




从Oracle数据库官方服务支持生命周期表我们可以清晰看到Oracle11g已过主支持生命周期,2020年后不再支持,取而代之的是12C及以上版本。
基于这个背景,大部分的客户开始了新一轮的数据库升级,下文主要剖析一个和升级相关的Case,希望对大家有帮助。
某客户系统基于版本迭代要求,需要将某核心数据库Oracle11.2.0.3升级至Oracle19.5版本,该系统业务数2.5TB,对于运营商系统来说,这体量的数据量是小儿科,凭借老司机的第一感觉割接应该没啥问题。
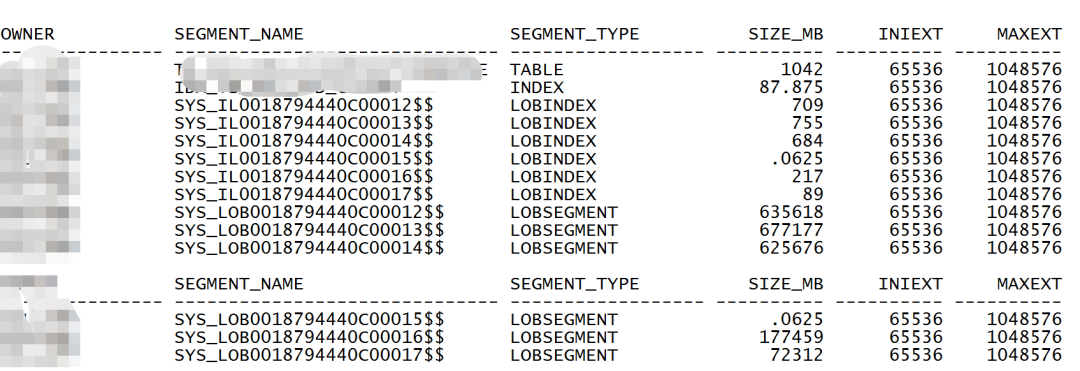
但是查看后发现有个单表2TB,仔细再查2TB基本全是lob,且不是分区表,这个问题就有点棘手了。搞的小哥我有点出汗的感脚了。
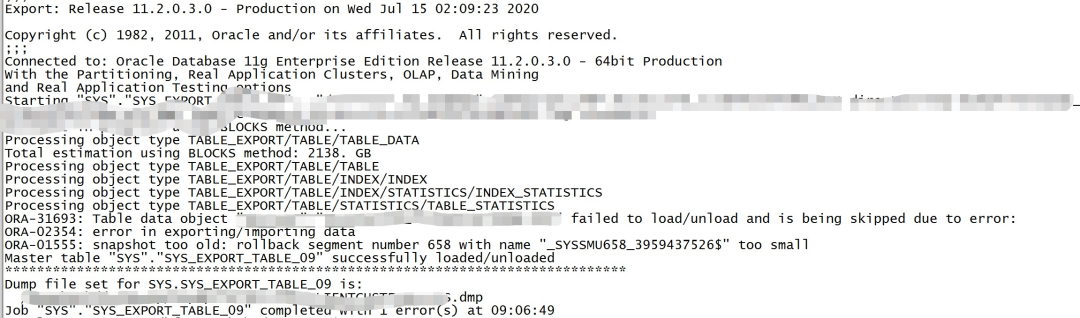
针对这种大容量的lob表,使用以往常规导出的方式,毫无悬念的报Ora-01555。
作为身经百战的割接小王子,见到挑战我就兴奋,接着出汗。经过自我风暴后,决定用Expdp的Query试一试,但是2TB的数据量的单表lob还是第一次,那么根据哪个条件进行Query导出呢?
首先需考虑到是根据有索引列进行导出,这样的效率会比较高。确认后,问题又来了,索引列不满足均匀分批条件,故这个思路走不通了。
要怎样才能均分呢,继续自我风暴中,要均分,Rowid行不行?Oracle提供了rowid这个概念。那就来看看怎么使用rowid进行导出的。
首先Rowid是用于定位数据库中一条记录的一个相对唯一地址值。通常情况下,该值在该行数据插入到数据库表时即被确定且唯一。Rowid它是一个伪列,它并不实际存在于实体表中。
它是Oracle在读取表中数据行时,根据每一行数据的物理地址信息编码而成的一个伪列。所以根据一行数据的Rowid能找到一行数据的物理地址信息。从而快速地定位到数据行,而且使用Rowid来进行单记录定位速度是最快的。

上图是Rowid的结构图,主要包含4个部分:
第一部分6位表示:该行数据所在的数据对象的Data_object_id
第二部分3位表示:该行数据所在的相对数据文件的id
第三部分6位表示:该数据行所在的数据块的编号
第四部分3位表示:该行数据的行的编号

虽然我们从Rowid伪列中Select出来的Rowid是以base64字符显示的,但在Oracle内部存储的时候还是以原值的二进制表示的。
一个扩展Rowid采用10个byte来存储,共80bit,其中obj#32bit,rfile#10bit,block#22bit,row#16bit。所以相对文件号不能超过1023,也就是一个表空间的数据文件不能超过1023个(不存在文件号为0的文件),一个Datafile只能有2^22=4M个 block,一个block中不能超过2^16=64K行数据的由来。
了解了Rowid后,怎么进行均匀分批呢?答案是利用Oracle提供的DBMS_ROWID 包。
导出脚本如下:

参数说明:
Content=DATA_ONLY
只导出表中的数据,导出会更快,导入时也更快,index之类的对象在data导入后单独处理;
COMPRESSION=DATA_ONLY
数据量太大,节省空间,传输到新环境时效更高
Query=“……”
将表数据根据条件进行分批,在一个scn内导出全部数据
为啥选用rowid_block_number呢?因为导出这个大表的需求下,Object_id就一个,分不了批次,Fileid只有150个,BLOCK_ID 是126924个,ROW_NUMBER是19,数据量数值进行Mod取余分批的差异就越小,所以使用rowid_block_number。使用这个方法后还是很顺利的导出了数据。
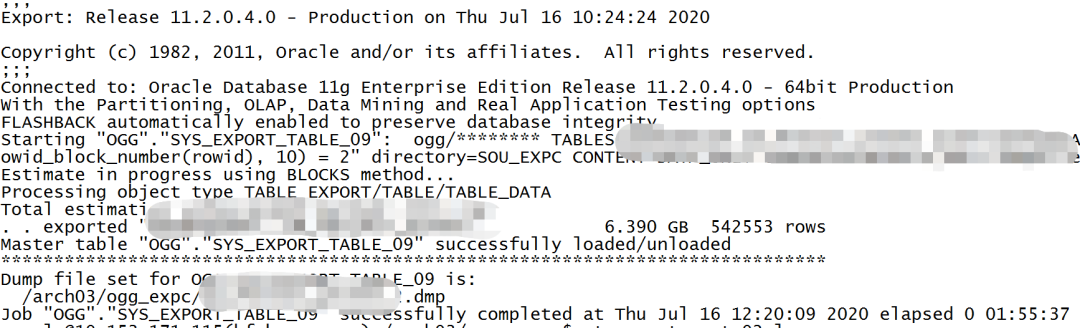
查看全部导出日志,每个批次耗时相差不大,满足均匀分批导出的计划。

总结,遇到超大lob表导数需求后的三板斧:
A.查看是否是分区表,分区表的话按分区导出;
catexp_owner_table_seq.par
userid='/assysdba'
directory=DMP
dumpfile=exp_owner_table_seq.dmp
logfile=exp_owner_table_seq.log
CONTENT=DATA_ONLY
COMPRESSION=DATA_ONLY
tables=(
onwer.tbale_name:part_name
)
B.业务沟通,是否存在均匀分布的字段值,按照字段值分批导出;
catexp_owner_table_seq.par
USERID='/as sysdba'
directory= DMP
CONTENT=DATA_ONLY
COMPRESSION=DATA_ONLY
dumpfile=exp_owner_table_seq.dmp
logfile=exp_owner_table_seq.log
tables=owner.table_name
QUERY="WHEREcolumn_name like 'XXXX%'
C.不满足以上的都可以使用本文rowid方式进行导出。
catexp_owner_table_seq.par
USERID='/as sysdba'
directory= DMP
CONTENT=DATA_ONLY
COMPRESSION=DATA_ONLY
dumpfile=exp_owner_table_seq.dmp
logfile=exp_owner_table_seq.log
tables=owner.table_name
QUERY="wheremod(dbms_rowid.rowid_block_number(rowid),10)=1"
以上是本小王子实际工作中遇到的2TB数据量lob的处理过程,希望对大家有启发借鉴的作用和意义,后续割接迁移中遇到好玩儿的事情,我再来和大家分享。我们后会有期。
