




整理了以下几点内容:
了解一下B+树
分析InnoDB索引模型
索引维护(页分裂&页合并)
主键设计的重要性
唯一索引中如果有null值,还能保证数据唯一吗?
理解最左前缀原则,避免创建冗余索引
B+树(有序数组链表+平衡多叉树)
B+树的存储方式:
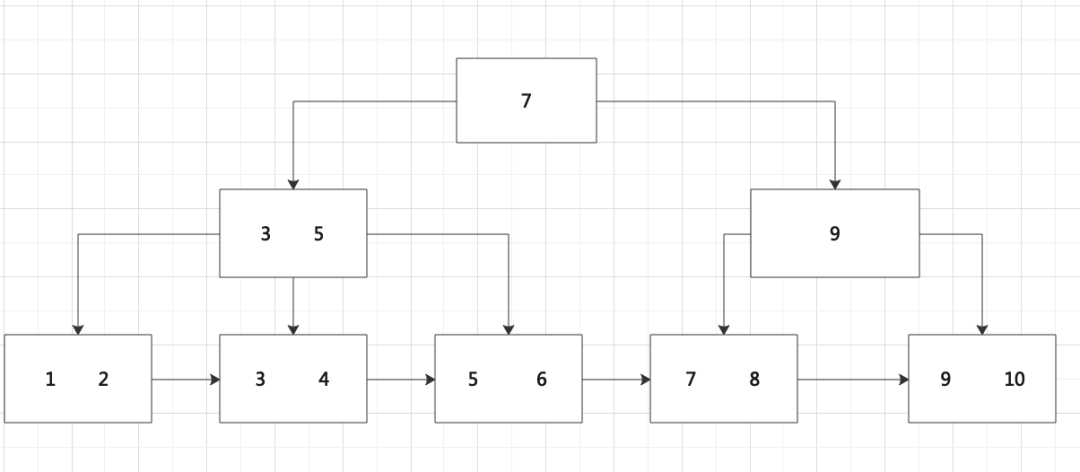
下面这个链接是usfca大学的一个算法网站,能让我们直观的理解B+树是怎么玩的~
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
InnoDB索引模型
create table T(
id INT PRIMARY KEY,
k INT NOT NULL,
name VARCHAR(16),
key(k)) engine = InnoDB;
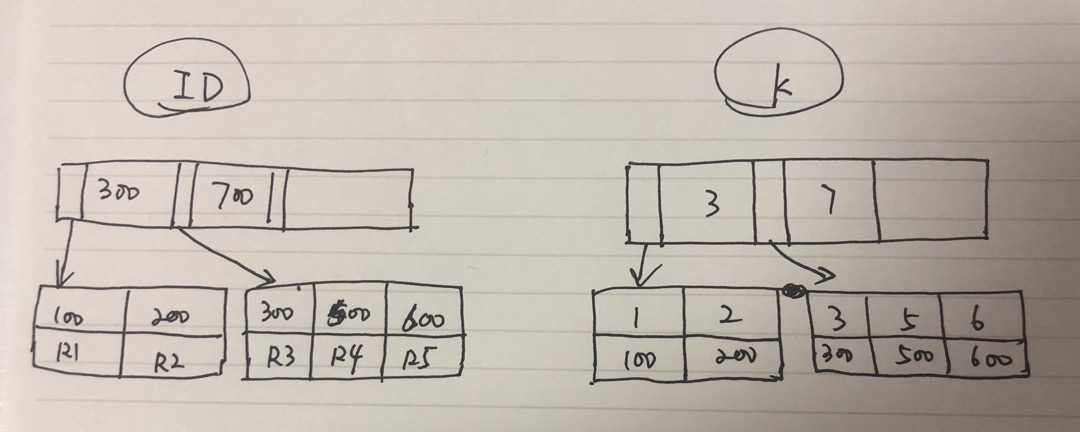
电脑上的工具实在不怎么好用,只能将就着看吧。。。
从上图中能看到,根据叶子节点的内容,索引类型可分为主键索引和非主键索引。
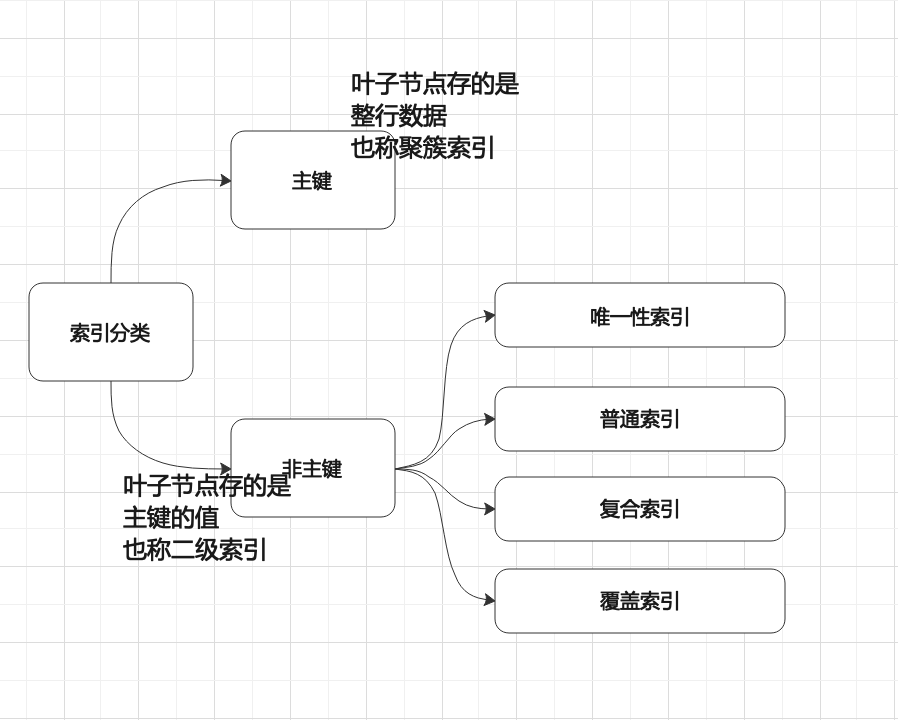
普通索引和唯一索引就不多说了,看下覆盖索引和复合索引的特点。
覆盖索引:
如果查询条件使用的是普通索引(或是复合索引的最左原则字段),查询结果是复合索引的字段或是主键,那么不用做回表操作,直接返回结果,减少磁盘IO读写,能较大的提升查询性能。
复合索引:
根据创建复合索引的顺序,以最左原则进行where检索。
比如复合索引idx_ab(a,b),那么where a=1 和 where a=1 and b=2 都能使用索引idx_ab,但是单独使用where b=2作为条件查询时,不能使用索引idx_ab(a,b)。
所以,在创建复合索引时,一定要考虑列的顺序。
第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。第二个原则就是,尽可能节省空间。
基于主键索引和普通索引的查询有什么区别?
索引维护
B+树为了维护索引有序性,在插入新值的时候需要做必要的维护。以上面的索引树图为例,如果插入新的ID为700,则只需在R5的记录后面插入一个新记录。如果新插入的ID值为400,就需要逻辑上挪动后面的数据,空出位置。
而更糟糕的情况是,如果R5所在的数据页数据页已经满了,根据B+树的算法,需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。(页分裂会发生在插入或更新,并且造成页的错位)在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约50%。
InnoDB用INFORMATION_SCHEMA下的INNODB_METRICS表来跟踪页的分裂数。可以查看其中的index_page_splits 和index_page_reorg_attempts, index_page_reorg_successful统计。
mysql> selectname,subsystem,status,comment from information_schema.INNODB_METRICS where name like '%index_page%';
参考文章:
https://www.percona.com/blog/2017/04/10/innodb-page-merging-and-page-splitting/
主键设计的重要性
只有一个索引;
该索引必须是唯一索引。
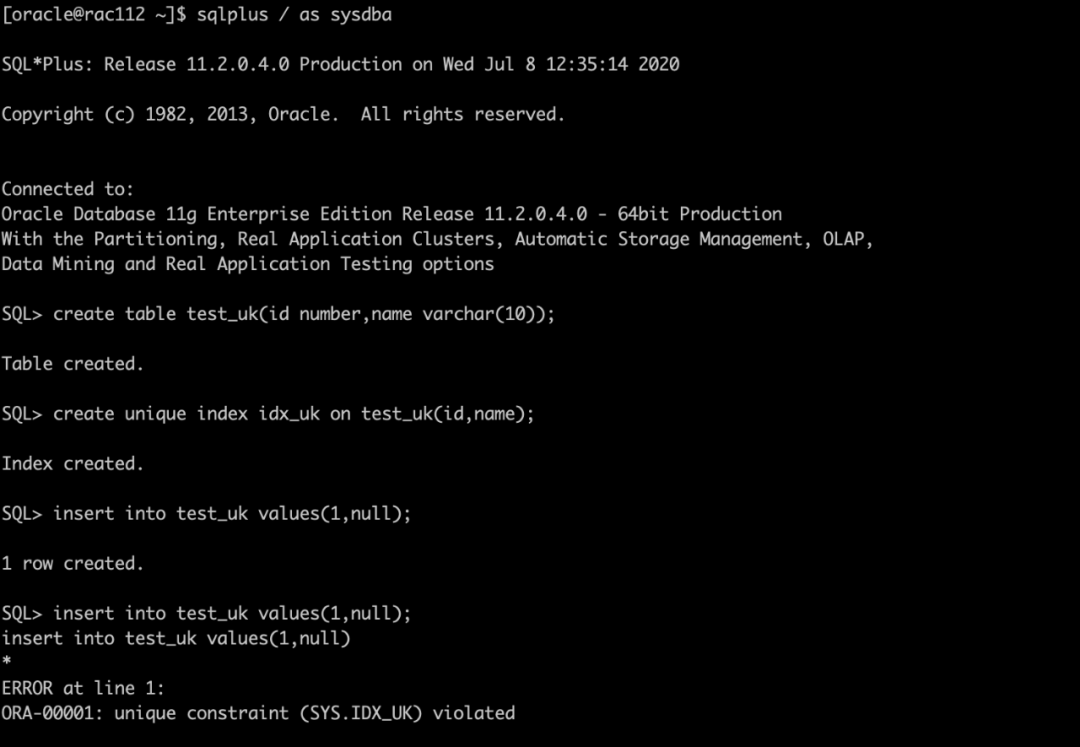
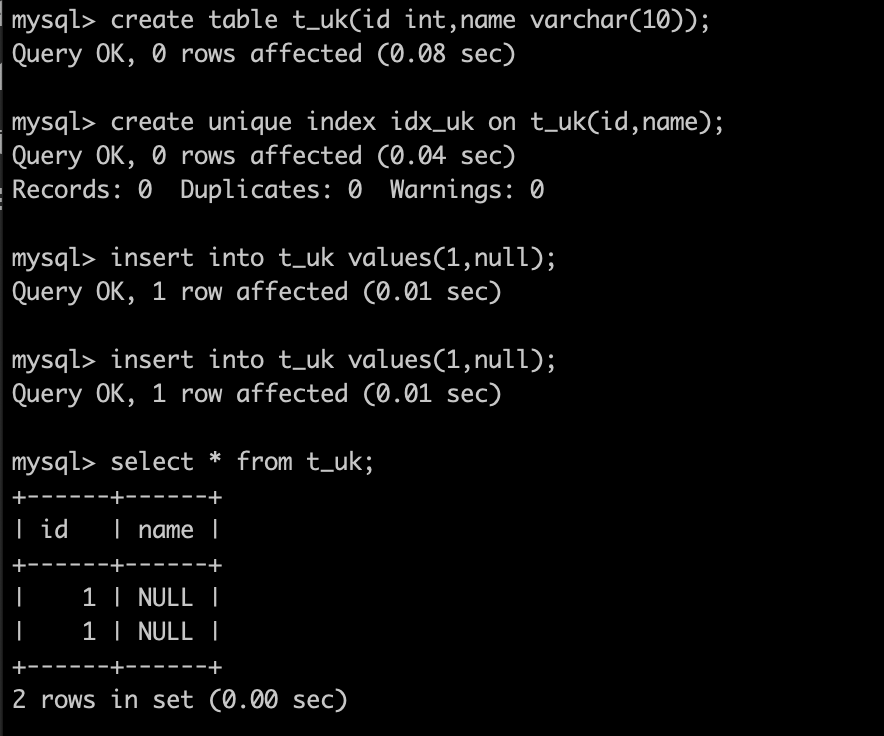
唯一索引中如果有null值,还能保证数据唯一吗?
答案是,不能。
在Oracle中,如果联合uk(a,b),当插入(1,null),(1,null)时会报唯一性错误。
理解最左前缀原则,避免创建冗余索引
这段拿出来单独写,主要是因为,经常看到研发提供的建表语句中有类似这种写法:idx_1(a),idx_2(a,b),idx_3(a,b,c)。每次都要和他们解释一遍,我不知道他们到底是怎么想的?
B+ 树这种索引结构,可以利用索引的“最左前缀”,来定位记录。不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。所以,千万别再建这种重复的索引了。索引越少越好,维护每个索引都是需要成本的,在修改数据时,每个索引都要进行更新,会降低写入的速度。
END;
今天下班前,自称公众号老手的同事,指导我这个公众号新人说,文章不能写的太长。。所以,还有一些内容(比如,为什么不建议开发使用唯一索引?),我就放到下一篇吧。(我真的不是偷懒。。)
