




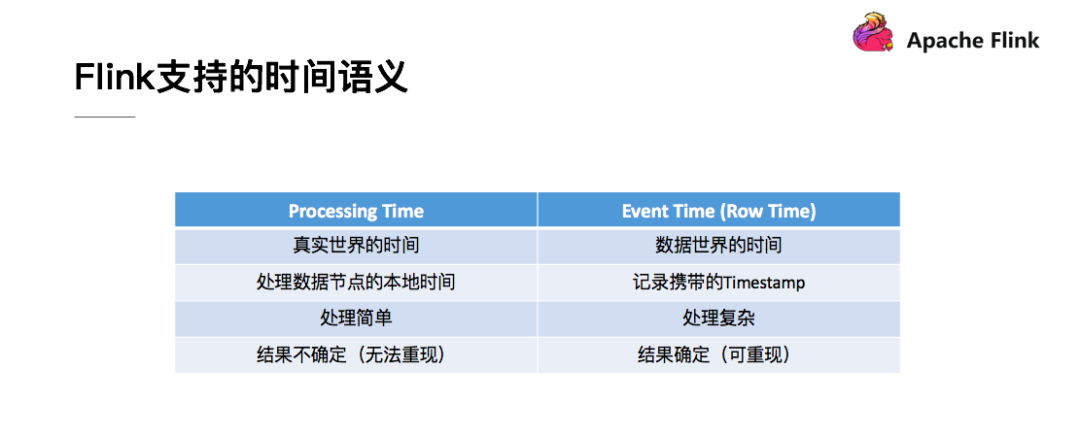
Processing Time: 机器或者系统的时间,可理解为真实世界的时间。使用该时间模式有最好的性能和最低的延迟。
Event time: 数据上自带的时间,可理解为数据世界的时间。实际场景中应用较多,由于数据在传输过程有网络、I/O以及消费等因素,往往不能保证数据按顺序到达,因此导致了时间的乱序等问题。
Ingestion time: 数据进入程序时的时间,比如12点的一条数据与11点的一条数据同时进入程序,这两者会被认为是同一时间的数据。与事件时间相比,摄入时间程序不能处理任何无序事件或者延迟事件,但是程序无需指定如何产生水印。
PS:对时间的理解,时间并不一定就一定是时间,只要数据是有序递增的,都可以理解为时间来进行处理。

在实际业务场景中的实时计算,往往都是使用的数据时间EventTime,这样才能保证数据的真实性和准确性。但是数据在传输过程有网络、I/O以及消费等因素,数据的时间可能会存在一定程度的乱序。
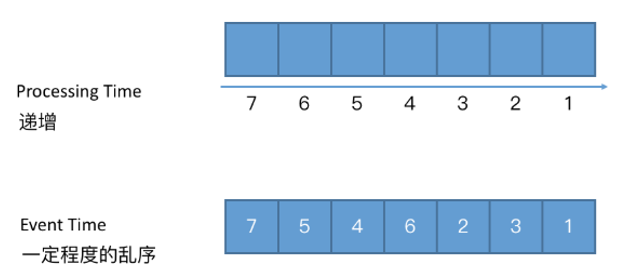
需要考虑对于整个序列进行更大程度离散化。把数据按照一定的条数组成一些小批次,但这里的小批次并不是攒够多少条就要去处理,而是为了对他们进行时间上的划分。
经过这种更高层次的离散化之后,我们会发现最右边方框里的时间就是一定会小于中间方框里的时间,中间框里的时间也一定会小于最左边方框里的时间。
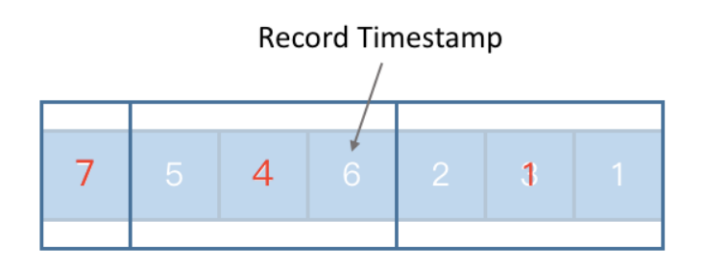
这个时候我们在整个时间序列里插入一些类似于标志位的一些特殊的处理数据,这些特殊的处理数据叫做watermark。一个watermark 本质上就代表了这个watermark 所包含的timestamp数值,表示以后到来的数据已经再也没有小于或等于这个时间的了。
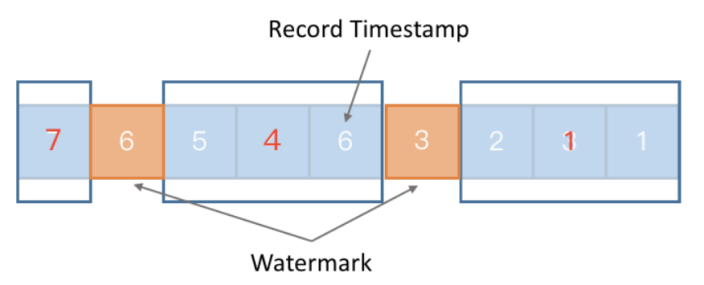
watermark 会以广播的形式在算子之间进行传播,下游所有算子共享watermark。
如果在程序里面收到了一个 Long.MAX_VALUE 这个数值的 watermark,就表示对应的那一条流的一个部分不会再有数据发过来了,它相当于就是一个终止的一个标志。
对于单流而言,会选择当前最大的值timestamp作为watermark。对于多流而言,会选择流中最小的watermark作为整个任务的watermark。即可看做一个由多个木块组成的装水的木桶,桶里面水多高取决于组成桶的那个最低的木块。
Watermaker的生成有两类。第一类是定期生成器,默认50ms向下游发送一次;第二类是根据一些在流处理数据流中遇到的一些特殊记录生成的,来一条数据获取一次,发送一次。生产中的使用可根据业务考虑使用何种,已达到性能和业务的平衡。
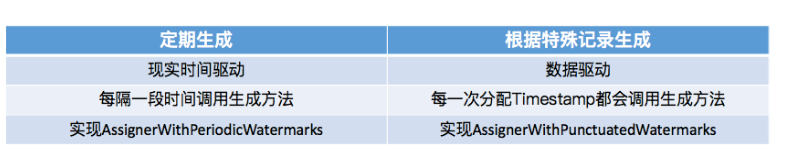
关于数据的延迟乱序,生成Watermaker时是可以直接增加一个特定延迟时间的。这样做的好处是,在水位到达时,仍然可以再等待一个延迟保证晚到的数据进行统计,保证数据的准确性,当然这样也使得数据实时性延迟,是保证实时性还是准确性,需要生成进行取舍,或者两种之间采用一个平衡值。具体的延迟时长,需要观察实际数据的延迟等进行判断及定义。
场景:
数据源一分钟产生一条数据,每条数据中有9条左右的不同key的子数据,程序进行Keyby处理后,开启一分钟的窗口进行汇总统计数量。
问题:
程序启动4个并行进行处理,结果几分钟后都没触发汇总。什么原因?
原因:通过前台对flink任务的监控发现,4个并行后由于数据量太少,有一个并行没有收到数据,因此没有产生Watermaker,由Watermaker的特性的第三条可以理解,整个程序目前的watermarker取的是第4个并行的watermarker初始值Long.MIN_VALUE,所以导致整个程序没有进行触发汇总。
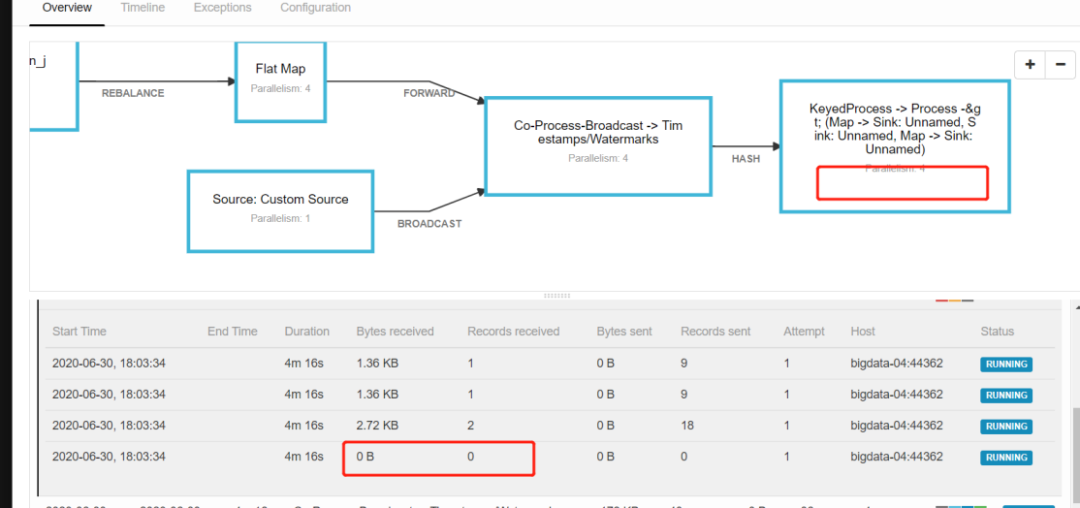
不改并行的情况下,需要对程序Watermaker生成之前进行数据负载均衡,最简单直接的办法是进行一次keyby处理。
数据量较少的情况,直接改小并行度。
两种方法的目的都是保证每个并行都能消费到实时数据,这里我们采用第一个方案进行修改验证,结果如图时间小于1593572813000的数据都会及时进行汇总生成指标。
实际生产中关于数据负载均衡的问题往往也是需要注意的,往往数据的倾斜问题,如果比较严重会导致数据计算的准确性以及整个任务的性能等一系列问题,关于数据倾斜问题这里不进行深入探讨,下期有机会给大家做进一步的分享。

场景:业务链实时指标计算延迟。
原因:重复注册Watermaker导致任务吞吐量变低,影响计算效率。
如何解决:
业务链处理经过算子处理之后m条数据会生成m*n条数据,然后进行keyby汇总。之前水位注册在汇总数据之前,因此需要对m*n条数据都进行水位注册,使得同一时间多次水位处理,程序效率也下来了,整个任务吞吐量变低。利用水位广播传递的特点,将水位注册放到数据源,只需要对m条数据进行注册,处理逻辑直接少了n倍,整个任务吞吐量也随之上来了
建议生成Watermaker的工作越靠近DataSource越好。这样会方便让程序逻辑里面更多的operator去判断某些数据是否乱序。Flink内部提供了很好的机制去保证这些timestamp和watermark被正确地传递到下游的节点。
今天分享到此结束,后头见。
