




近期某省渠道应用的签到送流量业务出现了严重的业务超时情况,与此同时该渠道Tuxedo中间件的维护人员在该活动的业务高峰期,也接收到了大量涉及业务办理服务的积压告警短信。
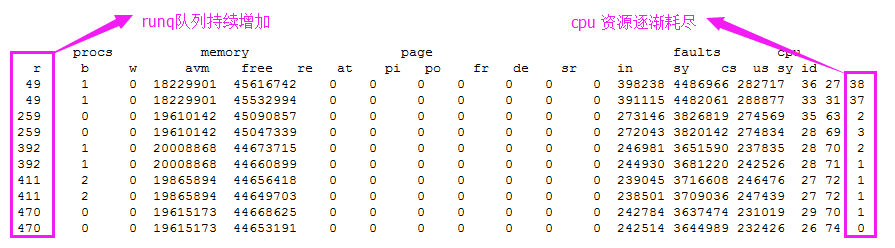
通过对积压的Tuxedo服务执行效率进行统计,发现该服务在业务高峰期时单笔调用的服务执行总耗时已经达到13.4732s。
中间件维护人员在对该服务进行实时truss过程中,未发现明显的执行过程等待现象,但经过对该服务单笔调用记录的数据进行分析和统计后,发现在一次调用过程中,该服务对数据库读、写的次数累计已经超过了14000次。
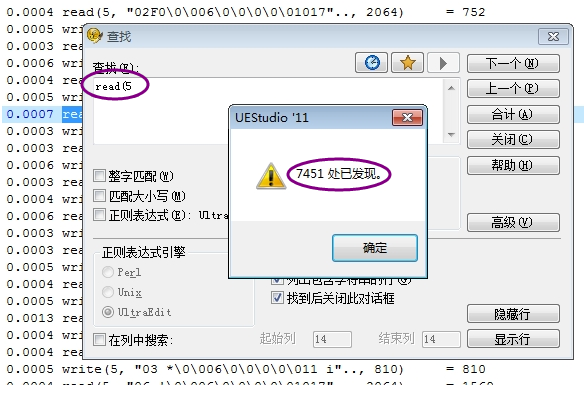
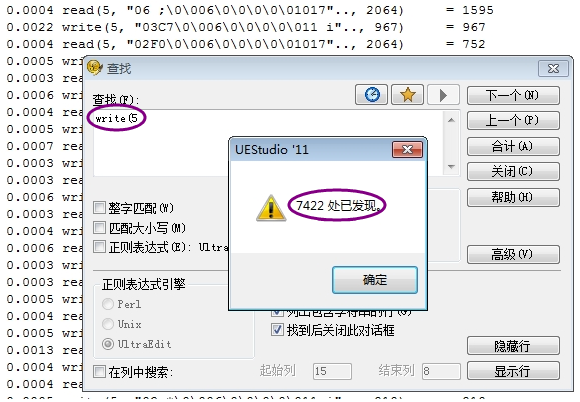
同时在truss过程中,我们发现每次的read5,write5对象分别为读、写CRM库。
于是马上接入CRM库进行分析,跟踪积压服务在数据库执行情况。通过剖析主要发现该服务发起的session存在大量的librarycache: mutex X争用,且都在特定的sql上(sql_id:afqzw543rcu2d)。

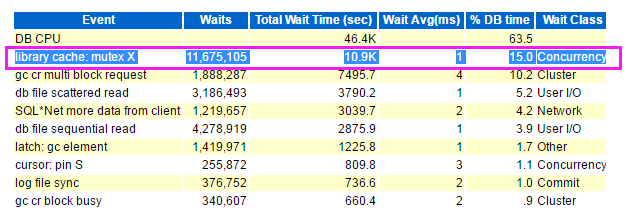
另外该sql在30min内累计执行3.8kw次,与此同时主机Runq队列高居不下,Cpu资源耗尽。

通过剖析该sql,发现该sql主要是利用dual表进行date转换。

由此可发现,本次服务积压主要与此sql有关,但该服务模块上线较早,且近期没有新的变更,那么此次的问题是否和sql调用量增加有关系?
带着此疑问,我们对此sql的调用量做了对比分析。
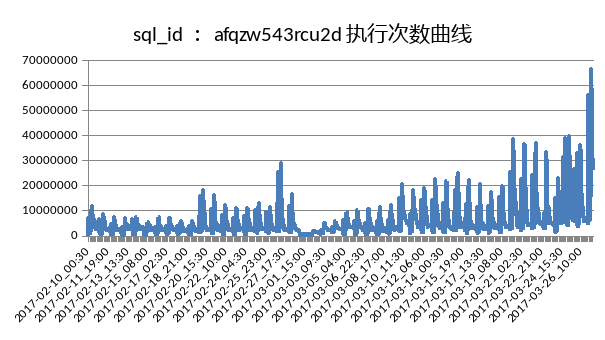
分析发现2月11日6点到9点30分总执行次数只有5000万次左右,3月20日6点到9点30分总共执行了1.1亿次,3月27日,6点到9点30分,总共执行了4.01亿次,差不多增长了4倍。所以从数据上分析,该SQL的执行次数是一个不断增长的趋势;
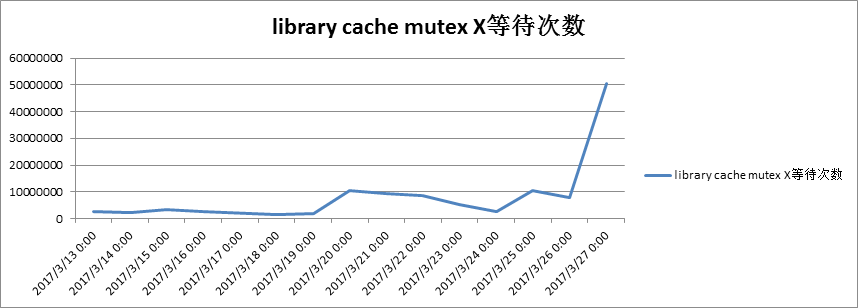
同时发现,随着问题sql执行次数的增加,librarycache: mutex X等待次数也跟着同比增加,进而使得主机Runq队列剧增,Cpu资源耗尽。
那么要解决该问题,就要控制该sql执行频率。通过同应用侧沟通,最终通过修改业务逻辑,在数据库中屏蔽该sql。
优化后对服务调用量及平均响应时长进行了监控和数据搜集。

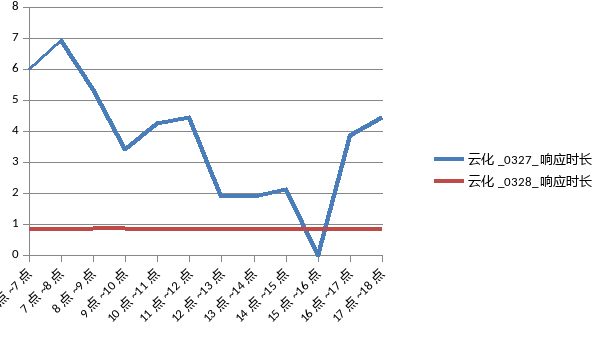
对比发现,优化后服务执行效率提升显著,且稳定,无服务队列积压情况出现。下图为上线前后服务执行效率对比曲线图:
此案例中我们发现在应用代码中使用selectxxx from dual, 该SQL虽然简单,且单次执行性能优良,但如高频率的执行,则会有资源高消耗的隐患。
因此建议避免在数据库内部进行与数据库无关的处理;且日期以及字符串等相关处理各种程序语言(C、Java)都提供了丰富的函数库可使用,本地化处理不仅可以避免与数据库的交互,更可以降低数据库的负载,提高服务性能。
独坐思往昔,愁绝泪盈襟。下回见。
