,1-10这个“插入顺序”(实际上是以PAGE ID的顺序输出)。
我们并未指定ORDER BY,所以SQL Server返回的结果是否排序当然是不保证的。但是上述的情况并不是巧合,不管怎么测试你都会发现是相同的结果。因为不带NOLOCK的话,是通过range scan,也就是通过聚集索引叶子节点的链表来做横向扫描的。而加了NOLOCK,SQL Server会选择使用allocation scan,通过检索IAM页对数据页的物理先后(pageid)来进行扫描。(如果你多次执行脚本3,你可能发现他不是严格按照10-100,1-10这样的插入顺序的;而是一个看起来更混乱的顺序。然而,你仔细观察会发现,他是以PAGE ID的先后顺序输出的。)如果使用TABLOCK,或者是
read uncommitted的隔离级别的话,也会使用这种扫描。原因是由于对于NOLOCK的情况,SQL Server是不需要关注当前的数据是否被锁,所以以最简单的方式扫描数据,防止横向遍历链表的指针开销。而对于TABLOCK,他可以保证当前不会有其他人访问该表,所以当然也可以放心的选择最快方式扫描数据了。
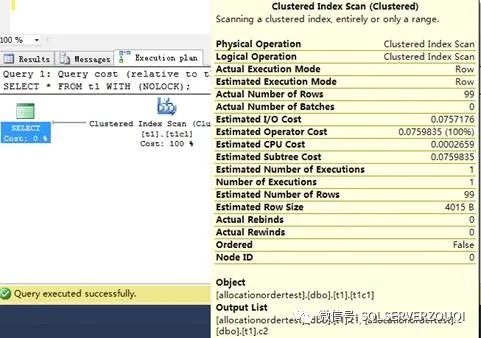
比较上述两种scan方式的执行计划,然而,却没有任何差别,一模一样。并且,两种scan的ordered选项都是false。
问题原因
========
这样一来,之前的问题就好解释了,当问题发生时,某个page(比如page id 50)发生了page split,而分出来的那一半数据放在了一个比较小的page id上,比如page id 15。而此时
SELECT * FROM T1 WITH(NOLOCK)
可能已经扫描到了page id 45,由于继续按照物理顺序扫描,那么存放在page id 15的那一半数据就永远地漏掉了。
附加问题:那么如果当前WITH (NOLOCK)的allocation scan还是扫描到page id 45,并且之前扫描了page id 20,但是这时候有人插入数据,是的page id 20发生了page spilt,而split到了page id 55,那么会发生什么情况呢?
答:原来存放在page id 20的数据其中有一半会被扫描两次!这样一定会返回duplicate数据!
解决办法
=========
1.首先,这个问题是否是一个bug呢?从NOLOCK的概念来说,这不应该是bug。因为NOLOCK的官方定义就是说“允许数据错误的脏读”,这种脏读不仅是说可能读到的数据会是错的,读到更少或者更多的数据其实都算脏读。当检查MSDN的时候,我发现了如下定义:
READUNCOMMITTED
指定允许脏读。不发布共享锁来阻止其他事务修改当前事务读取的数据,其他事务设置的排他锁不会阻碍当前事务读取锁定数据。允许脏读可能产生较多的并发操作,但其代价是读取以后会被其他事务回滚的数据修改。这可能会使您的事务出错,向用户显示从未提交过的数据,或者导致用户两次看到记录(或根本看不到记录)。
http://msdn.microsoft.com/en-us/library/ms187373.aspx
上面高亮的部分其实就是在说我们的这种情况,这是允许脏读所带来的已知后果。
2. 当然,最简单的办法就是把NOLOCK去掉,并且不使用read uncommitted的隔离级别,这个问题自然就不发生了。
3.然而,有些客户希望找到一个折中的办法,既想使用NOLOCK锁带来的好处,又想避免这种数据丢失或二次扫描,怎么办呢?其实这里的问题关键就是,如何把NOLOCK的allocation scan转化成range scan?
办法1:使用snapshot或read committed snapshot快照隔离级别,同时删除NOLOCK的使用。这种乐观的隔离级别起到了和NOLOCK一样的效果,可以读到前镜像数据,又不会发生本文中的问题(因为不再使用NOLOCK)
办法2:使用ORDER BY
SELECT * FROM t1 WITH (NOLOCK) order by c1;
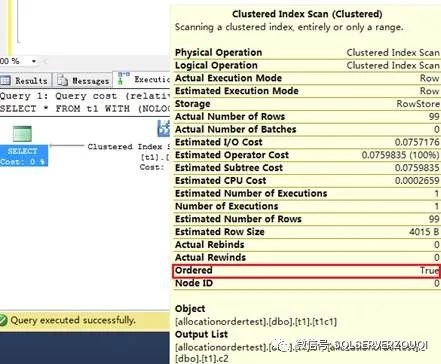
这样的效果是,还是执行相同的执行计划,但是这一次执行的一定是ordered scan,而ordered scan一定是range scan而非allocation scan,原因是聚集索引的叶子节点本来就是有序的。在执行计划中,我们会发现order=true
办法3:SELECT COUNT(*)不能使用order by,所以很难实现这种折中。如果实在需要使用NOLOCK,可以考虑两次执行SELECT COUNT(*)
文章转载自:
https://docs.microsoft.com/en-us/archive/blogs/apgcdsd/nolock
图片来源于网络,侵权必删!
