




最近,我们有一些客户希望在PostgreSQL中存储时间序列。这个领域的人们感兴趣的一个问题是计算时间序列数据中值之间的差异。如何计算当前行和前一行之间的差异?
为了回答这个问题,我决定分享一些简单的问题,概述可以做些什么。请注意,这不是一个关于分析和窗口函数的完整教程,只是对一般情况下可以做什么的简短介绍。
加载样本数据
让我们加载一些样本数据:
<font style="text-align: inherit;">cypex=# CREATE TABLE t_oil(地区文本、国家文本、年份int、生产int、消费int);cypex = # COPY t _ oil FROM PROGRAM ' curl https://www.cybertec-postgresql.com/secret/oil_ext.txt';副本644</font>
如果你是超级用户,你可以直接使用复制…从程序。否则,您必须以不同的方式加载文本文件。
滞后:如何在SQL中访问不同的行
如果要计算两行之间的差异,可以使用“滞后”函数。然而,这里自然会出现一个问题:如果我们想访问前一行。前一排是什么?我们需要某种订单。为此,SQL提供了OVER子句:
<font style="text-align: inherit;">cypex=# SELECT country,year,production,lag(production,1)OVER(ORDER BY year)FROM t _ oil WHERE country = ' USA ' LIMIT 10;国家/地区|年份|产量|滞后- + - + - + -美国| 1965 | 9014 |美国| 1966 | 9579 | 9014美国| 1967 | 10219 | 9579美国| 1968 | 10600 | 10219美国| 1969 | 10828 | 10600美国| 1970 | 11297 | 10828美国| 1971 | 1156 | 11156</font>
在我的示例中,我按年份对数据进行了排序,以确保前一年确实可以在前一行中找到。一旦我们找到了正确的行,剩下的很简单:
<font style="text-align: inherit;">cypex=# SELECT country,year,production - lag(production,1)OVER(ORDER BY year)AS different _ oil WHERE country = ' USA ' LIMIT 10;国家/地区|年份|差异- + - + -美国| 1965 |美国| 1966 | 565美国| 1967 | 640美国| 1968 | 381美国| 1969 | 228美国| 1970 | 469美国| 1971 | -141美国| 1972 | 29美国| 1973 | -239美国| 1974 | -485(10行)</font>
这里需要注意的是,第一行包含一个空条目,因为与前一行没有已知的区别。
许多人需要的是数据集当前行和第一行之间的差异。PostgreSQL(或者更准确地说是ANSI SQL)提供了“first_value”函数,该函数根据我们提供的顺序返回第一行。它是这样工作的:
<font style="text-align: inherit;">cypex=# SELECT t_oil.country,t_oil.year,t_oil.production,t _ oil . production-first _ value(t _ oil . production)OVER(ORDER BY t _ oil . year)AS diff _ first FROM t _ oil WHERE t _ oil . country = ' USA '::text LIMIT 10;国家/地区|年份|生产| diff _ first-+-+-+-USA | 1965 | 9014 | 0 USA | 1966 | 9579 | 565 USA | 1967 | 10219 | 1205 USA | 1968 | 10600 | 1586 USA | 1969 | 10828 | 1814 USA | 1970 | 11297 | 2283 USA | 1971 | 1156 | 226</font>
如您所见,在这种情况下,所有内容都是相对于第一行的。为了可视化结果,我快速构建了一个小型CYPEX仪表板:
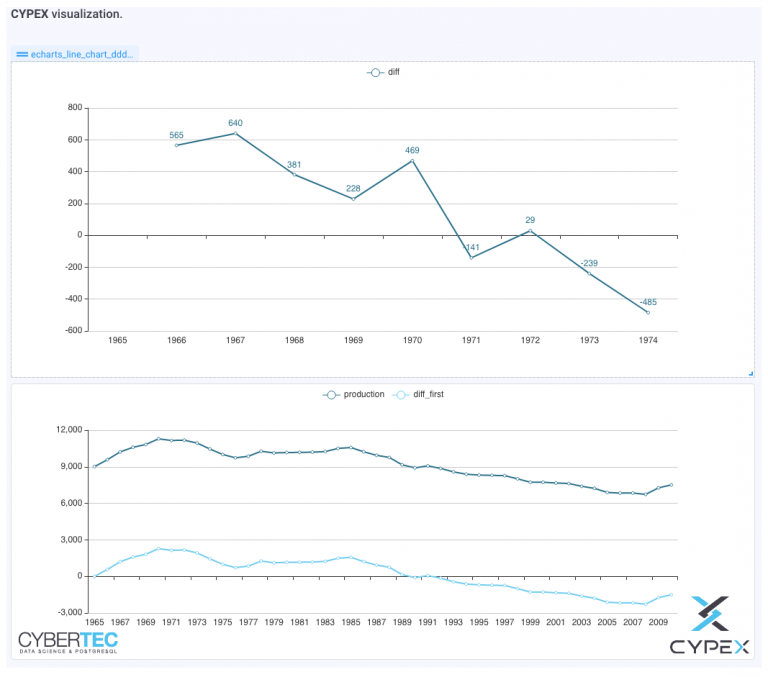
数据看起来是正确的,所以我们可以继续下一个例子。
在分析中混合数据集
但是如果我们开始关注两个国家会发生什么呢?如果我们按年订货,我们可能会走错一行。如果我们同时按两列排序,我们可能仍然会遇到与不同国家相关联的行。解决方案是PARTITION BY子句。PostgreSQL将把数据分成不同的组,并再次计算(每组的)差异。它是这样工作的:
<font style="text-align: inherit;">cypex=# SELECT country,year,production,lag(production)OVER(PARTITION BY country ORDER BY year)AS different _ oil WHERE country IN(' Canada ',' Mexico ')AND year % 3C 1970;国家|年份|产量| diff - + - + - + -加拿大| 1965 | 920 |加拿大| 1966 | 1012 | 920加拿大| 1967 | 1106 | 1012加拿大| 1968 | 1194 | 1106加拿大| 1969 | 1306 | 1194墨西哥| 1965 | 362 |墨西哥| 1966 | 370 | 362墨西哥| 1967 | 411 | 3772</font>
在本例中,每个组都包含一个空值,因为没有“上一个”值。这证明了PostgreSQL单独处理组。
使用滑动窗口
许多人感兴趣的另一件事是计算移动平均线的必要性。我决定在这篇文章中加入这个关于差异的例子,因为这个问题经常出现,值得更多关注。在许多情况下,这种类型的操作是在应用程序级别上计算的,由于性能原因,这显然是不合适的:
<font style="text-align: inherit;">cypex=# SELECT country,year,production,avg(production)OVER(ORDER BY year row FROM 2 previous AND 2 FOLLOWING)AS mov FROM t _ oil WHERE country IN(' Saudi Arabien ')AND year FROM 1975 AND 1990;国家|年份|产量| mov - + - + - + -沙特阿拉伯语| 1975 | 7216 | 8465.66666666667沙特阿拉伯语| 1976 | 8762 | 8487.7500000000000000沙特阿拉伯语| 1977 | 9419 | 8758.00000000000沙特阿拉伯语| 1977 1983 | 4951 | 6060.600000000000000000沙特阿拉伯人| 1984 | 4534 | 5051.00000000000000沙特阿拉伯人| 1985 | 3601 | 4578.60000000000000000沙特阿拉伯人| 1986 | 5208 | 4732.000000000000004</font>
在SQL中,您可以使用…前和…后之间的行。它定义了进入聚合函数的行数(在我们的例子中是“avg”)。移动平均线的概念是将曲线变平,创造一条更平滑的线。下图显示了这是如何工作的:
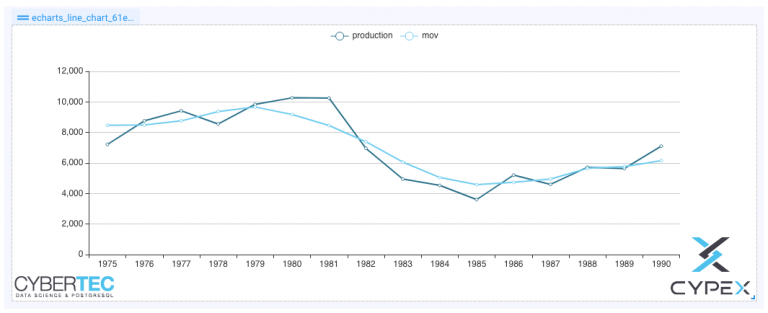
正如你在CYPEX可视化移动平均线比潜在数据的比率平滑得多。沙特阿拉伯是所谓的“摇摆生产国”。视政治形势而定,生产率可能会有很大差异,因此使用移动平均线实际上很有意义。
复合类型和行比较
然而,还有更多:你们中的一些人可能知道PostgreSQL支持复合数据类型。基本上,每一行都可以看作是包含各种组件的单个元素。通常,SELECT子句列出所有需要的字段,但是您也可以将一个表视为一个字段,如下例所示:
<font style="text-align: inherit;">cypex=# SELECT t_oil,lag(t_oil) OVER(按年份排序)FROM t _ oil WHERE country = ' Mexico ' AND year IN(1980,1981);t_oil | lag - + -(“北美”,墨西哥,1980,2129,1048) |(“北美”,墨西哥,1981,2553,1172) |(“北美”,墨西哥,1980,2129,1048)(2行)</font>
在这种情况下,一行的所有列都打包到一个字段中。你可以正常使用“滞后”功能…
现在的诀窍是:你可以用“=”来直接比较两行。为什么这很重要?有时您想知道两行是否被导入了两次,或者您只是想知道两个连续的行是否相同。它是这样工作的:
<font style="text-align: inherit;">cypex=# SELECT t_oil =来自t_oil的滞后(t_oil)时间(按年份排序)国家= '墨西哥'和年份(1980,1981);?专栏?- f(2行)</font>
可以将整行相互比较。PostgreSQL将一个接一个地检查一个字段,并且只有在所有字段都相同的情况下才会发出true。换句话说,“滞后”甚至可以被滥用来检测重复的行。
